

月額料金なし、検閲なし、枚数制限もなし。
無制限かつ自由にAIイラストを生成させるなら、Stable Diffusion XLやQwen Imageをパソコンで動かせる「ローカル版AIイラスト」が必要です。
しかし、ローカル版AIイラストはグラフィックボードも必須です。
- VRAM容量が大量に欲しい
- GeForceシリーズが絶対に良い
- Radeonは玄人向けだから避けるべき
などなど、いろいろな情報が飛び交っていますが実際のところはどうなのか?
(公開:2023/3/8 | 更新:2025/8/24)
AIイラスト(Stable Diffusion)におすすめなグラボを検証
検証方法:AIイラストの生成速度をテストする
AIイラスト(SDXLやQwen Image)におすすめなグラフィックボードをテストする方法はシンプルです。
実際にAIイラストを何枚か生成させて、処理にかかった時間と生成速度を比較します。比較した中で、時間が短く速度が速いグラボほどおすすめだと分かります。
今回のStable Diffusionベンチマークでは、以下2つの数値を「性能」として扱います。
- ログに表示される生成時間(Prompt executed)
- ステップ数を生成時間で割った速度(Iterations per Second)
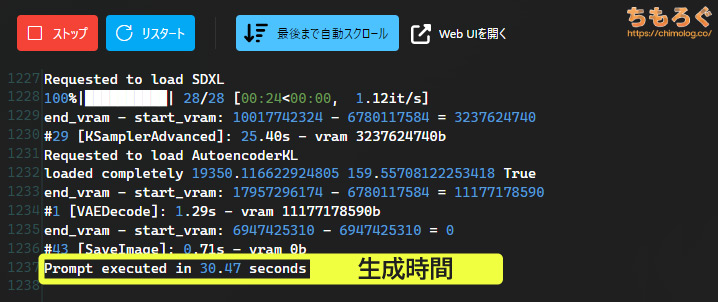
生成時間が一番分かりやすい指標です。生成ボタンをクリックしてから、完成したAIイラストが表示されるまでにかかった時間を示します。
イラストを10枚生成するのに60秒や120秒もかかるグラボより、10秒や20秒でサクッと終えられるグラボの方が高性能です。
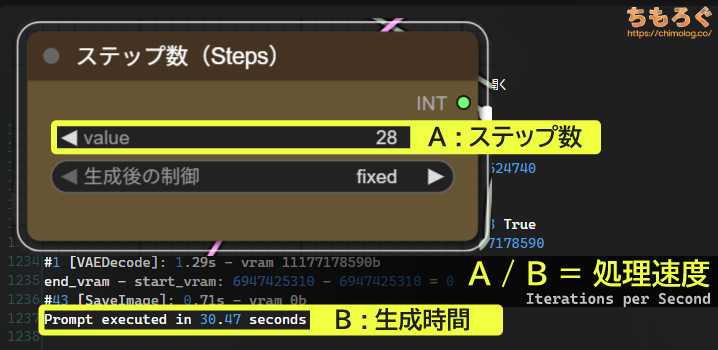
生成速度(it/s)はもっぱらそこまで気にしなくていい指標です。ベンチマークオタクがグラボの性能を比較するときに役立つ程度で、基本的に「生成時間」に注目しましょう。
Iterations per Secondを略して「it/s」と呼ばれる、いわゆる生成速度ですが、誤解を招きやすい深刻な欠点があります。
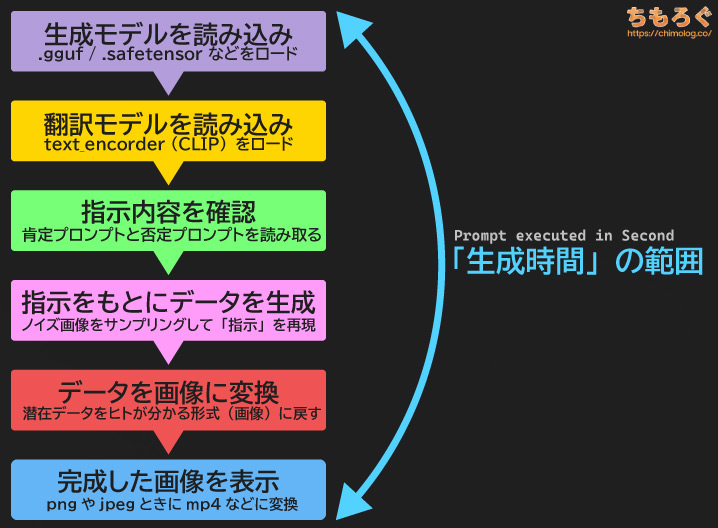
AIイラスト生成は少なくとも5~6段階の工程がある、かなり複雑なワークフローです。モデルをロードし、指示内容(プロンプト)を読み、ノイズ画像を目的の画像に変換します。
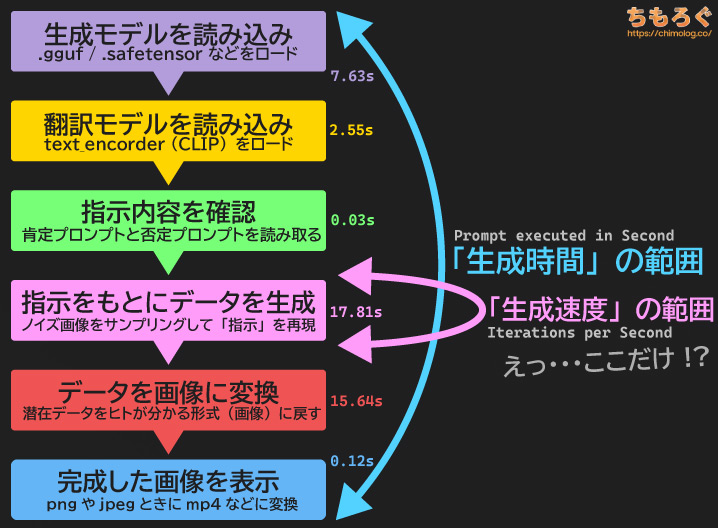
このうち「生成速度(it/s)」が測定している範囲は、「データを生成する1工程」だけです。生成と同じくらい時間がかかる場合も多々ある「データを画像に戻す工程」が含まれません。
専門用語で「VAEデコード」と呼ばれる処理で、フルHDや4K解像度のイラストを生成させると、意外にもデータ生成と同じか以上の時間がかかってしまいます。
しかし、どれだけ時間がかかっても生成速度(it/s)に一切含まれないため、非常に誤解を招きやすい指標です。
速度が速いのに一向に画像が出てこない・・・なんてグラボを買いたくないですよね?
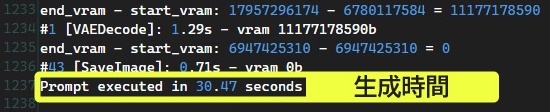
結論、「生成時間(秒)」を参考にしてください。
なお、本ブログに掲載する生成速度(it/s)は、合計ステップ数を生成時間で割ったオリジナル指標です。VAEデコードも含めた生成速度なので、実態に近い数値を出せます。
テスト環境:使用したグラボとPCスペックを紹介

| テスト環境 「ちもろぐ専用ベンチ機(2025)」 | |||
|---|---|---|---|
| スペック | NVIDIA GeForce | AMD Radeon | Intel ARC |
| CPU | Ryzen 7 9800X3D(レビュー) | ||
| マザーボード | ASUS TUF GAMING X670E-PLUS WIFI | ||
| メモリ | DDR5-5600 128GB(64GB 2枚組) → Crucial Pro DDR5-5600 | ||
| グラボ 全40枚 |
|
|
|
| SSD データ置き場 | WD Black SN850X 8TB → 8 TB版レビューはこちら | ||
| OS | Windows 11 Pro (24H2) | ||
| 生成ソフト | ComfyUI v0.3.50 pytorch 2.7.1 + cu128 | ComfyUI v0.3.51 pytorch 2.6.0 + rocm6.4.2 | ComfyUI v0.3.51 pytorch 2.9.0 + xpu |
| ドライバ | Game Ready 580.88 WHQL | Adrenalin 25.6.3 WHQL | Intel Graphics 32.0.101.6989 |
| ライブラリ | NVIDIA CUDA | AMD ROCm PyTorch for ROCm 6.4.2 | Intel XPU Intel Extension for PyTorch |
今回のStable Diffusion(SDXLやQwen Image含む)ベンチマークで使用するテスト機のPCスペックです。
CPUにRyzen 7 9800X3D(8コア16スレッド)、メモリにDDR5-5600(JEDEC準拠)を容量128 GBたっぷり搭載しました。
テストに使用したグラフィックボードは全部で40枚(GeForce:31枚 + Radeon:7枚 + Intel ARC:2枚)です。
約50枚ほどグラボを検証用に所有していますが、時間の都合で古い世代を見送っています。
【グラボ別】AIイラスト(Stable Diffusion)の生成速度

全7種類のベンチマークで生成時間(秒)と生成速度(it/s)を比較します。
テストごとに使用したモデルやプロンプト、細かい設定やシード値はそれぞれのテストごとに記載します。テストごとに、ComfyUIで使えるテンプレート(workflow)も配布します。
省VRAM化に特化した生成ソフト「ComfyUI」と「ReForge」が主流になり、計算負荷を下げて処理速度を向上する時代に切り替わっています。
結果的に、計算負荷が非常に重かった初代「A1111 Web UI」と比較して、同じプロンプトや設定に対する生成結果の「再現性」が下がりました。
そもそもForge版が登場した時点で、A1111版と比較して生成品質に違和感を覚えた人は決して少なくないはず。計算を端折る「高速化」「効率化」技術は往々にして、品質や再現性をわずかに捨てている傾向です。
| Stable Diffusion 起動オプション 「Stability Matrix」の引数 | |
|---|---|
| GeForce RTX 30~50シリーズ | --fast --use-sage-attention |
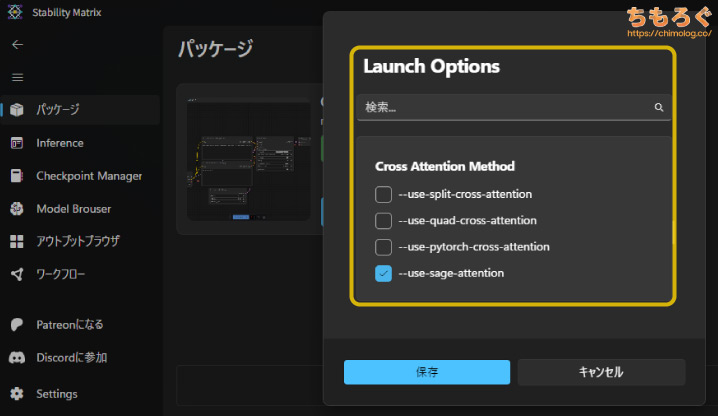
Stability Matrixから設定できる「Launch Options」を、グラフィックボードの仕様に合わせて調整します。
GeForceシリーズは基本的な高速化オプション「--fast」と「--use-sage-attention」を入れて、わずかな品質低下と引き換えに約15~20%程度の高速化です。
| GeForce RTX 20シリーズ | --fast |
|---|---|
| GeForce GTX 16xxシリーズ GTX 10xxシリーズ | --fast --lowvram |
RTX 20シリーズ以前の場合、Sage Attention有効化でかえって生成速度が大幅に悪化するので、sageオプションのみ削除します。
VRAM容量に余裕がないGTX 16xxシリーズは、メインメモリの利用比率を増やす「--lowvram」オプションを追加します。
GTX 10xxシリーズも同じく「--lowvram」オプションを入れています。律儀にFP32演算で処理するせいか、異様にVRAM使用量が多いので苦肉の策です。
速度を犠牲にメインメモリを活用するLOW_VRAMモードですが、そもそもVRAM容量が少ないグラボなら、むしろ安定して動作する傾向です。
| AMD Radeon RX 9000シリーズ RX 7000シリーズ | --use-sage-attention --bf16-vae --disable-xformers |
|---|
AMD Radeonシリーズは、処理速度を向上させる「--use-sage-attention」と、一部のVAE処理を安定化させる「--bf16-vae」も併用します。
| Intel ARC A / Bシリーズ | --normalvram --bf16-unet |
|---|
Intel ARCの場合、なぜかVRAM比率に関係するオプションがまったく効果を示さなかったので、諦めて「--normalvram」をそのまま使います。
「--bf16-unet」は、生成品質をほんの少しだけ捨てて、代わりに動作の安定性を向上させるオプションです。

| テストに使用した生成AIソフト | |
|---|---|
| GeForce用 | ComfyUI(Stability Matrix) (https://lykos.ai/) |
| Radeon用 | |
| Intel Arc用 | ComfyUI(Intel XPU) (https://github.com/ai-joe-git/ComfyUI-Intel-Arc-Clean-Install-Windows-venv-XPU-) |
パッケージ管理システムを「Stability Matrix」に、Stable DiffusionやSDXLなどAI生成を実行するソフトを「ComfyUI」に一本化します。
豊富な人材と資金に恵まれ、長年にわたってサービスが続く可能性がもっとも高いです。
動画生成モデル「Wan2.2」や、画像生成モデル「Qwen Image」や「Qwen Image Edit」など、最新技術へのネイティブ対応も他に類を見ない最速級。
PyTorchやSage Attention(Triton)など、各種ライブラリの対応も非常に早くて助かります。以前、Web UI系がなかなかRTX 50シリーズに対応しない中、ComfyUIはわずか7日で対応していました。
あの早さを見て以降、ComfyUIに乗り換え確定です。わざわざ「pip install ~」から始まる面倒で複雑な呪文を唱える必要もありません。
もちろん、Web UI系に匹敵する大量の拡張プラグインも存在していて、自分の好みに合わせて使い方を最適化しやすいです。
テンプレートファイル(ワークフロー)をComfyUIに放り込むだけで設定値をキレイに再現できる仕様があり、正確なベンチマークに使いやすい利点もあります。
なお、以前のテストで使っていた「AUTOMATIC1111版」と、lllyasviel氏が開発した「Forge版」はどちらもサポート終了済みです。
512×512:ハローアスカベンチマーク

