
2019年に登場する予定の第3世代のAMD Ryzen「Zen 2」は、今までのRyzenの弱点を根本的に解決する数々の設計改良が加えられ、見ているだけで痺れてくる。…というわけで、Ryzenの弱点が存在する設計上の背景から、Zen 2でどのように弱点が解決されるのか。分かりやすく解説します。
「Zen 2」の設計を図解:今までのRyzenと何が違う?
従来の「Zen」設計を図解でおさらい
まずは基本中の基本である「Ryzenの設計」について、ザックリと説明します。「Ryzen」はコア数が多いにも関わらず、価格が非常に安くてコスパに優れているため、自作PCを中心に浸透してインテルを脅かす存在になった。
Ryzenが初めて市場に登場した当時、8コアCPUは10万円くらい出さないと購入できないエンスージアスト向けのハイエンドCPUでした。そこにAMDはわずか3.5~4万円で8コアを投入したのです。
しかも実際の性能もちゃんと8コアらしい強力なモノで、停滞気味だったCPU業界を一気に沸かせた。もちろん、原価ギリギリで売っているわけではなく、安価に8コアを作れる合理的な設計こそが「Zen」の強みでした。
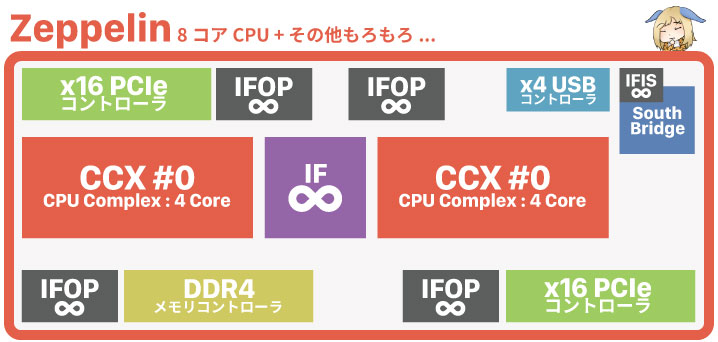
その設計の基本が「Zeppelin」と呼ばれるチップです。Zeppelinの中には「CCX」と呼ばれる4コアCPUが2個入っていて、その他にZeppelin同士を接続する「IFOP」や、グラボやメモリと通信するためのコントローラなどが内蔵されています。
基本的にCPUはコア数が多いチップほど、チップの面積が巨大化して作るのに必要なコストがどんどん増えていく(=歩留まり率の悪化)。だからAMDは「Zeppelin」と言う安価に製造できる8コアのチップを「最小単位」として製造。

- Ryzen:「Zeppelin」を1個で4~8コアを実現
- Ryzen Threadripper:「Zeppelin」を2個で8~16コアを実現
- AMD EPYC:「Zeppelin」を4個で8コア~32コアを実現
あとは最小単位であるZeppelinを組み合わせることで、コア数を倍々ゲームのようにカンタンに増やせるという設計です。最小単位より大きいチップは製造しないので、結果的にコストを抑えられるという狙いになる。
だからRyzenはコア数の割に安い。8コアなら約4万円、16コアは9万円くらい。インテルの同じコア数なら、8コアが6.5万円で、16コアは18万円も掛かる。ほぼ半額ですね。


多コア化に合理的な「Zen」の弱点
Zeppelinという最小単位を複数使って、安価に多コアCPUを作ることができるのが「Zen」の強みでしたが、複数のZeppelinを接続する時に使う「IFOP」が原因で、いろいろな弱点が生まれてしまった。
IFOP = Zepplelin同士を接続するパイプ
「IFOP」はInfinity Fabric On-Packageの略称で、機能はZenの最小単位であるZeppelin同士を、相互通信できるように接続して「多コア化」を実現するためのパイプのようなモノ…と思ってください。

たとえば、16コア搭載のRyzen Threadripperを作る場合は、最小単位のZeppelinを2個使う。IFOPを2本使って、2つのZeppelinを接続して、カンタンに16コアCPUが完成するというわけ。
しかし、これは「8コアCPUを2個使っている状態」に近い。
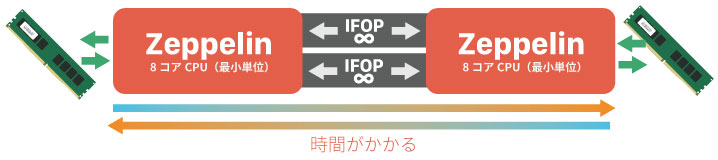
そのため、何らかの処理を行う場合、ソフトからメモリ、そしてCPUへとデータの転送が行われるわけですが、Zeppelinの間をまたいで転送すると時間が掛かります。つまり遅延が発生しやすい。
この遅延が存在するために、最適化が乏しいという弱点を抱えることになってしまった。最近は少しずつマシにはなってきたが、Adobe全般は未だに最適化されていないなど、大手ほど重い腰を上げない傾向がある。
あとは動画エンコード系も、同じコア数で速度を競うとインテルの方が速いことが多い。筆者の知る範囲では、Aviutlが唯一Ryzenに最適化されているけれど、Adobe PremiereやHandbrakeなどの有名所はおおむねダメです。
IF = あらゆるデータが必ず通るパイプ
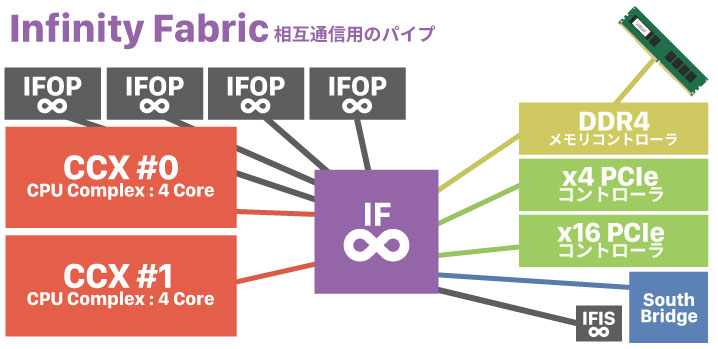
先のIFOPは、Zeppelinチップを相互接続するためのパイプでした。次はZeppelinの内部に埋め込まれている「インフィニティーファブリック」についても、解説しておく。
このインフィニティーファブリックは別名「スケーラブルな制御網」(Scalable Control Fabric)と呼ばれており、その名の通り、Zeppelin内部の各種コンポーネントを相互接続するためのパイプとして機能する。
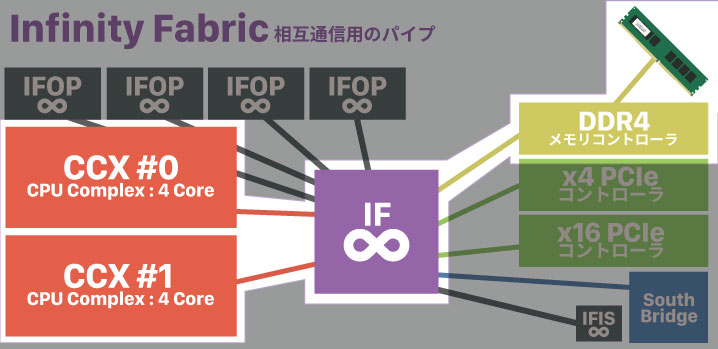
つまり、何かの処理をする時。ソフトウェアからメモリーに送られたデータは、Zeppelinの中にあるメモリコントローラにやってきて、その後インフィニティーファブリックへ送られて「CCX」に到達するというわけ。
CCXで処理が済んだらデータは元の位置へ戻る。当然、来る時にパンくずを落としてあるので、その痕跡を追いかけて来た道を戻ることでメモリーに帰っていきます(ここのレイテンシはメモリークロックを同期することで解消している)。
ここで問題になるのが、CCXは2つあるということ。Zeppelinは見かけは8コアの単一CPUですが、内部的には更に小さい「CCX」と言う4コアCPUが2個入っている形式です。そして、2つのCCXコアと、他のコンポーネントをIFを使って相互接続している。