- 生成モデル:nai-anime-v1-full.safetensors
(https://huggingface.co/TechnoByte/nai-furry-anime-safetensors/)
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | masterpiece, best quality, masterpiece, asuka langley sitting cross legged on a chair | ||
| Negative | lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 512 | Batch count | 1 |
| Height | 512 | Batch size | 10 |
| CFG Scale | 12 | ||
| Seed | 2870305590 | ||
- ComfyUI用
ワークフローをダウンロード
「ハローアスカベンチマーク(Hello Asuka Benchmark)」は、日本のとある生成AI系Wikiで考案された、伝統的なStable Diffusionの定番ベンチマークです。
いにしえの「SD 1.5」モデルをベンチマークに使うため、2025年の今となっては処理が軽すぎて参考にしづらいです。
しいてメリットを挙げるなら、VRAM容量に引っかかる可能性がほとんどない性質から、グラボ本来の純粋なAI生成性能(計算性能)を比較できます。
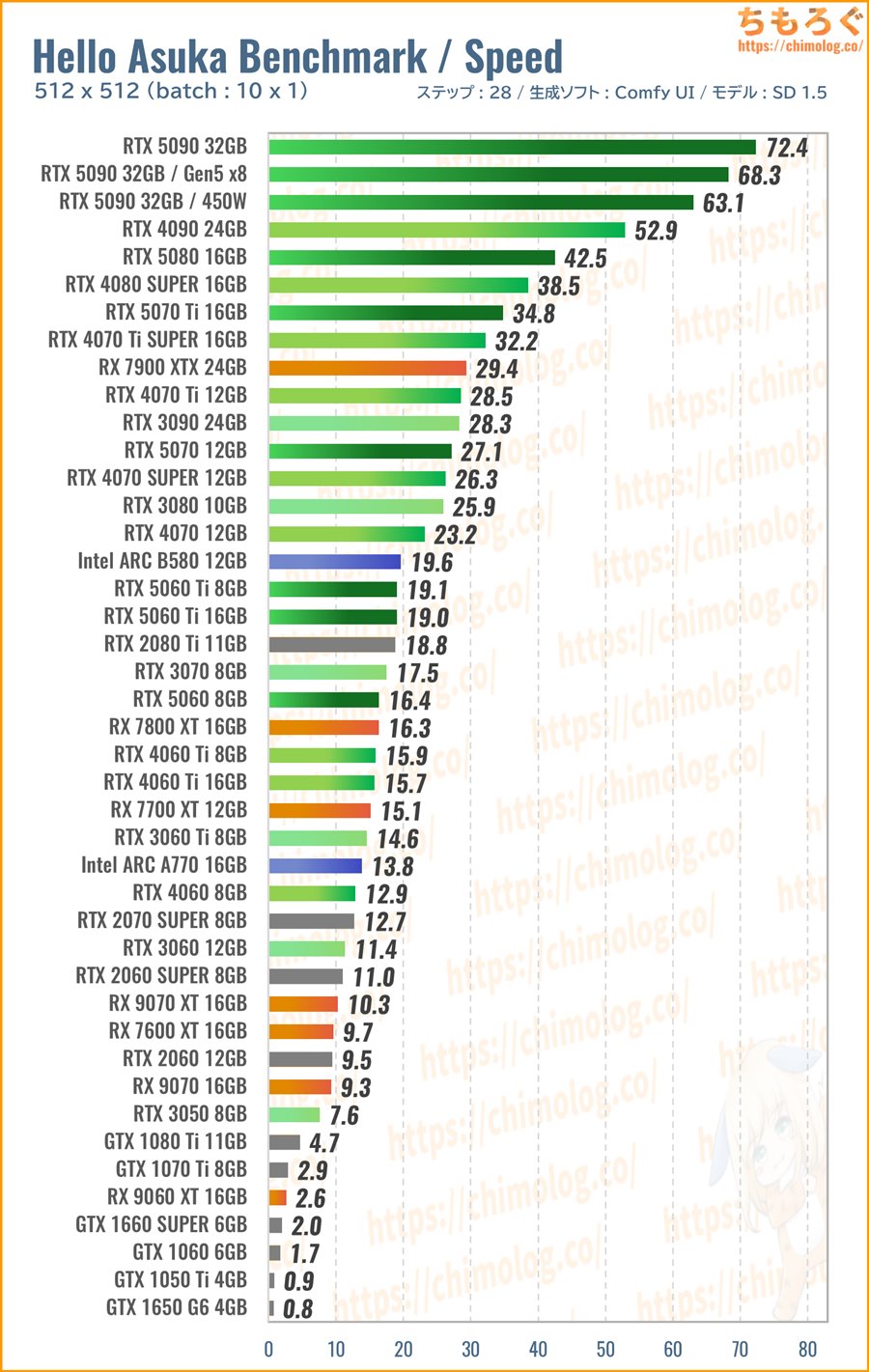
(※クリックすると画像拡大)
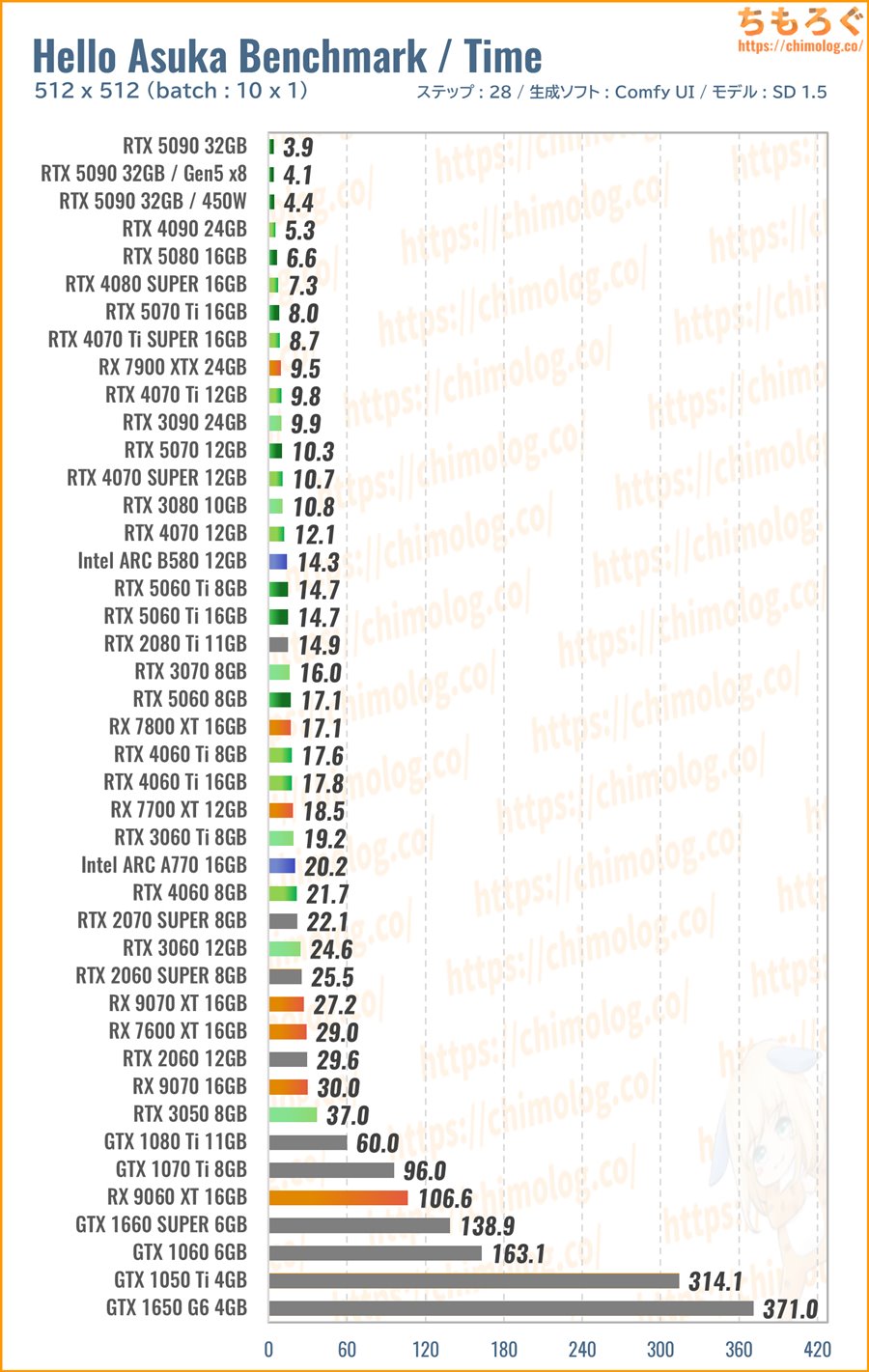
ハローアスカベンチマーク(512 x 512)の生成時間(秒)をグラボ別に比較したグラフです。
最強クラスのRTX 5090~RTX 4090は、なんと4秒台を記録します。1枚あたり、たった0.3~0.4秒でハローアスカを生成します。
定番グラボのRTX 5070なら10秒、1枚あたり1秒で生成でき、RTX 5060 TiやIntel ARC B580は1枚あたり1.5秒前後です。
全体的な傾向をざっくり見ると、RTX 50~40シリーズがやはり猛威をふるい、Intel ARCシリーズがコスパ面でポテンシャルを感じる結果に。
一方で生成AIが不得意とされるRadeonシリーズですが、Windows版ROCmの最適化が進んだおかげで以前より速度が早く改善されています。
特にRX 7000シリーズがおおむねスペック値に近い性能を出せています。RX 9000シリーズはまだまだ最適化不足で、今後のベンチマーク結果に暗雲が立ち込めています。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
ハローアスカを細かく分析しても、あまり意味がないので傾向をざっくり要約します。
- Intel ARCにポテンシャルあり
- Radeonは全体的に不調気味
- GeForceの安定感
負荷の軽いハローアスカベンチの傾向です。
次からもっと重たい生成モデルや、大きな解像度で性能がどう変化していくか、順番に見ていきます。
832×1216:神里綾華ベンチマーク

- 生成モデル:WAI-NSFW-illustrious-SDXL v14.0
(https://civitai.com/models/827184)
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | 1girl, kamisato ayaka, \(chainsaw man\), ponytail, kimono, floral print, japanese clothes, head tilt, holding weapon, katana, violent theme, half-closed eyes, bored, glowing eyes, loose collar, light smile, yandere, maniac, adjusting clothes, moonlight, light rays, Falling petals, | ||
| Negative | chiaroscuro, 3d, bad quality, worst quality, worst detail, sketch, censor, | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 832 | Batch count | 10 |
| Height | 1216 | Batch size | 1 |
| CFG Scale | 5 | ||
| Seed | 20210932 | ||
- ComfyUI用
ワークフローをダウンロード
ここからは筆者が作成したオリジナルベンチマークで、AIイラストの生成時間を比較します。

圧倒的な支持を得ている大人気生成モデル「WAI-NSFW(v14.0)」を使って、特定のキャラクター(原神より:神里綾華)を生成するベンチマークです。
SDXL世代でもっとも主流な解像度「832 x 1216」を検証します。ベースモデルが「SDXL 1.0」に切り替わり、解像度も大きくなったから、ハローアスカベンチより約6~8倍も重たいです。

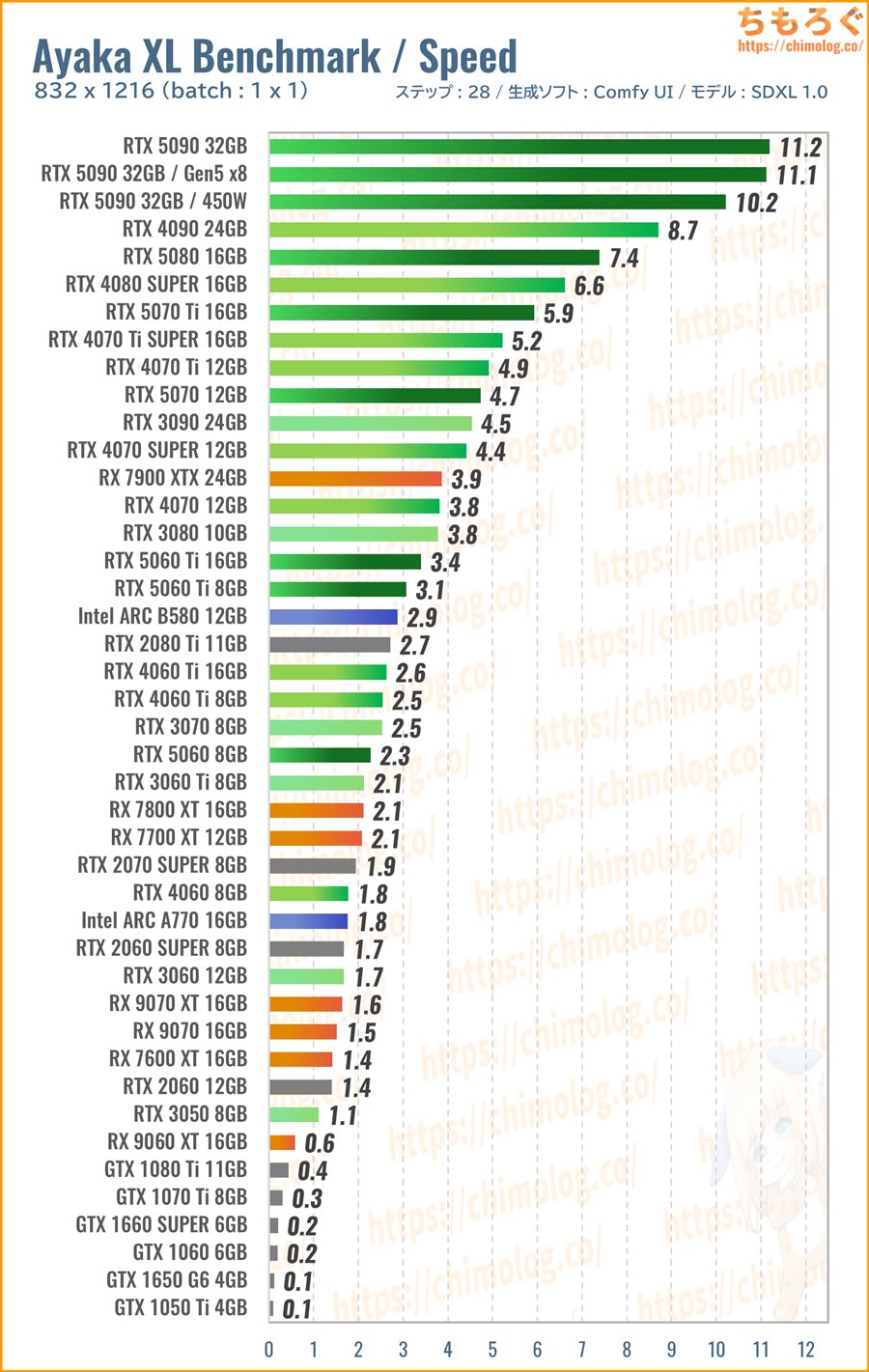
(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。5枚ほど連続で生成させて、1枚あたりの平均時間を比較しています。
RTX 5090がわずか2.5秒で1枚生成する驚異的な速さですが、正直なところRTX 4090と体感性能が変わらないです。
5秒台を出せているRTX 5070やRTX 5070 Tiでも、十分に速いと感じる人がおそらく多い予感もします。
許容できる時間は人それぞれなので、処理時間ごとに区切った中でコスパがいいグラボを選べば問題ないです。
- リアルタイム生成:RTX 4090
- 5秒前後:RTX 5070
- 10秒前後:RTX 5060 Ti
(またはIntel ARC B580) - 15秒台:未だにRTX 3060 12GB
といった具合で、基本的にRTX 50シリーズから選びます。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
単純なコストパフォーマンスで見ると、Intel ARC B580が異色の強さを見せています。RTX 5060 Tiに迫る生成速度を、4万円台で出せています。
逆にRadeonシリーズが軒並み不調です。Windows版ROCmが登場して以前より高速化したものの、同時にGeForceも最適化が進んでいて性能差を埋められない構図に。
RX 7900 XTXでようやくRTX 4070に並びます。Intel ARCにコスパで敗れ、GeForceに性能で勝てない、見慣れたいつもの光景が眼前に広がります。
VRAM容量を大量に食っていたA1111版であれば、VRAM容量の割に価格が安いRadeonに一定の優位性がありました。
しかし、現在主流のComfyUI(ReForge)は本当に省VRAM化が進化していて、SDXL推奨サイズ(832 x 1216)を生成するくらいなら容量8 GBで十分です。
技術の進歩で相対的に大容量VRAMのニーズが薄れ、ほどほどのVRAM容量で処理速度が速いGeForceやIntel ARCが優位な状況です。
832×1216:神里綾華(x10)ベンチマーク

| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | 1girl, kamisato ayaka, \(chainsaw man\), ponytail, kimono, floral print, japanese clothes, head tilt, holding weapon, katana, violent theme, half-closed eyes, bored, glowing eyes, loose collar, light smile, yandere, maniac, adjusting clothes, moonlight, light rays, Falling petals, anime coloring, masterpiece, best quality, amazing quality, | ||
| Negative | chiaroscuro, 3d, bad quality, worst quality, worst detail, sketch, censor, | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 832 | Batch count | 1 |
| Height | 1216 | Batch size | 10 |
| CFG Scale | 5 | ||
| Seed | 20210932 | ||
ワークフローの配布はありません。Ayaka XL Benchmarkのバッチサイズを10に変更して実行するだけです。
コメント欄でまれにリクエストがあった、バッチサイズ:10のベンチマークです。
- batch count:1枚ずつ繰り返し生成
- batch size:一度に複数まとめて生成
バッチカウント(count)が連続キュー処理に対して、バッチサイズ(size)は並列スレッド処理です。並列処理は大量にVRAMを消費するため、VRAMの容量と利用効率が求められます。

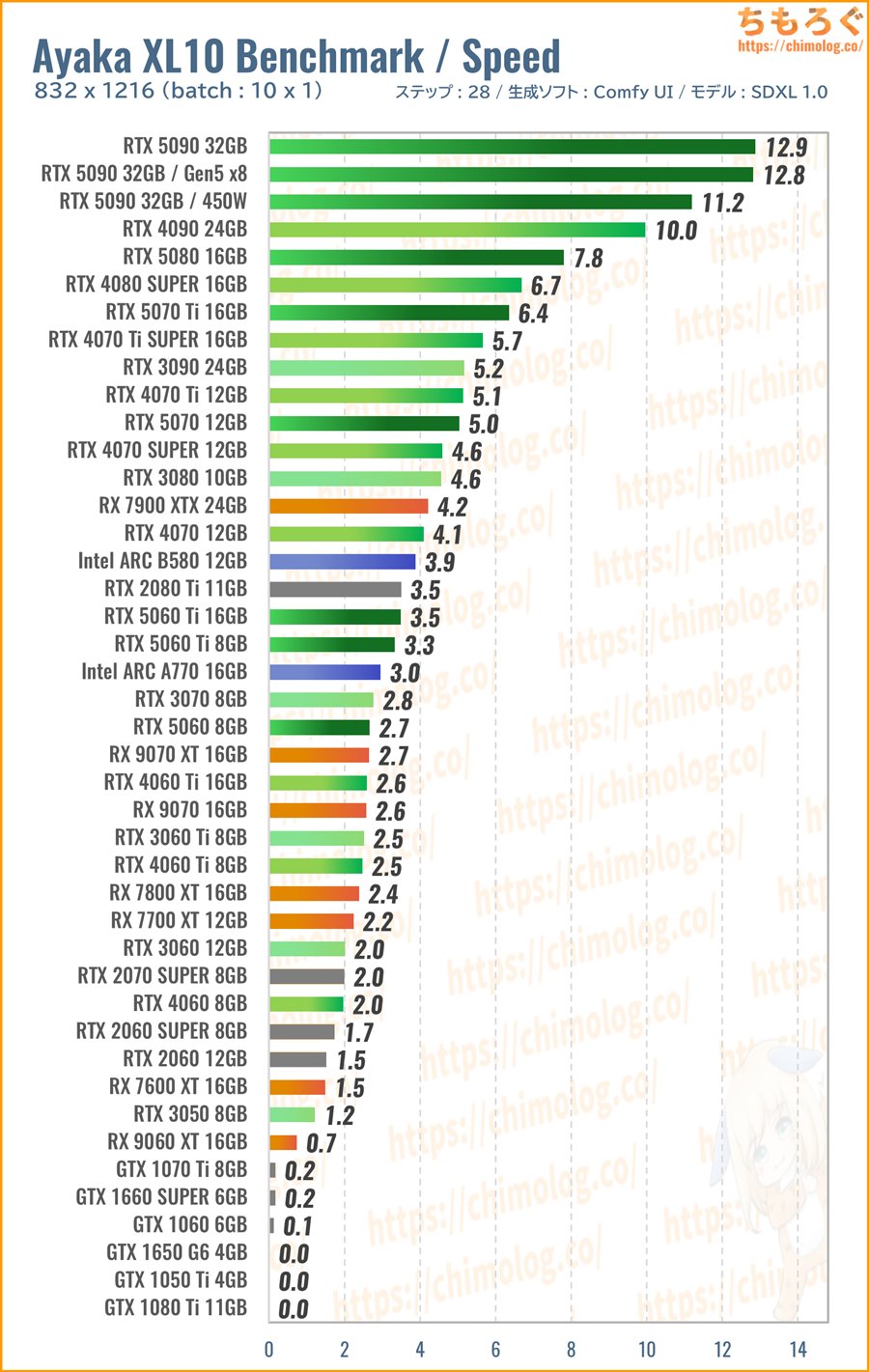
(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。
連続して10枚生成するより、一度にまとめて10枚生成させた方が効率よく性能を伸ばせます。
今回のベンチマークをざっくり見る限り、SDXL 1.0の推奨サイズ(832 x 1216)をまとめて10枚生成する程度なら、ほとんどのグラボが連続処理より高速化します。
VRAMが少ないRTX 5060ですら、1枚ずつ出すより5~10枚まとめて出したほうが速いです。
ComfyUI(ReForge)の省VRAM技術が進化したおかげで、VRAM容量がボトルネックになりづらい傾向が明らかです。ある程度のVRAMがあれば、単なる性能比較になります。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
処理が軽すぎるのか、RTX 5090がイマイチ伸びません。RTX 4090から価格相応の伸びにとどまります。
RTX 5070は従来世代より約1.3倍近い性能アップを実現していて、7~8万円クラスで最高のコストパフォーマンスに。
しかし、Intel ARC B580が番狂わせな性能を見せます。約4万円台の低価格ながら、RTX 4070に迫る性能で、RTX 5070に対して2割ほど遅いだけです。
主流のSDXL 1.0系モデル(WAI NSFWなど)をコスパよく動かすなら、Intel ARC B580がコスパ最強格。もちろん、初心者にはRTX 5070やRTX 5060をおすすめします。
832×1216:神里綾華(ControlNet)ベンチマーク

| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | 1girl, kamisato ayaka, \(chainsaw man\), looking at viewer, ponytail, ryougi shiki, leather jacket, japanese clothes, kimono, neon genesis evangelion, | ||
| Negative | 3d, bad quality,worst quality,worst detail,sketch,censor, | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 832 | Batch count | 1 |
| Height | 1216 | Batch size | 5 |
| CFG Scale | 5 | ||
| Seed | 20210932 | ||
| ControlNet設定 | |||
| Image |  | ||
| Weright | 0.60 | Model | CN-anytest_v4-marged.safetensors https://huggingface.co/2vXpSwA7/iroiro-lora/blob/main/test_controlnet2/ |
- ComfyUI用
ワークフローをダウンロード - ControlNet用
参照画像をダウンロード
「ControlNet」モデルを適用すると、狙った構図やポーズを決めてAIイラストを生成可能です。