ここを説明している文献は少ないので、筆者の経験則も含んだ推測になるが、おそらく2つのCCXコアに上手く役割分担を行えるかどうかが割と重要なポイントなのかもしれない。
たとえば、Ryzen以前から存在していて既に更新が止まっている「Aviutl」(日本で大人気の動画編集ソフト)の場合、Ryzen環境ではなぜかプレビューが安定して動作しないという不具合に遭遇しています。
多少カクつくだけなら許容できるが、レイヤーを重ねていればいるほど動作がひどくなり、割とクラッシュする。もちろん、原因の調査を行いました。すると面白い事実が発覚した。
インテルCPUだと当然スムーズに動く。次に、Ryzen 5やRyzen 7ではダメ。そして「Ryzen APU」だと割と普通に動いてくれる。Ryzen APUにはCCXが1個しか入っていません。
このことから、CCXが2個入っているという構造が古いソフトにとっては結構厄介なんだろうな…と。大手のソフトでも未だに最適化されていないことは珍しくないので、意外と面倒くさいのかもしれない。
「Zen 2」はZenの弱点を解決し、更に多コア化
ここまでの解説で、現時点の「Zen」は安価に多コア化に成功はしてインテルを脅かしたが、構造上の弱点によりインテルに対して「最適化」が大きく劣っている現状があることが分かったと思います。
では、設計が刷新される「Zen 2」ではどのように弱点が克服されるのか。図解していく。
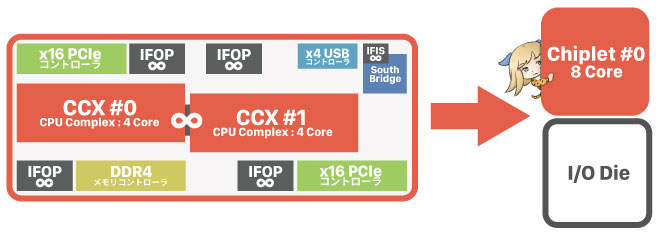
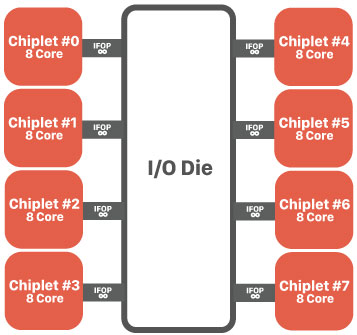
「Zen」の最小単位は「4コアCPU x2個 + その他もろもろ」で構成されるZeppelinチップでした。一方「Zen 2」の最小単位はChipletチップに置き換わり、その他もろもろの部分はI/O Dieに分割されます。
要するに、今までCPU部分とIFOPなどの接続バス(パイプ)や各種コントローラはすべて同じチップに詰め込まれていたわけですが、Zen 2では2つに分けてしまったのです。
今のところChipletの中身はよく分かっていないが、AMDが公表したZen 2世代のサーバー向けCPU「EPYC」(コードネームはRome)のイラストから、ざっくりと推測できる。
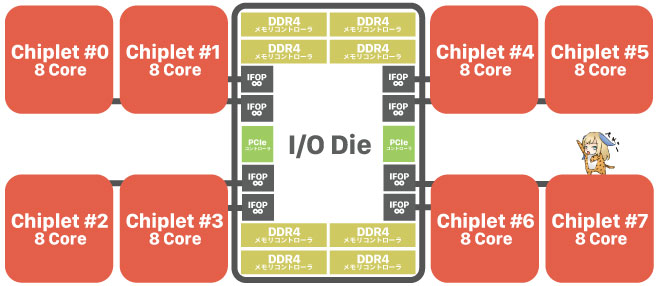
64コア / 128スレッド搭載の、Zen 2世代のEPYCです。一部詳細は伏せられたまま公開されたため、I/O Dieの中身は確定ではありません。
個々のChipletたちとI/O Dieを接続するためにZenと同様「IFOP」(インフィニティーファブリック)を使うのはほぼ確定。4コアのCCXはなんと2倍の8コア化が実現される見込み。
つまり、今まで実質的2つのCPUで8コアを実現していたモノが、Zen 2からは1つのCPUで8コアになる。これにより、CCXが2つ存在することに由来する問題が解消される可能性が出てくるというわけ。
だって、最小単位がちゃんとした8コアになるということは、従来のRyzen APUと同じような構造でも8コアCPUが作れるということ。最小単位の純粋な8コア化は、汎用性を大きく改善する可能性を秘めている。

64コア搭載「EPYC」のサンプルを掲げるLisa Su氏(AMD Next Horizonより)
AVX演算機が1つになり、エンコードの遅さも解消
Zen 2はCCXが1つに統合されたことで汎用性を大幅に改善できる。これだけでも結構大きな進化なわけですが、加えてエンコードが遅くなる原因だった「AVX演算機」の実装方法も変更される。

Zenは128 bit幅の演算機(レジスタ)を2つ使って、256 bit幅で計算ができる命令セット「AVX 2」を実現していました。しかし、演算機(レジスタ)を2つ使うと、ボトルネックが発生してインテルほど速くエンコード出来ない傾向が強かった。

AviutlならRyzenでもマトモに速度が出る(参考)
もちろん、この構造を考慮してプログラムされたエンコーダなら、Ryzenの持つ本来の性能のままにエンコードできる。例えば、Aviutlの拡張エンコーダである「x264guiEx」(rigaya氏)は、Ryzenに最適化されている数少ないエンコーダです。
だが、AdobeやHandbrakeといった有名所はなぜかエンコーダの改善を全く進めていないのが現状。
Zen 2ではこの構造的な問題を、演算機(レジスタ)を256 bit幅に強化することで解消する。128 bitを2個使って256 bitではなく、1個だけ使って256 bitを実現するのです。
ようやくインテルCPUとほぼ同じ実装方法になったため、恐らくエンコードが遅い問題は解消されると考えられる。OBSを使ったリアルタイム配信も、軽くなることが予想されますね。
ラインナップは最低8コアになるかも?
まだまだ確定事項ではないが、現時点の情報に基づくなら「CCXが8コア化」しているわけですから、同じラインナップのままコア数が2倍になる可能性が無くはない。
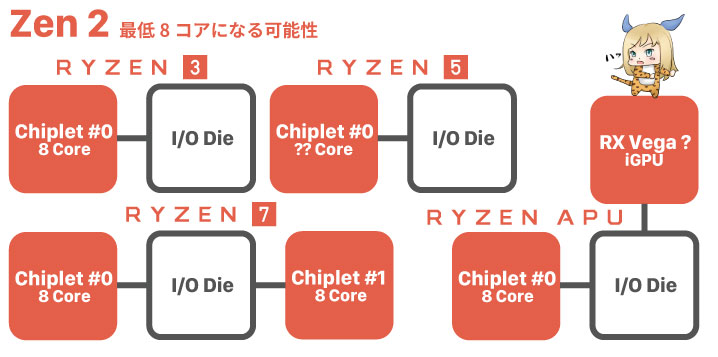
今のラインナップに、Zen 2の設計を直接当てはめるとこうなります。本当にこうなるかは不明。Zenで使われていたCCXを内部的に無効化する手法をZen 2でも使うなら、従来どおりのラインナップ展開も可能です。
Zen 2の最小単位「Chiplet」は7nmプロセスで製造されるため、質の悪いChipletが思った以上に出てしまった場合は、低品質なチップを4コアにしてRyzen 3へ…という流れも想定できる。
「Zen 2」は2019年のCPUとして「最大の目玉」

AMDが投資家向けのイベント「Next Horizon」で発表した資料を元に今回の記事を書いているため、まだまだ不透明な部分や正確性に欠ける部分も多い。