万能タイプのControlNetモデル「AnyTest v4」を用いて、中央にいるキャラクターを維持したまま、背景やライティング(照明効果)だけを書き換えます。
生成速度がやや下がるものの、目的の構図やポージングを高い確率で生成でき、時間を節約できる技術です。

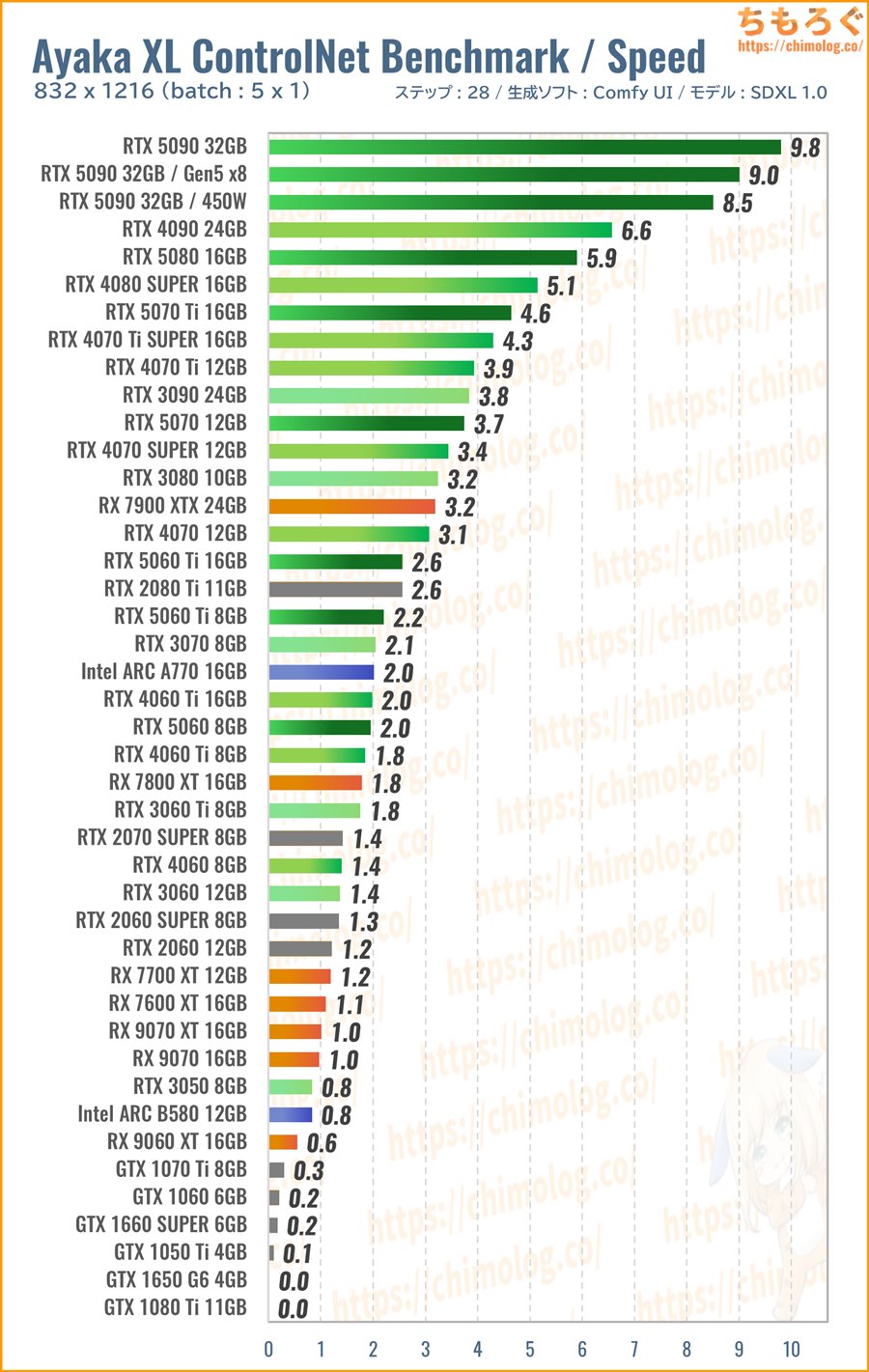
(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。まとめて5枚生成するのにかかった時間を比較します。
ControlNetモデルの適用でVRAM使用量が増え、一部のグラボで大きく性能が下がります。Radeonシリーズも全体的に大きく速度を落とし、グラフの下の方へ追いやられます。
- 1枚あたり10秒:RTX 5060 Ti 16GB
- 1枚あたり6秒台:RTX 5070
- 1枚あたり5秒切:RTX 5080
ControlNetモデルを使う前提なら、もっぱらRTX 50~40シリーズから予算に合わせて選ぶしかない状況です。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
RTX 5090が毎秒10ステップを叩き出し、RTX 4090と比較して約1.5倍に達します。重たい処理になればなるほど、巨大なシェーダーユニットを備えるRTX 5090が有利になります。
コスパ部門のエースはやはりRTX 5070です。約7~8万円の安い価格なのに、10万円を軽く超えるRTX 4070 Ti前後に食いつく性能です。
期待の隠れコスパ枠だったIntel ARC B580は残念ながらVRAM不足で大きく速度を落としてしまい、RTX 3050と大差ない性能に終わります。
Radeon勢・・・、特にコメントはないです。
1664×2432:ヘルタ(Hires.Fix)ベンチマーク

| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | the herta (honkai star rail), \(chainsaw man\), looking at viewer, 1girl, adult, teacher, mature female, medium breasts, violent theme, glowing eyes, light smile, | ||
| Negative | chiaroscuro, 3d, bad quality,worst quality,worst detail,sketch,censor, | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 832 | Batch count | 1 |
| Height | 1216 | Batch size | 5 |
| CFG Scale | 5 | ||
| Seed | 20250145 | ||
| Hires.Fix設定 (Tiles Diffusion) | |||
| upscale | x0.5(=2倍) | sampling steps | 7 |
| upscaler | 4xUltrasharp_V10 | strength | 0.50 |
| ControlNet | illustriousXL_tile_v2.5 | start – end | 0 ~ 0.5 |
- ComfyUI用
ワークフローをダウンロード
WQHD以上のネイティブ高解像度(1664 x 2432)なAIイラストをベンチマークします。
ローカル生成ユーザー的にあまり需要がない解像度に見えて、「#desksetup」界隈で意外な人気を集めています。

しかし、高解像度に最適化されたSDXL 1.0モデルですら、フルHD以上の解像度を出力されると解剖学の崩壊や奇形的な肉体が頻発します。

人体の崩壊を防ぎつつ、高解像度なAIイラスト生成に役立つ機能が「Hires.Fix」です。
ComfyUI(ReForge)が主流になった今風な言い方をすると、おそらく「Tiled Diffusion」や「ControlNet Tile」と呼ばれています。
今回はアップスケーラーに「4xUltrasharp_V10」、アップスケール倍率に「0.5(= 4.0 x 0.5 → 2.0倍)」、ノイズ除去の強さを「0.5」に設定して1664 x 2432サイズの高解像度イラストを生成します。
細部の破綻を防ぎつつ、シャープさやディティールを追加で書き込むControlNetモデル「Tile(IllusriousXL版)」を併用し、ステップ0~50%に範囲で適用します。
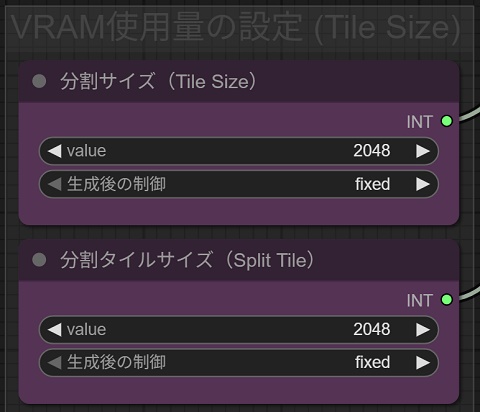
省VRAM技術「Tiled VAE Encode & Decord」
なお、Tiled Diffusionは省VRAM技術「Tiled VAE」に対応しますが、今回のベンチマークはタイル分割サイズ数をなるべく大きく設定します。

分割タイル数を増やすほど少ないVRAM容量でテストを突破可能ですが、肝心の品質が大幅に劣化し、かえって奇形化を招く要因に。
よって、VRAM容量に応じて最低1024 px以上の範囲でタイルサイズを調整します。512 px前後だと、見てのとおり破綻がひどく使いづらいので避けます。

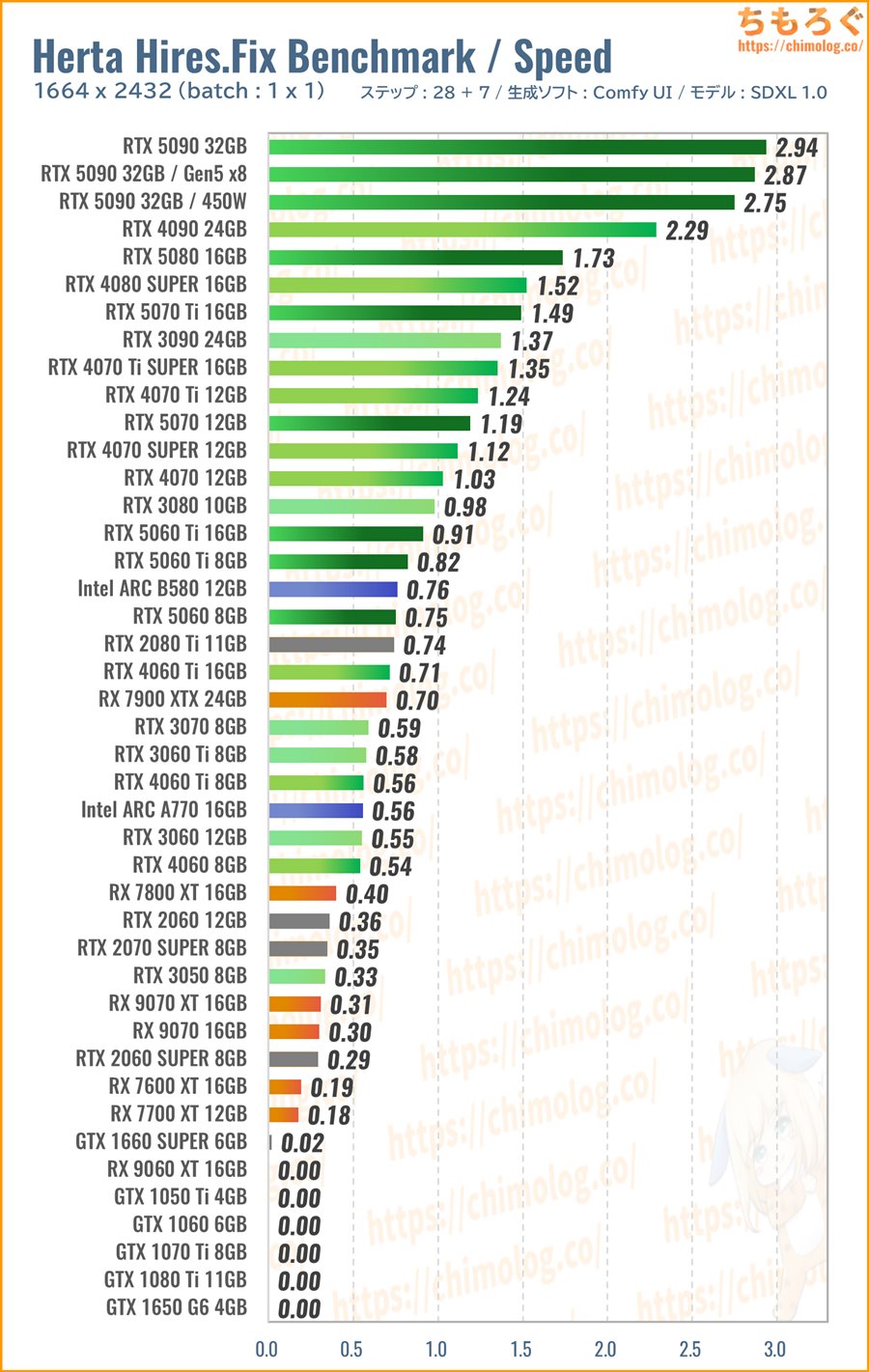
(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。
WQHD相当の大きなイラストを生成している割に、VRAM容量をそれほど要求されず、意外と生成時間が短い印象を受けます。
VRAM容量がたった8 GBしかない「RTX 5060」程度でも、1664 x 2432の生成を1枚45秒ちょっとで終えています。
分割タイルサイズをいい塩梅に調整さえすれば、容量8~12 GBのVRAMですんなり生成可能です。生成品質をギリギリ維持できる1024 ~ 1280 px分割まで耐えられます。
VRAM容量に収まる状態なら、もうシンプルにグラボの性能比較です。
たとえばRX 7900 XTXは約50秒でなかなか悪くないように見えて、Intel ARC B580やRTX 5060よりも遅いです。RX 7900 XTXより安いRTX 5070は時間が半減します。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
VRAM容量が足りる状況でも、Radeonシリーズが全体的に不調に終わり、GeForceシリーズが圧巻の成績を収めます。
Intel ARCシリーズも意外な活躍を見せていますが、GeForceよりVRAMの使用量がやや多く、容量12 GBでようやく8 GB相当の仕事をこなすイメージです。
なお、世代間の妙な逆転劇はおおむねPCIe x8で説明できます。たとえば、RTX 3060 TiとRTX 4060 Tiが分かりやすい例です。
ComfyUIはVRAMとメインメモリを何度か行き来する挙動があるせいで、PCIeバス幅にやや敏感です。だからPCIe x16をx8に減らされるとボトルネックになります。
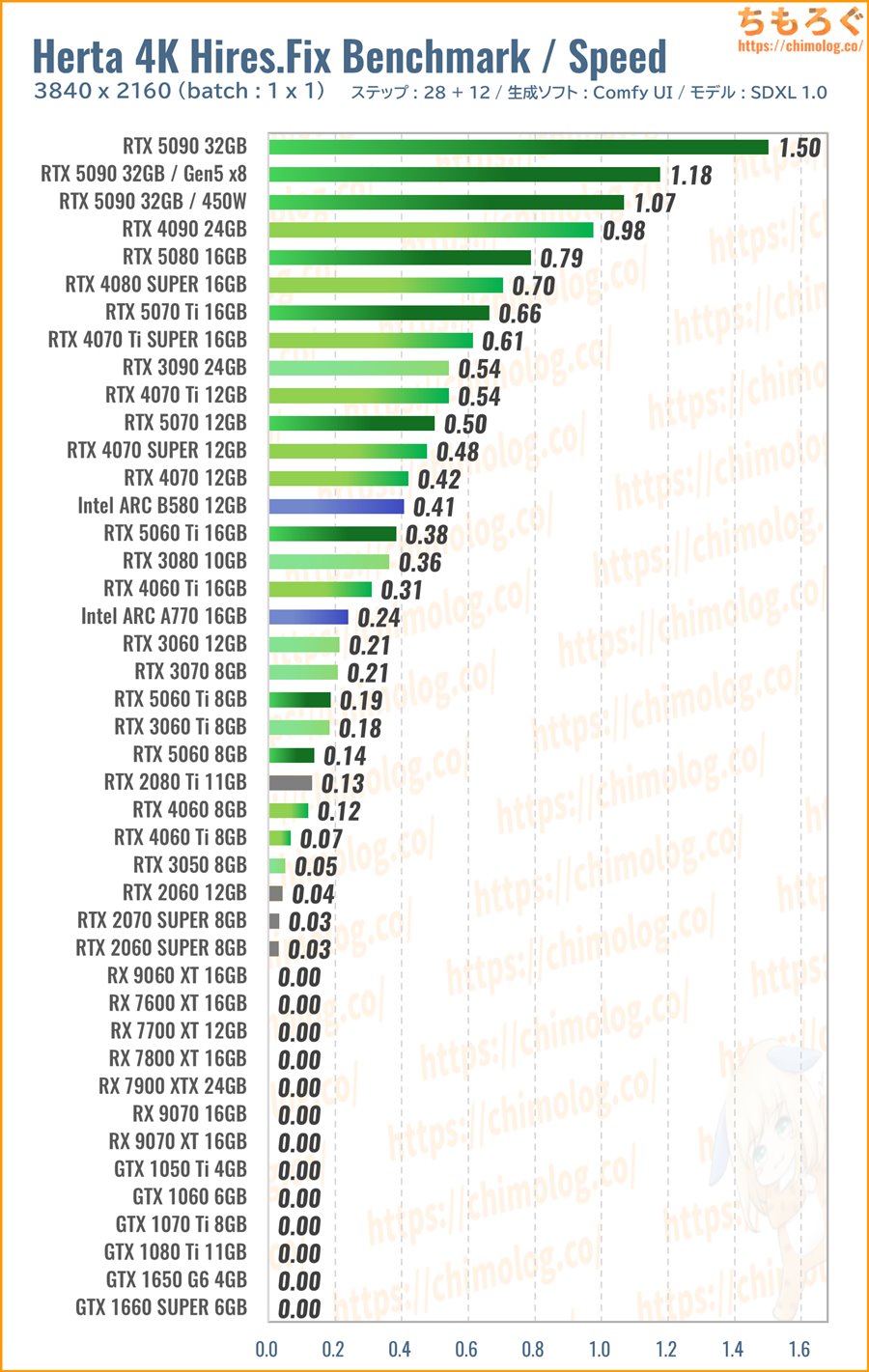
3840×2160:ヘルタ4K(Hires.Fix)ベンチマーク

| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | the herta (honkai star rail), long hair, medium breasts, \(chainsaw man\), violent theme, looking at another, dress, ruan mei (honkai star rail), hair ornament, 2girls, glaring, adalt, mature female, armpitsm, staff, jewelry, fingernails, eyelashes, dynamic angle, facing another, magic circle, clock tower, night sky, outdoors, | ||
| Negative | chiaroscuro, 3d, bad quality,worst quality,worst detail,sketch,censor, | ||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 28 |
| Width | 1920 | Batch count | 1 |
| Height | 1080 | Batch size | 1 |
| CFG Scale | 5 | ||
| Seed | 20250122 | ||
| Hires.Fix設定 (Tiles Diffusion) | |||
| upscale | x0.5(=2倍) | sampling steps | 12 |
| upscaler | 4xUltrasharp_V10 | strength | 0.50 |
| ControlNet | illustriousXL_tile_v2.5 | start – end | 0 ~ 0.5 |
- ComfyUI用
ワークフローをダウンロード
SDXLベンチマークで使っている生成モデル「WAI-NSFW(v14.0)」は、ネイティブ高解像度の耐性が高いです。

the herta (honkai star rail), ruan mei (honkai star rail), 2girls,
若干ガチャ率が上がりますが、フルHD(1920 x 1080)程度なら意外と崩れず生成できるし、複数のキャラクターを同時に生成できます。

Hires.Fix(Tiled Diffusion)を使って、フルHDから一気に4K解像度(3840 x 2160)にアップスケーリングします。
とにかくVRAM容量を激しく要求される高難易度なSDXLベンチマークです。
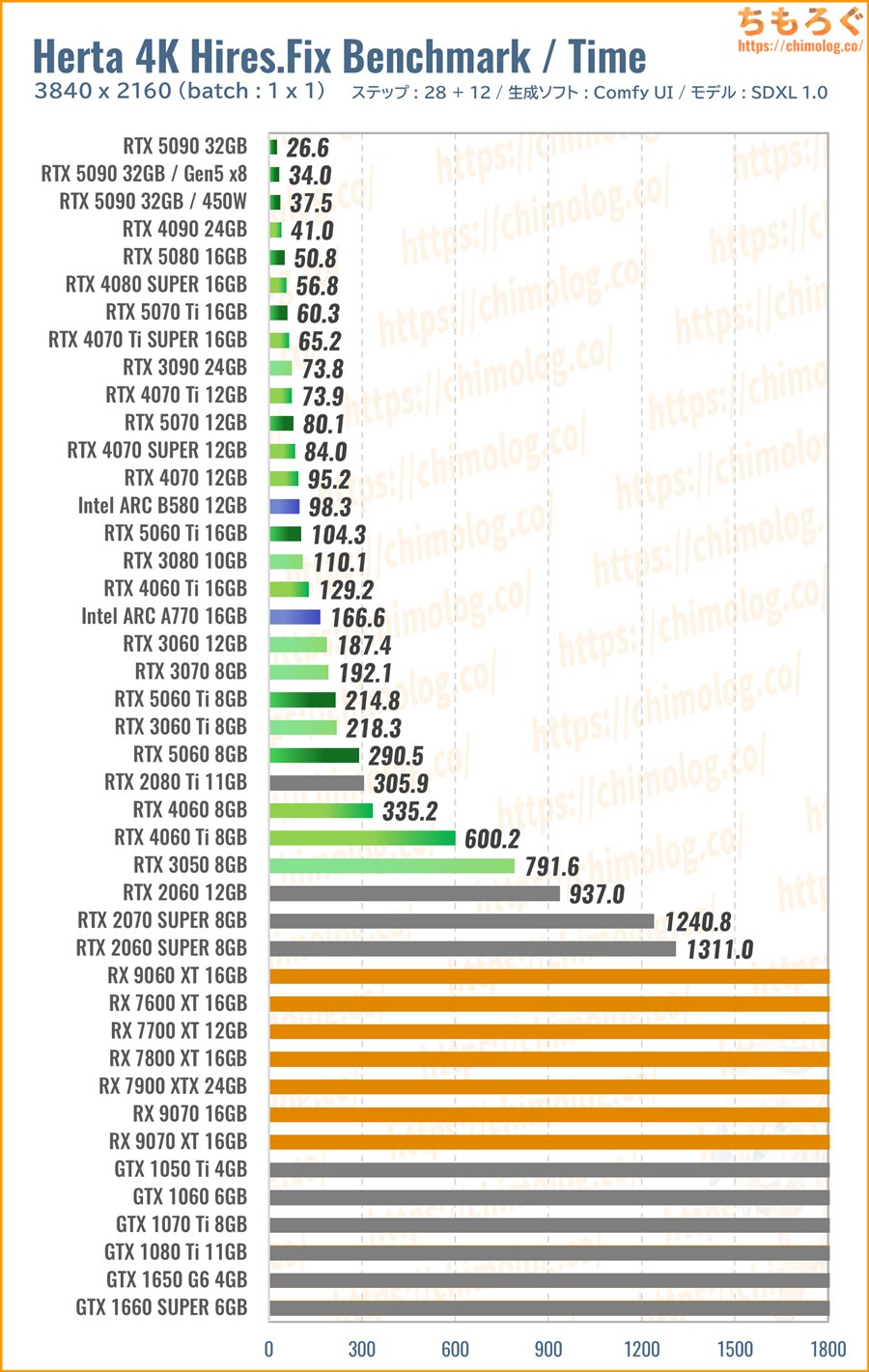
(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。
・・・まず、Radeonシリーズが全滅しました。分割タイルサイズを768 pxまで下げても、体感90%の確率で「miopenStatusUnknownError」で処理が止まります。
(4K出力に耐えられないRadeon)
現状のRadeon(ROCm)だとHires.Fixで4K解像度を生成できないです。4K解像度のイラストを生成するなら、GeForceかIntel ARCの2択です。
特にRTX 50シリーズがやはり優秀。PCIe 5.0 x16対応によりComfyUIと根本的に相性がいいし、VRAMも効率よく使ってくれて、動作の安定性も驚異的。
コスパで「RTX 5070」を、予算をもっと抑えるなら「RTX 5060 Ti 16GB」をおすすめします。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
RTX 5090が別格すぎて敵なしの状況。RTX 4090に対して約1.5倍もの生成速度※を叩き出し、価格に見合う性能差をきっちり見せています。
約8万円で買えるRTX 5070はコスパの華です。しかし、半額近い4万円台で買えるIntel ARC B580の誘惑もなかなか強烈かも・・・。
タスクマネージャーから共有メモリの漏れ具合を見ながら、自分で分割タイル設定を適切にこなせる前提なら、Intel ARCが少なくとも選択肢に入ってくるでしょう。
※補足:VRAM容量が多いほど、タイル分割数を減らして処理速度を向上できます。RTX 5090は容量32 GBもの巨大VRAMだから、4K解像度をシングルタイル(1×1)で処理可能です。RTX 4090は最低でも2タイル(2×1)使う必要があり、処理速度でRTX 5090に勝てないです。
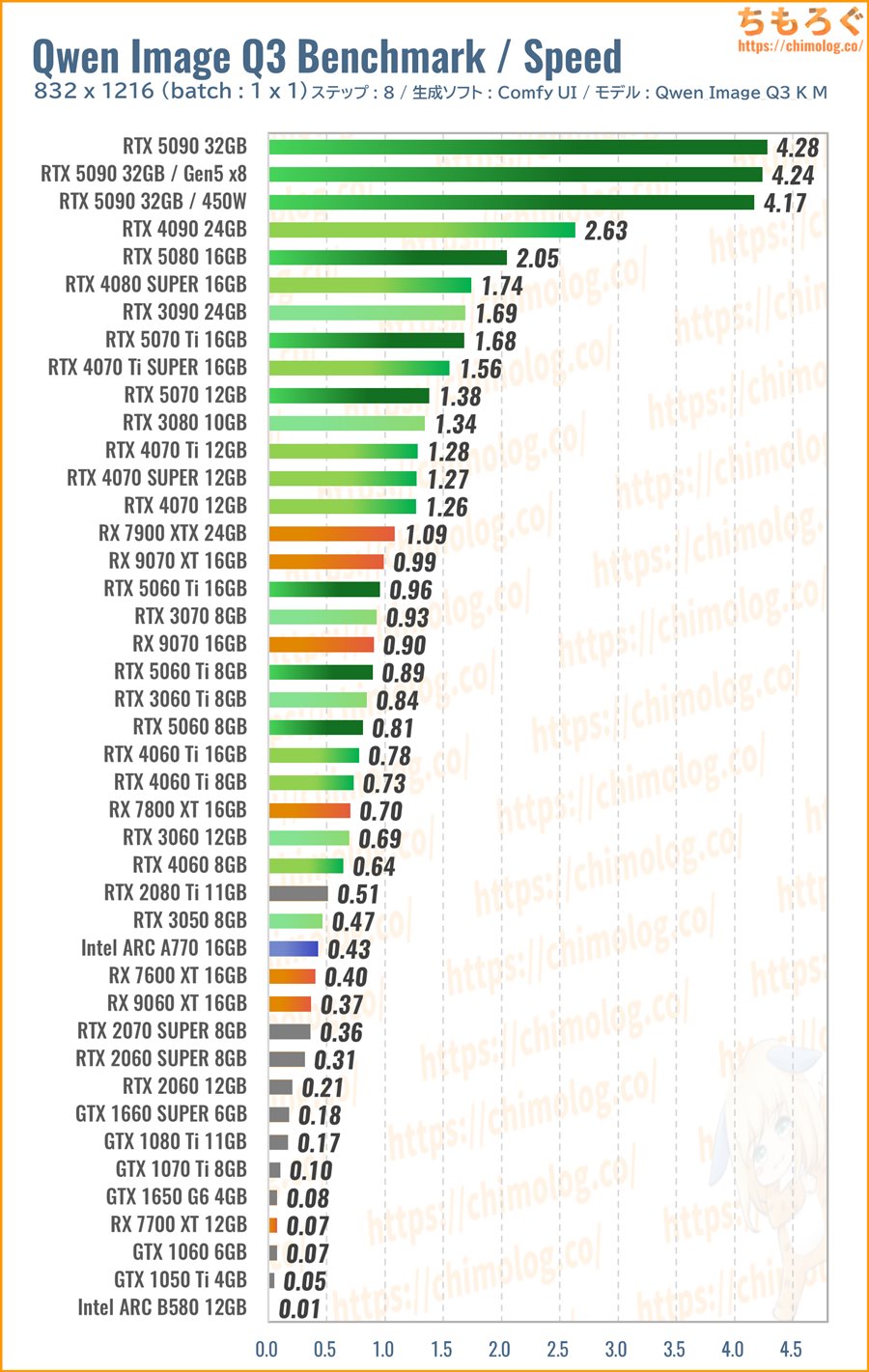
832×1216:Qwen Image Q3ベンチマーク

- 生成モデル:Qwen_Image-Q3_K_M.gguf
(https://huggingface.co/QuantStack/Qwen-Image-GGUF/) - 翻訳モデル:Qwen2-VL-7B-Instruct-Q3_K_M.gguf
(https://huggingface.co/tensorblock/Qwen2-VL-7B-Instruct-GGUF/)
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | Create a semi-realistic anime scene of a beautiful teenage girl holding up a graphics card to the camera. There are two cooling fans for the graphics board. | ||
| Negative | |||
| 各種設定 | |||
| sampling method | Euler | sampling steps | 8 |
| Width | 832 | Batch count | 1 |
| Height | 1216 | Batch size | 1 |
| CFG Scale | 1 | ||
| Seed | 1050008 | ||
- ComfyUI用
ワークフローをダウンロード
中国アリババから公開された、最新世代の画像生成モデル「Qwen Image」を軽量化した「Q3_K_M」版をテストします。

現在主流の「SDXL 1.0」世代は3.5億パラメータ(3.5B)ですが、「Qwen Image」は約7倍近い20.0億パラメータ(20B)を誇る超巨大モデルです。
自然言語を正確に理解する驚異的なプロンプト追従性と、英語と中国語をほぼ間違いなく描写するテキスト生成能力を備えます。
たとえば
「グラフィックボードの闇取引をします。ニューヨークの物騒な感じ。背後にタンクトップを着た黒人を2名配置し、左の男に"Qwen"、右の男に"Benchmark"と英語で書いてください。中央にグラフィックボードを差し出す日本風アニメ美少女を配置してください。持ってるグラボはデュアルファンモデルです。美少女の左手に緑色のマニキュア、右手に赤色のマニキュアを塗ってください。」
などなど、長ったらしい自然言語をおおむね理解して、かなり正確に生成可能です。
当然ながら、これほどの性能を出すためにモデル本体だけで約41 GBにもなる巨大サイズで、RTX 5090にすら収納できません。
一般的なコンシューマ向けグラボでQwen Imageを扱うには、生成品質をなるべく維持しつつ、サイズをシュリンクさせた量子化モデルの出番です。
今のところ、Qwen Imageに対応した分割タイルモードが見当たらないので、そこそこ軽量で精度もいい「Q3_K_M」版でベンチマークします。

(※クリックすると画像拡大)
生成時間(秒数)の比較ベンチマークです。
生成サイズ(832 x 1216)の割に、負荷が妙に重たい傾向です。1枚あたり10秒を切ったグラボがRTX 5090のみ。
RTX 4090以下は揃いも揃って10秒すら切れません。生成モデルだけでなく、翻訳モデル(テキストエンコーダー)も処理するせいで、SDXL 1.0よりずっと時間がかかります。
Radeonに対して一貫して強かったIntel ARCも、Qwen Imageを相手にすると苦戦気味。しかも、VRAMから少しでも漏れれば、まともに動作できません。
少ないVRAM容量でやり繰りする能力において、GeForceがやはり猛威をふるいます。
VRAM容量が8 GBしかないRTX 5060ですら、2倍のVRAMを持つARC B580やRX 9060 XTにダブルスコア(約2倍)の性能差を叩き出します。
- Q3_K_M版:RTX 5060以上
- Q4クラス:RTX 5070以上
- Q6~Q8版:RTX 5060 Ti 16GB以上
Qwen Imageはまだ分割VAEエンコードを使えないため、基本的にVRAM容量がモノをいいます。サイズが大きい量子化モデルほど、要求されるVRAM容量も増えます。
(※クリックすると画像拡大)
生成速度(1秒あたりステップ数)の比較グラフです。
RTX 5090がRTX 4090に対して約1.6倍もの生成速度を記録します。両者の最安価格に約1.3倍の開きがあるから、見事にコストパフォーマンスの逆転が起こっています。
単純なコスパならRTX 5070が強いです。PCIe 5.0バス(最大32 GT/s)に支えられ、計算性能でやや負けているはずのRTX 4070 Tiを上回る性能を維持します。
VRAMが不足しやすい環境下において、ComfyUIはVRAMとメインメモリをうまく使います。しかし、メインメモリに移動するときにPCIeバスを通過するため、PCIe帯域幅がモロに効いてる傾向です。
- RTX 5070以上:PCIe 5.0 x16(最大32 GT/s)
- RTX 4070以上:PCIe 4.0 x16(最大16 GT/s)
帯域幅はなんと2倍です。
Qwen Imageなど、生成モデル + 翻訳モデルを必要とする巨大モデルを使うなら、なるべく新しいバス規格(Gen5以降)のグラボをおすすめしたいです。
まとめ:AIイラストにおすすめなグラボ【3選】
今回のベンチマーク調査で、SD 1.5世代からSDXL 1.0世代の複合的な処理、そして最新世代Qwen Imageまで。パターン別の画像AI生成性能が判明しました。
では、難易度の高いベンチマークを中心にコストパフォーマンスを計算して、「AIイラストにおすすめなグラボ」を絞り込みます。
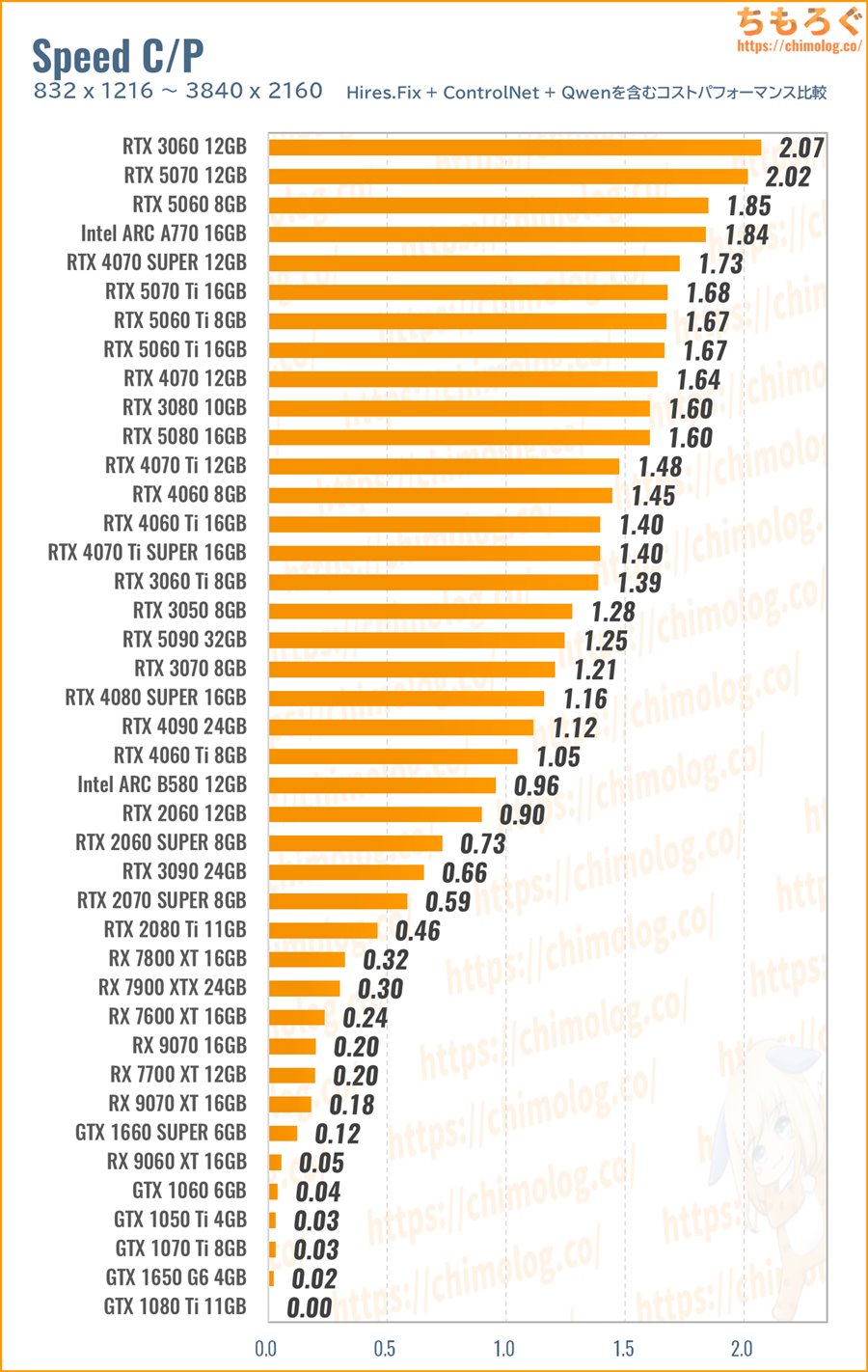
(※クリックすると画像拡大)
Radeonシリーズは議論の余地なく論外です。Intel ARCシリーズも悪くない戦いぶりでしたが、VRAM不足とPCIe x8が災いして今ひとつな結果に。
結局、欲しい性能や予算に合わせて、RTX 50シリーズから選ぶだけです。
- 832×1216:神里綾華(10バッチ)ベンチマーク
- 832 x 1216:神里綾華(ControlNet)ベンチマーク
- 1664 x 2432:ヘルタ(Hires.Fix)ベンチマーク
- 3840 x 2160:ヘルタ4K(Hires.Fix)ベンチマーク
- 832 x 1216:Qwen Imageベンチマーク
以上のベンチマークで取得した「生成速度(it/s)」を、まとめて幾何平均(Geomaen)に変換して、レビュー時点で入手可能な新品価格で割ってコスパを求めます。
- 生成速度の幾何平均 / 新品価格 = コスパ
支払った金額あたりの生成速度が高いグラボほど、コストパフォーマンスが良好です。
VRAM容量が考慮されていないのでは? ・・・もちろん、VRAM容量もすでに織り込み済み。重量級の4K Hires.FixやQwen Imageをきちんと幾何平均の中に含まれます。
逆にVRAMがほとんど関係ないハローアスカや連続キューテスト(1 x 10 batch)を、幾何平均から省いています。ComfyUIの巧みな省VRAM性に支えられ、以前よりVRAM容量による性能差が出づらい傾向です。
RTX 3060 12GB:AIイラスト向け入門グラボ