それでも、「Zen 2」のおおまかな設計が見えてきて非常に興奮してくるのが正直なところ。2つ内蔵されているCCXが統合された新しい最小単位「Chiplet」や、IOダイの分離による極めて自由度の高い設計思想。
128 bitだったAVX演算機(レジスタ)を256 bitに強化、TSMCの7nmプロセスを用いたCPUコアの製造など。本当に今の情報通りのモノが出てくるなら、期待せざるをえないです。
【補足】製造プロセスについて
「Zen 2」の製造はTSMC社の7nmプロセスを用いて行われる。従来の「Zen」「Zen+」は、GLOBALFOUNDRIES社の14nmプロセスが使われていた。
このため、Zen 2は同じ面積で計算上は4倍のトランジスタを詰め込むことが可能。にも関わらず、Next Horizenでは同じ面積で約2倍の密度と発表されています。
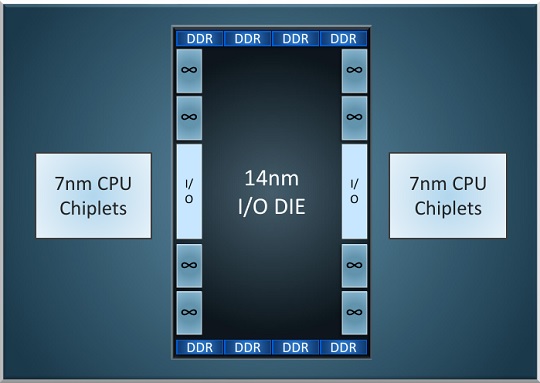
理由の一つとして、7nmプロセスで製造されるのはCPU部分である「Chiplet」だけで、分割された「I/Oダイ」は従来どおり14nmプロセスで製造されるためです。実はCPUより、その他もろもろの部分の方が微細化は難しい事情がある。
インテルが10nmプロセスにものすごく苦戦している原因も、その他もろもろの微細化が上手く行っていないためです。つまり、Zen 2は製造工程の違う完全に異種のチップが混在した設計になるわけですね(本当に面白い)。
なお、7nmプロセスだとインテルより更に先を行っているように見えるが、TSMCの7nmはインテルの10nmより難易度はやや低いので、圧倒的に先を行っているわけではありません。このあたりの話は以下の記事が詳しい。
「Zen 2」の設計まとめ
最後に、ここまで解説してきたZen 2の設計について、まとめて終わります。
「Zen 2」の改善ポイント
- 今まで4コアだったCCXが倍増(8コア化)
- 2個入っているCCXが、1個になる(かも)
- CPU部分は7nmプロセスで製造される
- 「AVX 2」を256 bit幅の演算機1個で実現する
- CPU部分とI/O部分(その他)を分離
7nmで製造されることで、消費電力を削減し、クロック周波数を更に高められる。AMDによれば、IPC(クロックあたりの処理回数)はZenと比較して29%も向上するという情報もあるので、シングルスレッド性能の大幅な進化はほぼ確実。
マルチスレッド性能も、コア数の倍増だけでなく、IOダイをCPUから切り離して分割することで「ダイ → 他のダイ」のレイテンシがバラバラになってしまう現象を解消するので今まで以上に効率が良くなる可能性が濃厚。
汎用性の向上はもちろん、Ryzenの弱点としてたびたび挙げられているゲーミング性能の低さも改善されるはずです。エンコードが遅い問題も構造的に解消されそうですし、Zenの欠点をほぼカバーしています。
「Zen 2」の懸念ポイント
CPUとIOを接続するIFOPの遅延の影響は?