AIイラスト入門におすすめなグラフィックボードが「RTX 3060 12GB」です。
もちろん、筆者やかもちも驚いています。まさか2025年にもなって、未だにRTX 3060 12GBがAI生成用途にしぶとく生き残る性能を持っているなんて・・・。
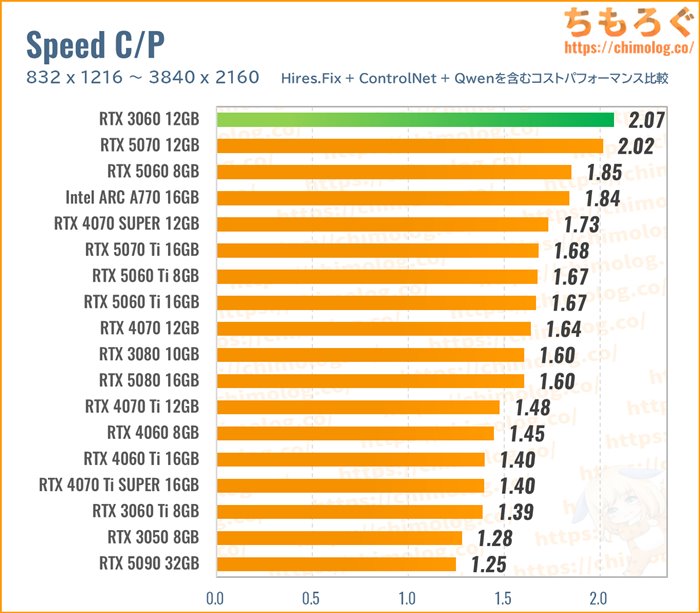
4K解像度(Hires.Fix)やQwen Imageも含む、重量級コストパフォーマンス計算※から、RTX 3060 12GBが頂点を収めます。
※ ハローアスカ(512)と神里綾華XL(832)を含まない計算。
RTX 3060が意外な勝利を収めた原因は、おもに3つです。
- PCIe x16バスを搭載
- VRAM容量が12 GB
- 新品価格が3.5万円~
約3.5万円から買えるリーズナブルな価格設定ながら、PCIe x16インターフェイスを備え、RTX 4060 Tiすら超える約360 GB/sの帯域幅があります。
要するに価格が安いです。安い割にお値段以上の仕事をこなす(= 高コスパな)グラボです。
予算3万円台でSDXL 1.0世代のアップスケーリング(Hires.Fix)から、時間はちょっとかかりますが最新世代のQwen Imageまで、一通り安定して動かせます。
まさに生成AI入門モデルに相応しいグラフィックボードでした。
RTX 5070 12GB:快適なAIイラストに最適なグラボ


RTX 3060はあくまでも入門向けモデルで、正直なところ生成速度そのものは結構遅く感じます。
10万円を超えない現実的な予算感の中から、AIイラスト生成に適したグラボを選ぶなら、やはり「RTX 5070」を推したいです。
RTX 5070の重量級コストパフォーマンスをあらためて確認します。
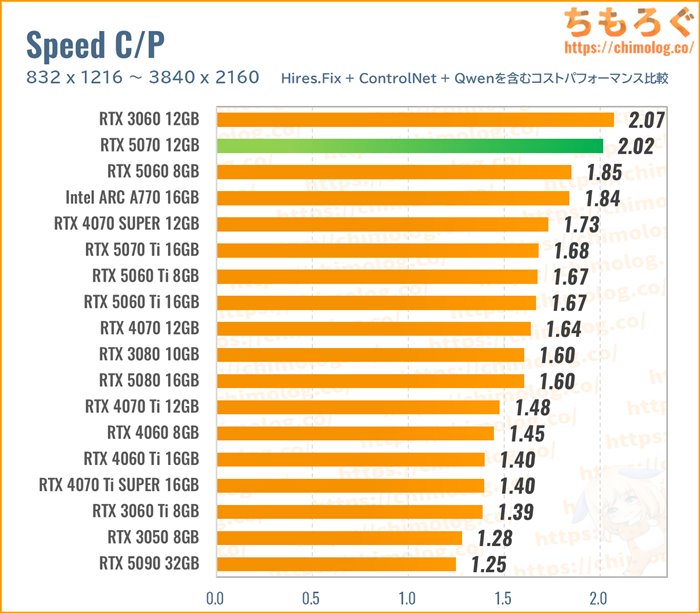
約7~8万円の価格帯で異質なコスパを放っています。一般的に、価格が高いほどコスパが下がる指標ですが、RTX 5070は価格の上昇に性能が追いついてきます。
価格が上がった分だけ、性能もきちんと伸びているから、コストパフォーマンス(性能 / 価格)が高いです。
ちなみに、RTX 5070がとてもリーズナブルな要因として、動画投稿サイトにおける不審なネガティブキャンペーンを挙げられます。
不自然なほど対抗陣営(主にRadeon)を持ち上げて、実態以上にRTX 5070を低く評価する風潮のおかげで、RTX 5070を非常にコスパよく買える状態です。

(ComfyUI-MultiGPUノードで使う予定)

おかげさまで筆者も2台目を7万円台で導入できました。
コスパが悪いと評されるRTX 50シリーズの中で、RTX 5070は特異点と言っていいレベルで「革ジャン唯一の良心的モデル」です。

(Hires.Fixで4000 x 2140)

(Hires.Fixで4000 x 2258)


RTX 5090 32GB:価格差に見合った「最速のAIグラボ」


コンシューマ向け(業務向けを含まない)グラフィックボードで、現行最速モデルが「RTX 5090 32GB」です。
他製品でほとんど替えが効かない唯一無二の性能を誇る、文句なしの最強グラボです。予算に糸目をつけず最高のAIグラボを買うなら、RTX 5090 32GBで決まりです。
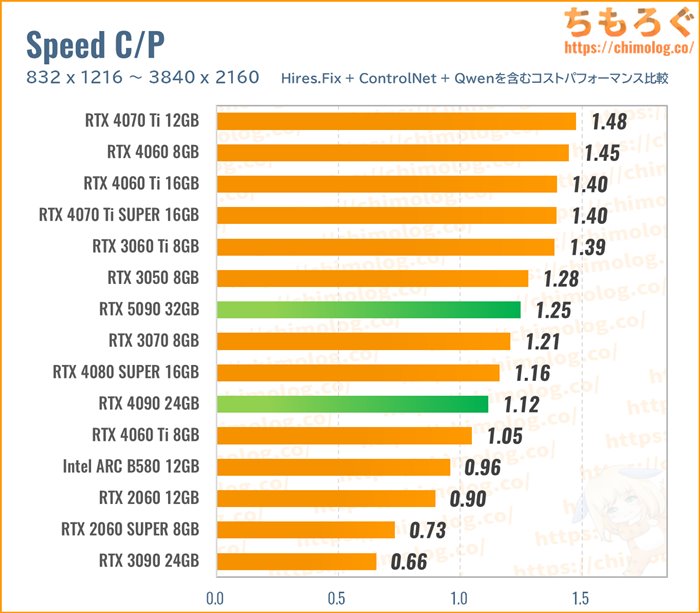
4K Hires.FixやControlNetモデル、Qwen Imageまで含む重量級コストパフォーマンス比較です。
価格が高いだけミドルクラスのグラボに単純なコスパで勝てませんが、体感性能はまったくの別次元。あまりにも処理速度が速すぎて、一度使うと・・・もう二度と下位グラボに戻れないでしょう。
なお、最上位モデル同士の比較なら、決してコストパフォーマンスも悪くないです。

(2025/08時点)
重量級タスクの処理性能であれば、RTX 4090に対して約1.3~1.6倍の速度を出せます。最安値ラインの価格差が約1.3倍ほどの開きにとどまるため、結局コスパで勝ってます。
VRAM容量が24 → 32 GBに増えた影響もあり、今後出てくる最新世代の画像生成モデルや、動画生成AI(Wan 2.2など)も安心して対応できる余裕があります。


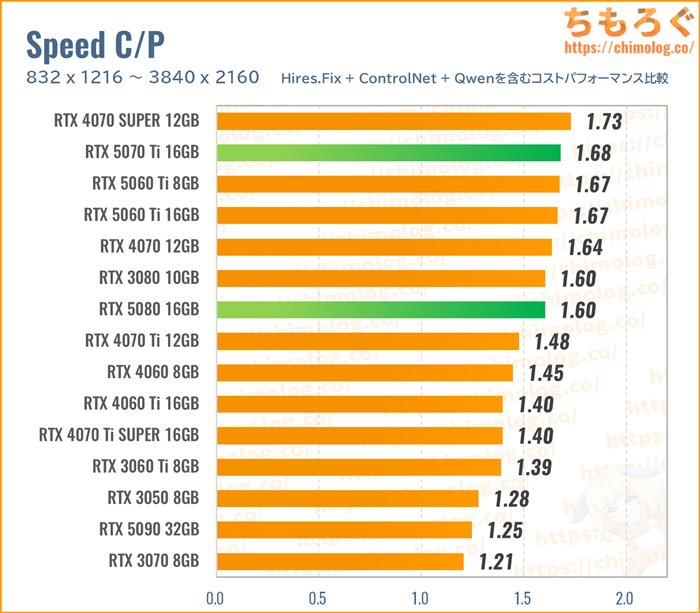
「グラボに30万円超えは非常に高い」と感じて当然なので、次点でRTX 5080やRTX 5070 Tiが候補です。
重量級コストパフォーマンスで見る限り、両者のコスパはほぼ拮抗します。パフォーマンス重視でRTX 5080を、コスパ重視でRTX 5070 Tiを推せます。


GeForce以外なら:Intel ARC B580が候補

宗教上の理由でGeForceを使えない方は・・・Radeonよりも、Intel ARCが有力候補です。
SDXL 1.0推奨サイズ(832 x 1216)で生成したり、Hires.Fix(Tiled VAE)で4K相当までアップスケーリングする程度なら、Intel ARC B580で問題なく使えます。
RadeonのようにMi Openに絡んだエラーもまったく経験なく、VRAM容量が足りている限り、不思議なほど安定して動いています。
- ComfyUI(Intel XPU版)
(https://github.com/ai-joe-git/ComfyUI-Intel-Arc-Clean-Install-Windows-venv-XPU-)
導入方法も驚くほどシンプルです。
pythonとgitをインストールした後、上記のページに書いてある内容をバッチファイルに入れて、順番に実行するだけで環境整備が終わります。
いったん動いてしまえばVRAM容量との戦いになるので、タスクマネージャーの共有メモリ漏れを見ながら、VAE分割サイズを適切に調整してください。

以上「【Stable Diffusion】AIイラストにおすすめなグラボをガチで検証【GPU別の生成速度】」でした。
動画生成AIにおすすめなグラボ

SDXLで生成した画像をヌルヌルと動かせる、最新の動画生成AIモデル「Wan2.2」におすすめなグラボ解説です。
全40枚のグラフィックボードで徹底的に検証しました。
生成AIタスクにおすすめなBTOパソコン

これからAIイラスト用にパソコンを用意するなら、基本的にBTOパソコンを推奨します。手っ取り早く完成済みかつプロが組み立てたパソコンを入手できます。
メーカー側で互換性を確認している、いわゆる最新パーツで構成されているから、旧世代のパソコン(メモリがDDR3世代)を延命するより安心です。
- 2023/03/08:Stable Diffusion Web UIのGPUベンチマーク結果をアップ
- 2023/03/13:RTX 4070 Tiのベンチマーク結果を追加
- 2023/03/14:RTX 4000(最適化設定)の性能を追加
- 2023/04/15:RTX 4070の性能を追加
- 2023/08/08:RTX 4060 Ti 16GBの性能を追加
- 2023/08/09:SDXL 1.0のベンチマーク結果を追加
- 2024/02/08:RTX 4070 Superの性能を追加
- 2024/02/09:SD 1.5、SDXL 1.0、Forge版のベンチマーク結果を更新
- 2024/04/03:RTX 4070 Ti Super / RTX 4080 Superの性能を追加
- 2025/08/24:全ベンチマークを刷新 / Qwen Imageの結果を追加(UPDATE !!)
画像生成AIのPCスペックでよくある質問
CPU側のオーバーヘッドが生成速度に与える影響はとても軽微です。
しかし、ComfyUIやReForge Web UIの場合、VRAMとメインメモリを往復する処理が多いです。その経路となる「PCIe世代」が性能に響いてきます。
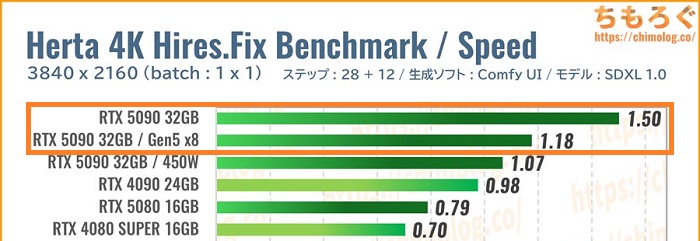
RTX 5090で検証しました。
PCIe世代がGen5からGen4に下がり、帯域幅が最大32 GT/sから16 GT/sへ減った場合、約20%も速度が下がるケースもあります。
PCIe 5.0対応グラボなら、マザーボードとCPUもPCIe 5.0対応モデルが相応しいでしょう。逆にPCIe 4.0対応グラボだったら、無理にPCIe 5.0世代のパーツへ移行しなくても問題なし。
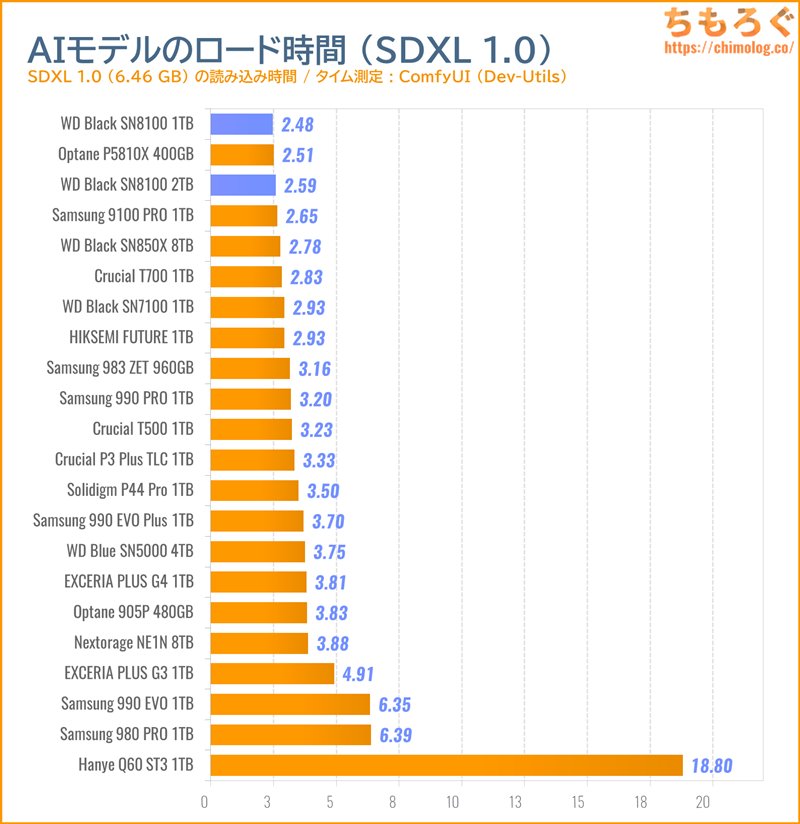
シーケンシャル性能が速いSSDほど、生成モデルを速く読み込めます。
SDXL 1.0モデルの場合、Gen5世代が2秒台、Gen4世代は3~4秒台です。SATA SSDだと約20秒まで伸びます。
コスパ的にGen4世代の定番SSDで十分です。迷ったら「SN7100」をおすすめします。