懸念としては、IFOP(インフィニティーファブリック)由来の遅延くらいですね。CPUとIOダイを分離してしまったため、一般向けのRyzen 3 / 5 / 7でも、IFOPを使って接続する必要がある。
だからCCX間の遅延は無くなったけれど、今度はCPUとIO間の遅延が生まれてしまうわけです。この遅延が原因で、また最適化問題を引きずることになってしまうと、惜しい感じになる…。
レイテンシ(遅延)の足並みが完璧に揃わない問題は、IOダイの引き離しでほぼ解消するため、AMDの32コアがなぜかインテルの18コアにボロ負けするといった現象はかなり解決されるはず。
今までのZenで作られる16コア以上のCPU(=つまり、Zeppelinを2個以上使うCPU)では、別のZeppelinへアクセスしに行く時にレイテンシが発生し、4個になるとZeppelinの場所によってレイテンシに差異が生じてしまっていた。
実際のところ、同じ16コアのCPUでもインテルのCore i9シリーズの方が、汎用性に優れていてゲーミング性能も高い理由は、レイテンシが均一であるかどうかの影響は決して無視できない。
あとは7nmプロセスの製造が上手くいくかどうかですが、TSMCの技術力を見る限りはそれほど心配はなさそう。既に7nmで製造されている「Apple A12」などは、すこぶる調子良いので、TSMCの技術力に期待したいところです。
以上「Zen 2の痺れる設計を解説。Ryzenの欠点を解決して真の完成形になりそうです。」について、初心者向けに図解を使って解説でした。
その他「Ryzen」な記事

「Zen 2」もスゴそうですが、現在の「Zen+」もなかなかのモノです。

2018年4月と、ちょっと古いですが。Ryzen 7とCore i7のスペックの違いや性能差を分かりやすくまとめたガイド記事。i7 8700Kに圧勝とは行かないが、コスパを考えるとやっぱり魅力的。












 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選

 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


これだけ変化があってもソケットはそのままなんでしたっけ?
だとしたらすごいですよね
ゲーミング性能でインテルを上回ってほしいですね!
ボトルネックが2つあったとは知らなかった 超期待
いよいよグラボだけ変えてだましだまし使ってきた7機とお別れ出来そうだ
20年1月14日までにインテルの10nm、間に合わないですよねぇ…
所謂コア間レイテンシの問題が解消される反面I/Oダイのアクセスレイテンシが問題になる可能性もありますね
良きにしろ悪しにしろ現行のRyzenとは性能の傾向が大きく変わりそうですね
Zen2では不具合の嵐になるかもしれないので、こなれるだろうその次のシリーズになるまでは見守る感じかな
ZENアーキの問題点はメモリアドレス(リード時のHOP数、経由の数)によって読み出しのレイテンシーが不安定になる事です。
つまり限界性能にしたいならデータ配置に特別な配慮が要る、って事です。
完全に独立なマルチスレッド処理(OSやデータベース等)では問題無いですが、依存性のあるマルチスレッド(画像処理ゲーム)だと弱い、って事ですね。
Zen2のアーキテクチャではIOチップを必ず介する事でHOP数が均質になり問題が改善する為IFOP由来の遅さ、なんて問題は「存在し無い」ですよ。帯域要るなら内部クロック上げれば良いだけの話です。そしてメモリが絡まなければクロックは簡単に上げられます。メモコン同期してたからクロック上がらなかっただけなんで。
欠点らしい欠点が見つからない、だから大騒ぎされてるんで、そこはちゃんと書いた方が良いですよ?