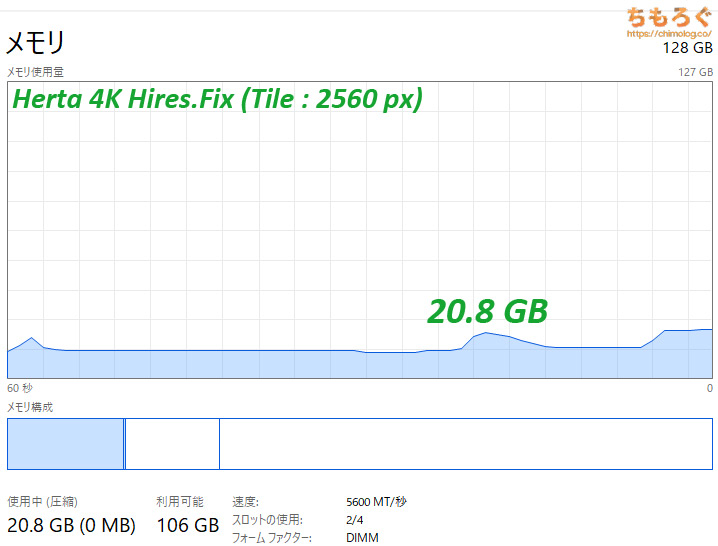
「ヘルタ4K Hires.Fix」ベンチマークで、ピーク時に約21 GBです。
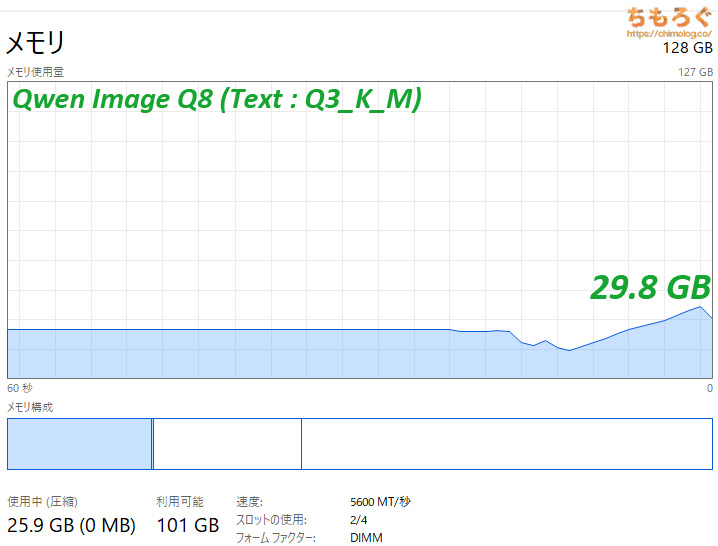
「Qwen Image」ベンチマークにて、生成モデルをQ8版に切り替えてテストしても、ピーク時に約30 GB程度です。
- 画像生成だけ:メモリ容量32 GB
- マルチGPUで複数同時:メモリ容量48 GB
- 動画生成(Wan 2.2):メモリ容量64 GB以上
画像生成メインなら容量32 GBで間に合います。












 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選

 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


詳細なデータありがとうございます。
最近の高性能CPUやGPUは私の使用目的では勿体なさ過ぎると感じていましたが、こういう使い方をする人にとってはわずかな出費の違いがパフォーマンスにものすごい差を示すのですね。
現在RADEON用にnod-ai SHARKが有るので
もう少ししたらまともに使える様になるかしれません
検証お疲れ様でした
赤と緑ではライブラリに雲泥の差が有り
AIに関してはcudaの牙城が大き過ぎますからね
AMDが一朝一夕に追いつける物ではない
AI用途だと3060(12GB)>3060Tiという下剋上が発生するのかと思いきや
「VRAMありき」と世間が言うほどでは無いみたいですね。
次回の学習編でそれが覆るのか楽しみです。
3日前にAIをはじめて触ったんですけど
rtx3070のvram8GBだと、容量が大きい学習モデル同士のマージでエラーが起きたり
容量が大きい学習モデルを使用している場合、学習モデルの切り替えでエラーがおきたりと、VRAMを使い切ってエラーが発生するケースがわりとあって
特に学習モデルのマージはAIイラストをやりこむ上でかかせないので
VRAM8Gだと結構ストレスに感じます
某PCショップ中古のRTX3070が4万台だったので気になっていたけど
この書き込みがすごい参考になりました、ありがとうございます
4060Ti 16GBが出たあとにレビューを見てから、4070Tiにするか決めたいと思います
StableDiffusionは速度に関してはVRAM容量よりVRAM帯域幅とfp16演算性能が重要なので覆ることはないでしょう。
とはいえ3060はVRAM容量が大きい分解像度を上げたりBatch sizeを上げられるメリットがあります。
3060(12GB)と3060Ti、どちらがいいのでしょうか?
いや…ここまで記事まで読んでそれを聞くとか…
分からないなら素直におすすめの方を買えばいいと思う
きも
検証おつでした
ブルプロの時も思ったんですが1660と3050って結構差が出るんですねぇ
ゲームやベンチ的なのだと同等と思ってたので意外でした
RTX 3000シリーズはTensorコアが搭載されたので、こういった機械学習系の用途だと性能が伸びやすいですね。
今後のアップデートでRTコア(レイトレ用)の演算性能も活用できるようになるらしいので、まだまだ伸びしろがありそうです。
各グラボでBatch sizeを最大まで上げた場合の効率も知りたいです。
組み合わせが多すぎるので、グラボの数を絞って検証する予定です。
私はこれほど多くのGPUで比較できず感覚的で申し訳ないですが、Batch sizeが4程度に大きい方が1枚あたりの時間が短く、並列数を上げるにはVRAMがより必要、と理解しています。
特にRTX4090は伸び幅が大きいように思います(ハローアスカは5×2生成で9秒を割ります)
とても参考になる情報ありがとうございます。
実際にバッチ回数 x バッチサイズを変更して、いくつかベンチマークを試したところ、VRAM消費量が1~2 GBほど増える代わりに、イラスト10枚分の描写時間がかなり短縮できました。
特に「512×768:LoRA + ControlNet」では、約46%もの高速化で割りと衝撃的です。
バッチ1回毎にメモリデータの初期化などで読み出し作業が入ってるんですかね。
1*10だと10回初期化して、2*5だと5回って感じで。
検証するなら、HDDとSSDで差が生じるのか、PCメモリの速度に依存するのか、学習モデル毎に差はあるのかとかですね。
期待してます。(他力本願)
お絵描きAIの影響で
GPUにもがっつりVRAMほしいという需要が発生してますね
グラボを30枚も持っているなんてすごいですね。自分も気になるのは買ってもいいのかと錯覚してしまいます。危ない。
正直、本気でやるなら速度よりvramが大事
解像度あげると絵のディティールもアップするし、アップスケーリングは違和感ある
ただ3090はvramの熱問題あるから自分で分解してグリス塗り直してサーマルパッド交換、追加してヒートシンクくっつけてファンも取り付けられる人にしかおすすめしない
結局バランスの4080か性能の4090か、コスパの4070になる
ASUS3090TUFでsdxl1.0で1024×1024ポートレイト量産してる勢だが熱は全然問題無いけど電気料金の方が怖いけどね
前から3090は熱が酷い連呼良く聞いてたけど正直CPUの方がよっぽど熱出してるわ、3090だろうと熱問題は出してるメーカー次第でしかない
3090もノーマルのままで大丈夫なモデルも割と普通にありそうですよ。
4070Tiの12GBが選択肢に入る使い方なら、3080Tiもいけますね。
ちもちゃんを作りたい
リストが途中から1650Superから1660Superに替わっているんですが?
入力ミスでした・・・。
今回は「GTX 1650 Super」をテストしていないので、全部「GTX 1660 Super」が正しいです。間違ってるグラフを修正します。
RTX4系はワッパも書いた方がいいですよ
特に4090と4080は値段差を電力効率で埋めてしまえる程ですので…
検証記事を作成いただきありがとうございます。NVIDIA/AMD両陣営を横並びで比較した記事はあまり見かけないので、興味深く拝見させていただきました。
1点気になったこととして、現在”–xformers”オプションでインストールされるxformers、およびデフォルトで使用されるPytorchはRTX4000番台(Ada Lovelace世代)に最適化されていないため、そのままでは本来より低い性能しか出ません。
このコメント通りに新しいバージョンのxformers・Pytorchを導入すると、概ね1.5倍程度の性能を発揮するようになります。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/2449#issuecomment-1404540735
私の環境はi5-13600k + RTX4090(Powerlimit 75%)ですが、
記事中のHello Asuka Testでは33.2it/s、Ayaka Benchmarkでは19.1it/s程度が安定して出ています。
もちろん「インストールしたてのカスタムしない状態での比較検証」ということでしたら記事内容に誤りはないのですが、RTX4090を買うようなひとはきちんと最適化も行うのではないか。Ada Lovelace世代とそれ以前の世代の性能差を比較するという観点であれば、きちんと性能を発揮できる環境を整えて検証した方がいいのではないか・・・と考える次第です。
差し出がましいことを申し上げました。今後も記事を楽しみにしております。
参考になる情報ありがとうございます。
AD世代の最適化設定はけっこう複雑ですね。cuDNNを置き換えただけで満足してた(これで約1.3倍)のですが、他にもあっととは。試してみて見て効果があれば、グラフに「4090 最適化設定」という感じで追記します。
ご返信ありがとうございます。記事のアップデートを楽しみにしています。
ところで、sd-extension-system-info という拡張機能はご存じでしょうか。
CPUやGPU、インストールされている各種ライブラリのバージョン情報などを確認するツールですが、
ベンチマーク機能も搭載されており、ワンクリックするだけで画像生成の速度を計測することができます。
自動的にバッチサイズを変えながら生成速度を計測できるほか、様々な要因でスコアが低下してしまう初回生成のみ計測結果から除外するウォームアップ機能、オンラインでのスコア投稿・閲覧機能などもあります。
(有志が送信したスコアはこちらから一覧でき、CPUやGPU、使用するライブラリ等のバージョンから絞り込むこともできます https://vladmandic.github.io/sd-extension-system-info/pages/benchmark.html )
他の方のコメントで、バッチサイズを変えた場合のテスト結果を記事にまとめる・・・というようなことを書いていらっしゃるのをお見かけして、記事執筆のお役に立つのではないかと思い付いた次第です。
よければお試しください。
コメントありがとうございます。
教えていただいた情報をもとに、torchとxformersをビルドし直しました。
・torch: 2.1.0.dev20230311+cu118
・xformers: 0.0.17+b6be33a.d20230313
結果、RTX 4090が28.7 it/s → 35.3 it/sまで性能アップ(約1.2倍)、16000コアに見合う性能に近づいた感じです。ここまで性能が上がると、RTX 4080よりRTX 4090の方が優位ですね。
Web UI拡張ベンチマークはおいおい試してみます。
補足:
Pytorch2.0.0が正式公開されました。Pytorch2.0.0にはxformers的な機能が含まれているため、自前でxformersをビルドする必要がありません。
最新ビルドのxformersと比べて性能が劇的に上がるわけではなく(環境によってはちょっとだけ向上するらしい?私の環境では1~2it/sくらい上がりましたが誤差かも)、GTX1000番台くらいの古いGPUではxformersを使った方が高速だという噂も聞きますが、参考までに導入方法をお知らせします。
0. もしまだなら、Python3.10.x最新版とCUDA Toolkit 11.x最新版をインストールします。(コメント執筆時点では、それぞれPython3.10.11とCUDA Toolkit 11.8.0)
1. venvフォルダを削除します。
2. Stable Diffusion webuiを最新版にします。
3. webui-user.bat(またはwebui-user.sh)を以下のように書き換えます。
—-
@echo off
set PYTHON=
set GIT=
set COMMANDLINE_ARGS=–opt-sdp-no-mem-attention –opt-channelslast
set TORCH_COMMAND=pip install torch==2.0.0 torchvision –extra-index-url https://download.pytorch.org/whl/cu118
call webui.bat
—-
4. webui-user.bat(またはwebui-user.sh)を実行します。
ようは、–xformersのかわりに–opt-sdp-no-mem-attentionをつけ、TORCH_COMMAND行を追加するだけです。
なお、–opt-sdp-no-mem-attentionではなく–opt-sdp-attentionを指定してもかまいません。
公式ドキュメントによると、–opt-sdp-attentionのほうがわずかに早いと書いてありますが・・・私の環境では違いがわかりませんでした。
むしろ、同じseed値でも生成するたびに出力画像がわずかに変化してしまうので、–opt-sdp-no-mem-attentionのほうが実用的かと思います。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations
また、必要に応じて、その他のオプション(–no-half-vaeとか)などをつけてもかまいません。
私の環境では”set COMMANDLINE_ARGS=–opt-sdp-no-mem-attention –opt-split-attention –opt-channelslast –no-half-vae”としています。
イラストAIも長足の進歩を遂げており、情報をアップデートしていくのは大変かと思いますが、様々なGPU・環境を網羅的に検証いただけるちもろぐさんの記事は本当にありがたいです。
今後とも新規記事・記事のアップデートを期待しております!
こちらの変更方法を記事化していただけると嬉しいです。
RX570 8GBで768×768で問題なく出力出来てますけど、6600XTだと何で落ちるんでしょうね?
ちなみにRadeonでは–medvram等は今のところ効果が無いので、512×512でもVRAMエラーで落ちますね。
※RX570では–opt-sub-quad-attention –no-halfにしないと512×512も768×768もVRAMエラーで落ちました。(元々FP16非対応)
※xformars等もGeforce用なのでエラーの原因になる事があります。
Ryzen APUの場合はBIOSのVRAM設定を512MBから2GBに変更しておかないとBSODになる等、いくつか注意点があります。(gitに注意書きがあります)
あとはメモリを64GB増設しておけばVRAM32GBまで使えるので問題無いでしょう。
グラボのVRAMをOSや他アプリに使わせたくない場合は、iGPU付きCPUを選択した方が良いです。
そうしないとお絵描き中にYoutube等を開いたりするとVRAMが消費されますのでお絵描きがエラー落ちする原因になります。
お絵描きをGPU割り当てする場合はPython.exeをWindowsのGPU割り当てでグラボに割り当てる事で可能です。
firefox.exeやchrome.exeはiGPUに割り当てましょう。
少しでもグラボのVRAMを空けることで落ちにくくなります。
スタート→ゲーム→ゲームモード→グラフィック→アプリのカスタムオプション→アプリを追加する
[特定のGPU: RX570] C:\Users\User名\AppData\Local\Programs\Python\Python310\python.exe
[特定のGPU: RX570] C:\stable-diffusion-webui-directml\venv\Scripts\python.exe
僕はLinux+ROCm環境ですが、こちらも–medvramの効果がありませんでした。(RX 5500 XTを使用)
まさかmedvramもxformars同様にNVIDIA専用なのでしょうか? 公式レポジトリの引数解説にはそのような説明はありませんでしたが…
これから購入する人は3060は12GB版じゃない奴があるから気をつけろよ
エンコードのために1060->1660superにしてしまったがAIお絵描きでは1060の方が優秀だったとは…FP16バグが憎い
Loraあたりで学習編も期待してます
主要なグラボだけでいいんで
学習画像512×512,batch size 1での速度/512×512での最大batch数/batch size 1での最大サイズあたりがわかるといいんじゃないかなー
FP16バグを回避するために入れた起動オプション「–no-half」がかえって動作を不安定にしている気がします。
GTX 1060は描写時間こそダラダラとかかりますが、VRAMエラーを吐かずに最後まで出力できます。ただ、これから買うならRTX 3060 12GBの方が良いと思います(※なお、8GB版は安いけどAI目的なら買わない)。
40シリーズは全体的にワッパも良いよねー
lora回してるとやっぱり12GBある方が安心感はあるよね。バッチ数とかを増やせるのは嬉しい。
10万以上の資金を準備できないなら3060の12GBモデルを買うべきだと思う。
A4000みたいなのも気になる
横から失礼
海外で検証している人がいました
https://lambdalabs.com/blog/inference-benchmark-stable-diffusion
機械翻訳でザッと読んだ感じ、巨大なVRAMはバッチサイズを大きくしたときに効果的、といった内容ですね。
興味深い内容ではあるものの・・・、値段を見るとなかなか手が出せないですね(eBayのUsed品で約40万円ほど)。
検証お疲れさまでした。
非常に参考になりました。
先月末あたりから、ChilloutMixというリアル系高解像度AI画像生成モデルが出て1920などで生成するので、4090や3090/3090Tiの比較に役立つかと思われます。
検証お疲れ様です。
要望なのですがアホな自分のためにtorchとxformerをリビルドした流れをまとめてもらうと大変助かります。
My small addition to the 512×512 test with my RX 470 4gb with directml version of autmatic1111 (Win10) – Time taken: 20m 39.93s – 1239,93 seconds 😀 I really need to switch to nvidia and I’m thinking about buying a used 1070.
とても参考になる検証、記事をありがとうございます。
12GBのグラボ購入をしてみたくなりました。
技術的にわかっていないことが多くて恐縮ですが、12GBグラボを2枚差しにすればワットパフォーマンスは悪いですが、上位グラボに迫れるのではと妄想しました。
スクリプト側がうまく対応できていないのかもしれないですが、いくつかの作業だけでも担えるなら価値はあるのかなと思いました。
グラボのSLIでメモリ増やしたりは、ゲーミング向けのGeForceでは出来なくて、業務向けのTeslaやQuadroなどの上位機種ではメモリを共有出来るのでA100を複数使って数100GBのメモリを持ったお化けマシンで学習などされてます。
メモリが多くできない一般ユースのGeForceでは複数差しのメリットがないので、SLIで処理性能アップではなく、各グラボに個別の学習データ渡して其れに書かせるって感じになるのかなぁって思います。
表向きはSLIが要らないぐらい性能が上がってるからとか、言われるんですが、一番の理由は安い一般ユース品ではなく業務向けのバカ高い奴買えって事ですね。
ざっと調べた限り、複数のGPUを並列化してAIイラストの生成や学習を行う方法はなさそう?
BlenderやV-ray等、レンダリング系はそのまま挿すだけで並列化ができるので、進化が速すぎる今の機械学習界隈なら近いうちに対応しそう・・・。
PC Watchの西川さんのコラムでちもろぐさんがサラッと紹介されてました。
https://pc.watch.impress.co.jp/docs/column/nishikawa/1485422.html
今気づきました、紹介リンクのある記事はこっちでした。
https://pc.watch.impress.co.jp/docs/column/nishikawa/1487845.html
(ローカルで画像生成AIや大規模言語モデルを動かしたい!Google ColabからRTX 3070 Ti+GPU Boxへ乗り換え!? 西川 和久 2023年3月27日 06:14)
ここの下のほう「512×768:神里綾華ベンチマークのサイトより」の紹介リンクが、ちもさんの記事への直リンクになっていました。
本当に参考になる記事。
この記事だけでもRTX4070Tiを買いたくなるけど、今後書かれる予定の学習速度の記事を見て決めます。
AI絵師(笑)とか言いつつ実際はなんかのトレスかアニメキャラ〇人合成したやつしかできないのやめれ
まあ数年前の抽象画しかできなかった時よりは進歩してるんじゃね()
なお今のトレンドは生身絵師同士のトレパク冤罪吹っ掛けの模様
性悪に金と個人情報渡すならAIでええわ
顔真っ赤になっちゃった(笑)
こんな返信にしかできない時点で、ね
台湾のRTX6000 AdaのAI画像生成レビュー出たので参考にどうぞ
https://www.coolpc.com.tw/tw/shop/gpu/nvidia-rtx-6000-ada-generation/
Linuxでしか動かないのがあれですがRadeonはROCmを使わないと性能出ませんよ。確かWSL2でも動いたはずなので試してみてください。
ただセットアップが地味に難しいんですよね。
環境のところにROCm使っていると書かれていますよ
ついにWindowsにもROCmが来るみたいですよ!
https://www.tomshardware.com/news/amd-rocm-comes-to-windows-on-consumer-gpus
これでRadeonでもAIをぶん回せるかも?VRAMが多いのが生きるといいですね
ありがとうございます。
とても分かりやすく参考になりました。
RTX2060 12GB購入を決意しましたw
先日発売された4070のスコアも追加していただけると嬉しいです。
多分コスパでトップだと思われます。
NVIDIAの最強グラボA100 80GBで検証してほしいですね。
個人購入できる代物じゃないから検証はクラウドの時間貸出とかでしか無理なのでは?
そもそも、レビュー対象になっていても困惑しそう。
むしろ、時間貸しの方法やその環境での実装方法をまとめてもらった方がありがたいですね。
VRAMの必要量が学習方法の進展によって結構変わりそうでなかなか難しいですね
一時期のdreambooth方式の学習だといくらあっても足りなかったけど、今はまあ最低8GB、できれば10GBあればほとんどの用途で不足はないですからね
いきなり高価なグラボで躓いたらもったいないので、最初は3060とか比較的安価なグラボで色々触るのがいいんじゃないかなあと思う
うわぁ、この早さで4070のデータ更新してくれたいありがたい!!!
4000番台は4090以外は物凄くコスパが悪いです
それなのにコスパ良く感じるのは前の世代がマイニング需要で高騰したせいで殆ど定価から値下がりしてないからです
1000番台2000番台の価格や性能アップを考えたら詐欺に等しいです
コスパ 4090は25万円するので、他の4000も実はそれなりで寧ろ逆なことも多そうですが。
たしかに「RTX 2080 Tiが6万円で投げ売り!」みたいな値下がりがほとんど見られないですね。マイニング需要はほぼオワコンですが、それでも値段が下がらないのは販売店の値段感覚がマイニング特需のせいでズレてしまった可能性は、たしかに有り得そう。
ただ、当時から大幅に円安が進んでいることも考慮した方が良さそうです。
仮に円レートがRTX 3080発売時(初売で95700円)から固定されていた場合、RTX 4070は82010円スタート、RTX 4070 Tiなら109390円スタートと計算できます。ここに楽天やヤフショのポイント還元を組み合わせると、それぞれ7万円台・9万円台で買えたはず・・・でした。
PNYの4070TiならPayPayポイント還元込みでの計算ですけど9万円代の時が一瞬だけありましたね
すみません(v17)とはどういう意味でしょうか?
(v17)はリビルドした「xformers version 0.0.17」を使った場合の性能です。ぼくのテスト環境だと、RTX 4000シリーズに関してはこの方が性能が出やすいので、RTX 4000シリーズはリビルド版xformersを使っています。
導入方法はこちらのコメント(#comment-98136)やコメント(#comment-99693)が参考になります。ぼくが導入した方法は#comment-98136の方です。
[…] そのような中で、「ちもろぐ」さんのグラボ比較記事がとても参考になりました […]
Windows Radeon環境だとDirectMLよりMLIR/IREEがかなり速いようです
nod-ai/SHARK: SHARK – High Performance Machine Learning Distribution https://github.com/nod-ai/SHARK
Lora有り
512×768 20step
で比較すると
Shark 700
1.5-2it/s
automatic 1111
0.2-0.6it/s
で確かにsharkが4倍以上速かったです。
ですが、VAEがエラーで使えなかったり、Loraが1つしか使えなかったり、強制終了したりしました。
加えて、起動時に毎回モデルの変換か読み込みを行っており、使えるまでに5分くらいかかります。
日々アプデが行われてますが、現在の最新版でもエラーがあり発展途上の印象です。
環境
windows 10
rx 6600 xt
i5 10400f
詳細な検証、参考になります。さて今、サイコムでは
・RTX A400 ¥194620<RTX 4080 ¥232320(共に16GB)
・Radeon 7900XTX ¥184160<RTX 4090 ¥347940(共に24GB)
ですが、stable diffusionでの性能はどんなものでしょうか。
ハローアスカの生成速度は
・RTX A4000:25~28秒
・RTX 4080:12~15秒
・RX 7900 XTX(ROCm 5.5 + Arch Linux):17~19秒
・RTX 4090:9~12秒
です。
RadeonはROCm版がWindows(もしくはWSL2)で動くようになれば、評価がかなり変わる予感がします。
現状は本家1111版の方が機能性(Tiles DIffusionやControlNet 1.1等)に優れていて、多様な表現に対応できるので基本的にGeForceで良いと思いますが、将来的にはRadeon(RDNA 3)が選択肢に入ってくるかもしれません。
すでにA4000で検証していたのですね、コメントを見落としていました。
たくさんの検証情報、ホント助かります!
pixivのAIイラストへの対策として規約改定を発表しましたね
リプ欄がAI絵師への憎悪が渦巻いていてすさまじい反響になってます…
これから始めるつもりの人蛇蝎のごとく嫌っている人も多いと認識して、特にネット上にイラストを上げることはくれぐれも注意されますよう
RTX3060買うより4070買ったほうがいいのか
NVIDIA H100での検証おねがいしたいですね。また、一台の時と複数台の時で変化がどれほどなのかも検証お願いします。
自分でやれ
ここ数日絵師がpixivで非公開にする人が続出してるのを見ると、AI絵師は宿主を殺す寄生虫みたいなもんだよなあって思わずにはいられない
技術の発展は凄いけど結局素材は余所から勝手に持ってきて生成するしかないから、無法地帯のstable diffusionは早晩行き詰まりを見せることになりそう
現状pixivやAIの書籍を取り扱っている所もどう対応していくのか…
他国と決定的に違うのはアニメや漫画文化で圧倒的に絵師の人数が多く、その絵師を支持してる人も多いため影響が桁違いだというところ
nijijourneyはそのへん良くわかっていて、版権などに酷似したものが生成された場合は報告して排除する仕組みがあるから独自の発展は遂げられるかもしれないけど
ここはAIイラスト作成のおけるグラボの比較情報を提供しているページであって、AIイラストの是非とかそんなのどうでもいいし見たくないんですけど。
子供じゃないんだから、もう少し時と場所をわきまえて戴けませんかね?
どうでもいいのにコメントは無視できなくて草
DLsiteやCi-en等次々にAI作品の停止措置を取らざるを得ない状況を少しは真面目に考えたら?
各方面でめちゃくちゃ損害出してるんだよ
まあそういう自分本位なやつばかりだからこうなってるんだけど
君の”負け”やで
ここはそれを話す場所じゃないでしょ?
と言ってるんですよ。
このページはあくまでも「グラボの評価」をしているところ。
AIイラストの是非をテーマにしたページではない。
そのあたりを話したいのなら、別のところでやってくれという話。
RTX4060TiのVRAM16GB版の噂が出てきたけどガチならAI用途に限ればかなり優秀な選択肢になるかもしれない
ファンボックスのAI生成作品禁止が来たね
まあ今の流れならそうなるだろうなとは思った
他の販売サイトが続くかどうか
さすがにlora実装以降は作風とキャラ学習のハードル下がったのもあって無法も過ぎた
お小遣い稼ぎのためにグラボ購入した人やしようとしてた人が少なからずいただろうけどどうなるかね
さすがにちょっとした遊びのために10万だすひとは少ないはずだし
今更やり始めても月に千円以下稼げるかどうかって感じだったしねぇ
自分は普通に好みのイラスト出力してみたいから買おうと思ってる
RTX4060ti 16G版のベンチマーク待ってます
VRAM 12Gと16Gで出来ることに変わりますか?
4060ti 16Gと3060 12Gで迷っています。
扱える解像度が変わってくる程度
高解像度になるほど大容量のVRAMが必要になるけど
VRAM8GBの3060Tiでも、解像度上げないなら処理速度は3060より速いから悪くないっていう程度
4060Tiが3060Ti~3070未満の性能しかないという噂なので、もしかしたら値段重視なら3060/3060Ti買った方がコスパ良い可能性もあるという
GTX1080からRTX4070tiに乗り換え、
個人的には早くなったと思っていました
ところがこちらのページを見たら大幅に遅かったことに気が付けました
cuDNNの更新などをしてスペック通りの速度が出せるようになりました
ここを見ていなかったらずっと遅いまま生成する所でした
ありがとうございます
ちもろぐ読者様
私もこのサイトを見てGPUどれにしようか考えています
たまたまこのコメントを見たのですが私もやり方がわるいのかちもろぐ様のベンチ通りしてもかなり生成が遅いのですが
cuDNNの更新というのが必須ということでしょうか?
CUDA Toolkit 12.2 Update 1 Downloadsというのを入れてみましたが速度は変わりませんでした。
なにかアドバイスいただければ幸いです
結局表をざっと見るに、現状は
GPUの処理速度 >>>メモリ容量
って感じですかね。
3060Ti 12GBが、3070 8GBを追い越すことが無いわけですし
PC Watchの西川和久氏が書いた記事に、このページへのリンクが貼ってありますね。
西川和久氏も見ているのか~!
最後のAyaka LoRA + Hires Fix Benchmarkのhires,fixのhires steps値はいくつになってますか? 記載してないのでデフォの数字になってるんだと思いますが、
自分の持ってるグラボと 最後のベンチだけが著しく違うのですが・・・「他はほぼ同じ」
この項目をいじるとかなり生成時間が変わるみたいです。
試しに「10」にすると まったく同じ結果になります
4060ti 16GBが3060 12GBと4070の間のどのあたりに入ってくるのかが気になって夜も寝れません
意外と3060に毛が生えた程度のモノかもしれませんね…
AIデビューしたいので検証お待ちしています
これはただの願望なのですが、外付けのGPUboxでRTX4090を使用したノートPCでどれくらいの速度が出るものなのか知りたいです。
RTX4090のデスクトップを買うか、出張が多いのでRTX4090のノートを買うかで迷っていますが、外付けのGPUboxという第三の選択肢があることに最近気づきました。が、そんなことをしている人がこの世に一人もいません。
静止画生成ならUSBで耐えられるかもしれんけど
動画とかみたくメインメモリとのやりとりが多く発生する使い方するならOculinkするんやで
(ノートでOculink端子出てることは少ないからケースに穴開けてm.2から引っ張り出す)
ノートPC用RTX4090(正式名称:RTX4090 Laptop)は、デスクトップ版RTX4080の低クロック版ですよ