なるほど、IFOPのボトルネック次第ではせっかくの革新的な設計も台無しになる可能性もあるのですね
i9-9900K買おうと思い、Zen2までとりあず待ってみることにしましたが、さらに悩みの種になりそうだ
現状まだまだintel系のCPUに最適化されているソフトが多い感じがして迷います
intel=オールラウンダー
AMD=コスパはいいけど不得意部分がある
というイメージを色々なベンチ見てると思ってしまいます
4コア×2で安価にできてた8コアが
8コア×1になったら値段はどうなるんだ
値段はそれほど変わらないと考えられます。4コアx2 + その他もろもろが含まれているのが、最小単位「Zeppelin」ダイ。
Zen 2では、ここからCPUとその他もろもろを分割して、CPU部分だけ7nmプロセスで製造します。つまり、構造としてはシンプルになるし、微細化によってチップ面積を抑えられます。
コア数が多いほど歩留まり率が悪化するのは、単にチップが巨大化することによる影響が大きい。だから7nm化で小型化し、そこに設計のシンプル化も加わるので、歩留まり率が酷くなる可能性は低いと思ってます。
IFISの説明が間違っていますね。
こちらは基本的に2ソケット用のプロセッサ/マザーボードにつかわれるものなのでZEN2だからなくなるということは絶対にありません。
なお、一般向けのRYZENにはPCIeでGPUやNVMeやチップセットと接続されています。
すみません。IFISの理解が完全に間違えているので、修正します。
ご指摘ありがとうございます(_ _)
8コア最小単位って歩留まり率はどうなるんでしょう?
ryzenって歩留まり率の高い4コアを組み合わせるからあのコスパを実現できたと思っていたのですが……そもそも8コアを組み合わせるとなるとお高くなりそう……
歩留まりが下がるのはコア数が多くなることではなく、コア数が増えることでダイサイズが大きくなることが原因です。
(もちろん製造プロセスの成熟や多少の欠陥が生じても大丈夫な設計にする等、ダイサイズ以外の要因もありますが)
https://pc.watch.impress.co.jp/img/pcw/docs/167/935/html/kaigai_10.jpg.html
PC Watchのこの画像を見ればわかるかと思いますが歩留まりはダイサイズが大きくなるにつれて大きく下がります。
Zen2の場合、8コアのCPUChipletのダイサイズは大まかな試算では7nmプロセスで70mm2強と考えられていますがこれは現行のRyzenのZeppelinダイの14nmプロセスで210mm2強の約1/3です。
これほどのサイズ差があれば7nmプロセスの成熟が十分進んでいなかったとしても歩留まりが極端に悪いという可能性は低いと思います。
次期EpycのI/Oダイ400mm2を超えると考えられていて、かなり大型ですがこちらは成熟の進んだ14nmプロセスなので問題はないと思われます。
14nmプロセスではAMDは既に486mm2のRX Vega 64を作っているのでこちらも歩留まりが悪いという可能性は低いでしょう
演算機(レジスタ)が間違ってます。レジスタはCPUに一番近いところにあるメモリのことで、演算機ではありません。
non EUV 7nmはダイ面積あたりのコストが非常に高いと言う問題があります
微細化による集積度の向上を一定程度相殺しますので噂のような16コアモデルがあるとしても相当高コストになるでしょうね
AVX-512はともかく256にネイティブ対応するなら、8コアまでなら真にINTELに追いつく感じですかね?。
RYZEN 7 2700Xまでは難あったりi5にすら負けたりもあったり消費電力割と高かったりでモヤモヤしてましたが、ZEN 2はモヤモヤが解消しそうで真に良さげな感じがしますね。
Zen2の3世代Ryzenいつ頃出るだろう・・・
たぶん来年だな・・・。うーん
1CCXで8コアになる、という話のソースはどこでしょう?
たまに見かけるのですが一次ソースを見たことがないのです。
個人的には1 chipletが2CCXで8コアという可能性も普通にあると思っているのですが。
AMDはChipletの中身については、まだ詳しいことを発表していませんが、CPU部分と他を分割するという内容なので、1CCXになるのかな…と。
「CPUと他の部分を分割する」というAMDの構想をそのまま真に受けるなら、ChipletにはIFが残らないことになります。だから単一8コアになるのではと思ったわけです。
もちろん、現時点の情報からそういう推測が出来るというレベルの話なので、従来通り2CCXで8コアという可能性も全然残っていますが。
どちらにせよ、次の発表が楽しみです。
大原氏はどちらのパターンも有り得るという見解ですね。
https://news.mynavi.jp/article/20181201-amd_next_horizon/3
今後の情報が楽しみです。
えーと、つまり1ソケット64コアになるとも言われている
スリッパが動画エンコードとかで異次元の速さを誇ったりできるってコトですか…?
(ソフトの対応状況にもよるだろうけど)
つまり、名実ともにIntelを完全に超えるってコトですか?
とにかく、来年のZen2シリーズの発売が超楽しみです。
エンコードはソフトの対応状況からするとあまり期待すると裏切られそうなので何ともかなと。
CCXが複数必須な多コアの場合はクロックとの兼ね合いで64コアより32コアが有利のケースは多々ありそうですし。
とりあえずCCXのネックがなさそうな8コア以下でCore iとガチで勝負できそうなコア当たりのシングル性能で追いつけ追い越せで楽しみですね。
>微細化による集積度の向上を一定程度相殺しますので噂のような16コアモデルがあるとしても相当高コストになるでしょうね
それでもギリギリまで値段を抑えることでインテルの息の根を止める事が出来る
AMD自体インテルの十分の一以下の企業規模だしブルドーザー以降はずっと
赤字だったのがようやく黒字になったって所だから採算度外視な戦法なんて取ったら
逆にAMDの息の根が止まってしまう。
[…] 「Zen 2」の痺れる設計を解説。Ryzenの欠点を解決して真の完成形になりそうです。 更新日2018.11.21 […]
画像が見れません
PS5に使われそうだから妄想してみた。
Zen 2世代のEPYCのIFOPって8つあるけど、
1つのIFOPに基本システム用にZen2(Core8)を1つ入れて、
4つのIFOPの其々にレイトレ対応強化版Cell(AVX-512対応でLocal4MB仕様の強化版SPE×12、ネットワーク連携対応)を入れて、
2つのIFOPはGPU用にそれぞれSLI的にNaviを繋げて、
残り1つIFOPは外部機器との強化連携ポートとして使う。メモリは4GB×8つで32GB。NICはギガイーサ3ポート。
一台のハードで家族4人でVR出来るよ。
‥的な構成とか、ロマン仕様を考えたけど絶対無理やなww
Zen2でも,Chipletの中身は,純粋な8コアではなく,これまでと同様4コアCCX×2の構成だったようですね.CCXを4コア以上に拡張する意味はないともされています.
↓↓
https://news.mynavi.jp/article/20190530-833748/
どうしてでしょうかね?
IFを排除して,純粋な8コアにすることに,性能向上に対するメリットがないとは思えませんが・・・.
やはりコスト(コストに見合った性能向上がない,もしくは,同コア数のインテルCPUに対して価格のアドバンテージがなくなるなど)なのでしょうかね・・・?
AviUtlのプレビューが安定しないのは他に原因がある気もするんだよなあ、僕のRyzen機で起こったことないし。
ぼくもRyzen機がいくつかあるのですが、再現できたりできなかったり…。BIOSのバージョンや、メモリの相性など。複合的な要因で発生する不具合のようです。Intel機ではこのような不具合は一度も無かったんですが…(苦戦)。
[…] 「Zen 2」の痺れる設計を解説。Ryzenの欠点を解決して真の完成形になりそうです。 […]
なぜRyzen 3 3100は4コアCCXのうち2コアを無効にするのですか?発熱や消費電力の問題なんでしょうか?無効にする利点を教えてください。