外付けGPUボックスを使う場合、USB3.2Gen2接続(10Gbps≒1.25GB/s)かUSB3.2Gen2x2接続(20Gbps≒2.5GB/s)になると思いますが、転送速度はデスクトップのPCI-Express3.0 x16接続(31.5GB/s)より大幅に遅く、PCIe3.0 x1接続(2GB/s)と変わらないです。
AI関連はゲームと違ってバスの転送速度も大事なので、外付けGPUボックス(5万)+RTX4090(30万)を買うなら、RTX4090Laptopを積んだノートPCを買って荷物少なく持ち運んで遊んだほうが幸せかもしれないです。
[…] 【Stable Diffusion】AIイラストにおすすめなグラボをガチで検証【GPU別の生成速度】 […]
某所でxformersを入れない4090は3060に劣るって言ってる人いるんだけどそんな事ある?
3060と3060tiどっちがいいんだ〜〜
3060ti 12GBがあったら即決でそれ買ってたのに
しれっと4060があって草
3060Tiと良い勝負してんじゃん
TDPからすれば4060も十分ありでは?たった110wで大健闘
というか4060のレビューはよ
ROCmのWindows版が出たことですし、Radeonも巻き返せませんかねえ。
せっかくVRAM多く積んでることですし。
SDXLの検証ありがとうございます
VRAM8GBでも動作するComfyUIから1024×1024の生成時の性能比較も見てみたいですね
現時点で1111は12GBではSDXLが安定動作しないため実用レベルに達していません
画像生成速度はいいんですが、LoRA学習の速度の差とか分かりませんか?
やっと4060ti 16GBくんに人権が…
要らない子じゃなかったんや!
それにしてもこの量のグラボの計測ほんとお疲れ様です…気が向いたらで良いので7900xtxくんもいつか記事見れると良いなあ。
RADEONはVRAMの使用効率がかなり悪いのでかなり振るわない感じみたいですが、改善するのにまだまだ時間を要しそうですね。
今のところSDXLはcomfyUIでちょっとお試し程度で使ってる人も多いだろうけど意図通りの絵を作るならa1111の拡張を使いたいし
SDXLへの各種拡張対応が進んで来たら当然必要VRAM量も膨大になるわけで4060Ti16GBの評価はガラッと変わるかも
hello, thank you so much for all your benchmark it’s very important for the AI community (^_^) i live in france and i want buy a new pc for try sdxl 1.0.
i think about rtx 4070 or 4070ti but after see the result of 1600×1024 (so coooooool) i want know if it’s same result with 1024×1024 (if the 12go about 4070 and 4070ti it’s better than 4060 ti 12go) it’s possible add the result with 1024×1024 ? or just tell me wich is better with this resolution please 😉 i wait your anwser for buy my computer. thank you so much.
resume question: with better for sdxl 1.0 with 1024×1024 resulution ?
– rtx 4060ti 16go
– rtx 4070 12go
– rtx 4070 ti 12go
and how many % difference (or iteration value… or time in second)
best regards 😀
Hi, Aglo 🙂
(sorry, I’m not the author of this article page.)
He (Mr, Yakamochi) has been updating and verifying this page since March of this year.
in this time, the Results show that SDXL’s image generation performance and learning performance depend on the amount of VRAM.
So out of those three options, he concludes that the 4060Ti 16GB with 16GB of VRAM is better.
(Please read his opinion using translation site)
Hello, thank you for your anwser 🙂
yes i see all this benchmark, very big different with sdxl (1600×1024) thats’s why i ask the question about 1024×1024 because i want use this definition
1600×1024 = 1 638 400 Total Pixels
1024×1024 = 1 048 576 Total Pixels
1024×1024 to 1600×1024 = x 1,56 more Pixels… i want know if with 1024×1024 the 12 go of rtx 4070 or 4070Ti are very limited same like 1600×1024 or not ?
i Hope with 1024×1024 with 12go Vram the result it’s more like result of the begin benchmark (512×1024)
if the result of 1024×1024 it’s little same delta difference of 1600×1024 => i prefere buy Rtx 4090
if the result of 1024×1024 it’s little same delta difference of 512×1024 (not very limited with 12Go Vram) => i buy Rtx 4070 or 4070Ti
because with 1600×1024 the 4060 Ti 16go (550€) it’s better than 4070 Ti 12go (850€)
i’m very curious about 1024×1024 with 4060Ti 16go, 4070 Go and 4070 Ti 12Go.
Please give me the anwser 😀 possibly i give money for this result (Benchmark in SDXL 1.0 with1024x1024 resolution for RTX card) 😉
Best Regards and good vibes
SDXLも含めた再検証お疲れ様です。
とりあえず、何買えばいいか判らず迷ったなら、分割払いででもいいからRTX4090買っとけ。は間違いなさそうですね…圧倒的すぎる。
ゲームしないクリエイティブユーザーなら、値下がりし始めた4060Ti 16GBは悪くない選択肢。(VRAM多いから動画編集でエフェクト多用できそう)
ゲームもするなら4070無印以上、か
記事読んだら、CPUなどシステム全体の実消費電力のランニングコストも含めたコスパの良いグラボ探しも面白そうって思ってしまいました。(検証する側にとって時間と労力のかかり具合半端ないですが…)
微妙だという話をよく見かける4060tiの16GB
AIイラスト目的だとやっぱりVRAM効果絶大ですね
とても参考になりました
512×512ですが、Intel ARK770/750に最適化ブーストが入ったそうです
https://www.tomshardware.com/news/stable-diffusion-for-intel-optimizations
RTX4060無印より性能が上になったとか
IntelもAMDも本腰入れて最適化して伸ばしてますね。
まだ一定条件という感じですがRTXに匹敵しはじめているようです。
ただし厳密には消費電力性能もですがまだまだAIではNVIDIAが強くかつ整っているので超えることはもちろん並ぶことも難しい現状ですね。
[…] 参考記事:https://chimolog.co/bto-gpu-stable-diffusion-specs/ […]
[…] 【Stable Diffusion】AIイラストにおすすめなグラボをガチで検証【GPU別の生成速度】 […]
試しにRX570 8GBでStable Diffusion XL 1.0 (1024×1024)をやってみたら、50stepsで19分かかりました。
寝る前に20枚出力したら5時間57分かかっていたようです。
(GPU1000MHz、VRAM1650MHzにダウンクロック、54℃、960rpm)
LowVRAMでPCIEとメインメモリ経由のデータ転送が頻繁に発生する為、GPU使用率が下がってかなり遅くなってしまいます。
VRAM16GB割り当てたRyzen APU(iGPU)の方がMedVRAMで動きそうなのと、転送がメインメモリ内で完結する為、その方が早そうです。
メインメモリは32GB積んでるんですが、コミットサイズが40GB超えることがチラホラあったので、スワップファイルを32~40GBに設定しています。
長期間やる場合は、スワップでSSDの寿命がゴリゴリ削れるのでメモリ増設が必要だと思います。
・GPU
Radeon RX570 8GB (Adrenalin 23.7.1 / AMD-Software-PRO-Edition-23.Q3-Win10-Win11-For-HIP)
・フロントエンド
lshqqytiger Stable Diffusion web UI with DirectML
・起動オプション1
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128
set COMMANDLINE_ARGS= –backend directml –opt-sub-quad-attention –no-half –lowvram –disable-nan-check –sub-quad-q-chunk-size 256 –sub-quad-kv-chunk-size 256 –sub-quad-chunk-threshold 94
・起動オプション2 (VRAM節約の為、Geforce GT635 [0]、RX570 [1]の環境です)
set CUDA_VISIBLE_DEVICES=1
・WEB UI設定
# ONNX Runtime
Enable the memory pattern optimization.: Yes
Enable the memory reuse optimization.: Yes
Reload model before each generation.: Yes
# Optimizetions
Cross attention optimization: sdp – scaled dot product
Negative Guidance minimum sigma: 1
Token merging ratio: 0.1
Pad prompt/negative prompt to be same length: Yes
Persistent cond cache: Yes
Batch cond/uncond: No
DirectML memory stats provider: atiadlxx (AMD only)
・Log
>Steps: 50, Sampler: DPM++ 3M SDE Karras, CFG scale: 8, Seed: 536594022,
>Size: 1024×1024, Model hash: 06e890b5be, Model: hassakuSdxlAlphav_alphaV01,
>Clip skip: 2, Token merging ratio: 0.1, RNG: CPU, NGMS: 1, Eta: 0.67, Refiner:
>sd_xl_refiner_1.0 [7440042bbd], Refiner switch at: 0.5, Pad conds: True, VAE Decoder:
>TAESD, Version: 1.6.0
>Time taken: 18 min. 52.2 sec.
>A: 7.33 GB, R: 8.00 GB, Sys: 8.0/8 GB (100.0%)
https://i.imgur.com/dNTBOKi.png
VAEを使用しない場合は、一部精度を落として、消費を更に減らせます。
以下の設定でVRAM消費6GB、メインメモリ消費30GBになりました。
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:64
set COMMANDLINE_ARGS= –backend directml –lowvram –precision autocast –disable-nan-check
set CUDA_VISIBLE_DEVICES=1
CUDA_VISIBLE_DEVICESはマルチGPU環境の場合に使用します。
iGPU+dGPUの場合は、0を指定するとiGPU、1を指定するとグラボを使用します。
VRAM節約の為、iGPUにOSやその他アプリを割り当てれば、グラボのVRAMは全てStableDiffusionに使用出来ます。
iGPU側で動画を見たりソシャゲをプレイしても、グラボ側のStableDiffusionがVRAM不足で落ちたりしません。
https://i.imgur.com/BZ3LQAL.png
7900XTXのAIでのパフォーマンスが一気に上がったという記事を見かけました
https://wccftech.com/amd-radeon-7900-xtx-offers-higher-generative-ai-performance-per-dollar-than-nvidia-rtx-4080-after-990-speedup/
新しいドライバなどを適用した上での性能差の検証、ご検討いただけるとありがたいです
何気に2070superがめっちゃ頑張っとる
STARFIELD、DLSS 対応しましたねぇ
はやくFSR3にも対応して欲しいところ
このクラス、3060ti,4060,7600じゃ力不足だから
FGの有無結構大事だと思うんだけど
4060はFSR3のFG対応できるかどうかで評価額がガラリと変わってきそう
どこかのブログでGPUそのままからCPUを変えたら24秒→12秒と生成時間が改善されたと見ました
CPUとGPUの組み合わせも検証していただけると嬉しいです
記載されているグラボの中には、VRAMの容量違いがあるようです。
使用したグラボのVRAMの容量は書いて貰えると有難いです。
よろしくお願いします。
あれ?
テスト環境のグラボ中には「RTX 3060 Ti」が無いけど、実際には検証した結果が載ってる?
スペック表に記載し忘れていました。
RTX 3060 Tiも実際に検証済みです。
Will you be adding benchmarks for the 4070 Super, 4070 TI Super and 4080 Super when they are released? It would be great if you are able to add these benchmarks.
Thank you for the very comprehensive benchmarks! For the future updates maybe you could consider an animatediff test as well (it is almost the same as batch generation but slower because it needs to generate every frame by considering surrounding frames)
明日発売の16Gの4070tiSのAI性能は気になりますが、
SDXLのリリースから半年が経過して、
VRAM12G以下は使用量の少ないComfyUIでSDXL生成するのが定石になっています。
主は4090だからUIが馴染みにくいComfyを使っておられるかどうか。
・RTX 4070 Superを追加しました
・RTX 4070 Ti Superは注文済み(発送を待っています)
・RTX 4080 Superも注文済み(発送を待っています)
届き次第、ベンチマーク結果を追記する予定です。
Comfy UIは慣れなかったのですが、2月に登場した「Stable Diffusion Web UI Forge版(GitHub – lllyasviel/stable-diffusion-webui-forge)」でVRAMの利用効率が大幅に改善され、VRAMが少ない環境下で目覚ましい性能アップを確認できています。
たぶん、Comfy UI並みに速いスピードが出ている・・・かも?
大変助かりますが、Radeon の RDNA3 のボードが皆無というのが残念でした…
AI Accelerator ? WMMA ? とやらの有無でどれほど性能が違うのかが気がかりです…
本日(2/9)の更新で、RDNA 3~RDNA 2世代を「ROCm 6.0(Ubuntu 22.04 LTS)」で動作させた場合の性能を追加しました。
ただし、ROCm 6.0でも「AIアクセラレーター」と呼ばれるHWはまったく活用されていない様子です。
radeonに関するコメントが多いですが、現在のradeonでは、ソフトウェア面での互換性の問題だけでなく、ハードウェア自体の行列計算の性能もnvidiaとは大きく差が開いてます、rdna3のwmmaも積と加算の命令数を削減させるくらいの変更のため、
rdna2と比べて2倍程度の差しかありませんが、nvidiaに対しては遥かに大きな差があります。
mi300とかのハードウェアには行列計算に特化した設計になっているようなので、
レイテンシが関係ないディープラーニング向けにはサーバーレンタルで十分ではないでしょうか?
dlssみたいなレイテンシが重要な用途もあることは認めます
很详细,非常感谢
【約6ヶ月ぶりの更新について】
・掲載作例とベンチマーク内容を変更(Asuka Benchmark除く)
・GeForce用のStable DiffusionをStability Matrixを用いて最新ビルドに更新(torch 2.1.0 + cu121)
・lllyasviel氏が開発した「Forge」版のベンチマーク結果を追加
※現在もベンチマーク中で、2日ほどかけてデータに追記します
・Forge版の影響でおすすめグラボが一部変更になりました
・RX 7900 XTXをはじめとするRadeonシリーズを「DirectML」から「ROCm 6.0」に変更 → 以前のデータより格段に性能アップ
・SDXL 1.0(Animagine XL 3.0)のベンチマークを追加
・RTX 4070 Superを追加
【今後の予定】
・Forge版のデータを追加
・RTX 4070 Ti SuperとRTX 4080 Superを追加(注文済み、しかし未だ発送されず)
・不調なRTX 3090の買い替えを検討(優先度:低め)
ざっくりこんな感じです。
とにかく、超高性能なモデル「Animagine XL 3.0」や「Pony Diffusion V6 XL」の登場や、VRAMが少ない環境下でも高いパフォーマンスを出せる「Forge版」の登場で、ようやくSDXL 1.0の世界が始まったな・・・と思います。
hello, you have some news about rtx 4070 ti super please ? for see if have little différence with 4070 super or 4080 please. thanks for your hard world ^^
best regards
お疲れ様です。
参考になりありがたいです。
Forgeのメモリ容量ごとの効果が気になりますので一番重いテストで、
16Gと8Gを比較できる4060tiもテストしていただけないでしょうか。
Forge版 4060 Ti / 16GBの結果を追加しました。VRAM使用量が多いほど、16GB版が速くなります。
素早い対応ありがとうございます。
Forgeが、重いSDXLで8Gでも30%未満に抑えるのは予想外でした。
話にならんからまともにできるに変わったかと。
メモリ少ない下位の方が効果が大きくて上位のコスパが減りましたね。
SD+controlnet で遅くなるのは不思議な感じです。
値段も下がって、上のグラボが中々下がらないから
呪物だった4060ti 16G君が論外ではなく選択肢として成り立っている
50世代が出て安くなれば3060 12Gの立場に収まると思う。
でもForgeが出て12Gあればメモリ量より計算量になって、今は4070系12Gの方が有利ですね。
もうForge版検証していただけるんですか、採用検討していたので助かります!
SDXLは先月末のAnimagine XL 3.0の公開当たりから勢いがすごいですね。
おそらくLoraも増えてくるでしょうし、Loraの自作ができる人なら既に一択の状況です。
自分はadfacterで適当に投げてるだけなのですが、それなりのLoraができて満足はしています。
ただ、やっぱりSDXLモデルの関係上学習に時間がかかりますね・・・4080superか4080検討してましたが欲の上限なしで4090が欲しくなってくる。年末に5090(仮称)が出てくるかもしれないし・・・
逆にサブPCに学習させちゃえばいいんじゃないかなって考えもあります。中古3060 12Gモデルが3万弱(マイニングリスク込みですが)で購入できそうなのでそれでSDXLモデルのLora学習できないかなと現在検討中です。
最近コメント続きでコメントの関係性の表示のために名乗らせていただきます。
3060ならAmazonにまだ玄人志向の在庫があるからそっちもオススメですよ
メーカーが3年保証をつけてくれる、ってのはガツガツ使うんなら安心材料になりますし
ありがとう!
候補にさせていただきます。
大変参考になりました!!
GTX 3060 12Gユーザーなのですが
512×762からの高解像度補助の生成速度の遅さから
連休中でのグラボ買替えを本気で検討していました
GTX 4070 Super と GEX 4070 Super Tiを候補に迷ってたんですが
どちらも価格と電源買い替えと付け替えが必須でうげーってなってたところに
GTX 4060 ti 16G の私が今まさに求めていたも感!
ほんと「天啓」でした!!!
GTXじゃなくRTXな!!!
ぜんぜん違うから気を付けて。
ROCmも含めた検証ありがとうございます!
性能は大きく向上しましたが、やはり、ゲームで同ランクのグラボから1〜2ランク下の性能ですね。
今はNvidiaがエコ環境的にも一択ですが、他も頑張ったり、NPUの性能が上がってグラボは要らなくなったりして競争が激しくなるのを期待しています。
ハローアスカはうちの環境だとバッチサイズ1では4070Tiと4080はあんまり変わらないか、CPUがボトルネックなのかむしろ4070Tiの方が速かったりします。ただ、バッチサイズ2以上の実用域では1.6倍ぐらい4080の方が速いです。
検証ありがとうございます
SDXL Forgeだと4060Tiの8/16GBもあまり変わらないんですね
画像の生成だけなら8GB版を買うのもありなんでしょうか?
SDもSDXLも最適化が進んでて、今は遊ぶだけ(生成するだけ)ならVRAM8GBで十分ですよ
ありがとうございます
8GBでも十分ならグラボの選択肢も随分広がるし助かります
Forge版の検証ありがとうございます。
UM780 XTX に OCulink で繋ぐ、コスパ良いグラボ探していたので参考になりました。
リンクから3060 12GB購入しました!
流石にCore i9速いですね。うちの4080はRyzen5じゃ18sぐらいしか出ないですorz
Venvの違いか?と思って試しにStabkeMatrixの方を入れたら20sオーバーと余計に遅くなってしまいました。
やっぱりGPUだけ良いのに換えても駄目みたいですねー。
ハローアスカは半分CPUベンチかも
CPUによってGPUの消費電力も生成速度も1.5倍とか変わるので、GPUに合わせてCPUも上げないと引き出せない感じ(ただしバッチサイズ1に限る)
RTX 4070 Ti SuperがRTX 4070 Ti より16GBに増量されコアも4080と同じだからその分生成速度は速くなるのかしら?もしそうなら15万までで手が出しやすくてそこそこ良いかも(誰でも手が出しやすいとは言っていない)
生成速度は4080よりちょっと劣る程度
学習ではVRAM16GBが大活躍する
っていう位置づけそのままでいいとおもう
外付けで使用したときの性能差も今後調べていただけると参考になります。
NSFW用途ならAnimagineXLよりPony diffusionXLの方が強い…と思ったけどプロンプトが独特だから敢えて避けてるんですかね?
ubuntuに抵抗ない人でゲームが大事だaiイラストもやりたいけどそこそこ時間かかってもええよって感じなら
7900xtとか7900xtxは結構選択肢に上がってきたと言えるのだろうか7900xtは無いけど
おそらく7900xtxよりの処理性能で20Gだし最後のベンチマークもいけそうだし費用対効果はハイエンドの中では1番
AFMFで4kゲームもいけるしなぁ
7900XTXは今は4070と渡り合えるくらいになっているけど、スペック的に2割程度落ちそうな7900XTはよりVRAM効率悪そうで2割以上の可能性ある。
コスパとワッパでもXTXより悪化しそうでもうちょっと出してXTXが無難でかつなるべく速い方がストレス減ると思う。
でも結局ゲーム用、AI用の2台用意するのが一番ストレスないんだよな
ゲームはしないからRTX2060superで遊んで妥協できてるけど
セッティングを詰める時だけはネットカフェPCでやってるわ
Forgeなら、8GBのビデオボードでもSDXLが完走するのが地味にすごい。
生成だけOKで学習は無理そうなので、気が向いたら学習用を準備しますかね・・・
12GB機を推してる割にほぼ全てのベンチマークでTI8GB機に負けてて、唯一勝ってる高解像度テストでもForge版で逆転されてるので、中古価格がほぼ同じ12GBとTI8GBはTI8GB買う方がいいかなと思った。もっと解像度上げたら結局12GBでも足りないし微妙
今ならRTX3060よりもRTX4060を購入する方がいいのでしょうか?
値段が殆ど変わりないので
4080superと4070ti superの追加お疲れ様です。
4080superは想定通り無印4080とほとんど変わらないですね。ただリネームして値上げしただけ
4070ti superは….メモリ容量が増えてるんだからAI用途だけでも4080相当使えてくれっていう最後の希望だったんですがその希望もむなしくお値段4080相当で性能は劣化品という悲しい結末に…
苦情はNVIDIAではなくAMDにどうぞって感じ
80番90番を求めていないなら、4070tisuperがコスパタイパ的に良いのかなと漠然と思っていましたが、AIイラストの為だけにそこまで背伸びする必要性は薄いみたいですね。VRもやってみたいとかになるとまた変わってくるのでしょうが…。AIもVRも最新ゲームをWQHD以上でやりたい‼配信も‼この辺りの層以上向けみたいですね。コメント欄も含め大変参考になりました。
4070tisuperが思ったよりコスパがいい 4070superに3~4万円足せばvramが+4GB付いてくるし 逆に4080superの方は4070tisuperに3~4万足してこの程度の性能は大分コスパが酷い気がする 最近は画像生成
ai関連ツールの開発速度が早くて凄まじい進化を遂げてる途中だから未来を見越してvram16GBは欲しいところ vram12GBは今はいいかもしれんけど将来的にはパワー不足だと思う 最安値かつ生成aiに限ればの話だけど
4070Ti superって4070系の延長線上にあって、4080はそのさらに上なんですね
4080はL2キャッシュが多いのが効いてるのかな、どうかな。
単純なCudaコア数とVRAMの影響ではないんですね。参考になります。
一番重いベンチで4080ti12秒4080 15秒forgeで縮んでいるのに
4070tiSuperは7秒も縮まらないのが離された原因。
メモリ量がボトルネックではなかった、計算力がボトルネックだったのでしょう。
4060ti16Gの縮小率が4070tiSより大きいのはメモリ帯域がボトルネックだったのかな。
ちなみに4060Ti 16GBは私の手持ちの機材(B660,12600k)で同じベンチやりましたが、ここの結果よりも速度が上がってたりします。
使ったボードの違いもあるだろうし、checkpointを変えて最初と2回目でも結果が違います。
CUDAコア数に対し、4060Ti 16GBと4080の点を直線で結んだグラフ上には、4070系がいなくて、直線から少し下がったところに4つきれいに直線で並びます。4070Ti superもです。VRAMが16GBならTi superも線上に乗るかと思ったのですが、違いました。奥が深いですね。
詳細なデータありがとうございます。
3060ti→4060ti16Gを考えていたのですがこちらを見て期待外れになりそうでしたので4070まで背伸びしてみました。
やっぱりAIするならラデよりゲフォなんですかね?
RX7600XT 16GBだとどれくらいの速さなのか気になる
>神里綾華(SDXL LoRAベンチマーク)で、Forge版RTX 4070は
>RX 7900 XTX(約15~16万円)に迫ります。
とあるけど7900XTXがグラフから消えてません?
好みでないのは知ってるのでかまいませんが引き合いに出す時くらい載せたほうがいいと思う。
最初のグラフには前からしっかり7900XTXもあるけど・・・
下のどれがお勧めかでの説明でのグラフはお勧め中心で、7900XTX以外も含めて簡略化されているだけで歪んだ難癖になってますよ。
VRAM 24GBが望ましい8GBではお話にならなかった設定で(RADEONではメモリ不足で根本的にだめ?)
4090 Forge 33.6
4090 34.0
4080 Forge 48.3
4070TiSuper Forge 61.5
4080 63.8
4070TiSuper 66.5
4070 Super Forge 71.1
3090 Forge 73.7
3090 74.0
7900XTX 75.5
4070 Forge 79.6
3070 Forge 136.4
4070 310.4
3070 796.2
ということで、4070のコストパフォーマンスがForgeによってVRAM 24GBが望ましい設定でも良くなったということで、価値がより上がったということですね。
学習ではなく生成のみなら今後よりVRAMが少なくても進化しよくなっていく可能性がありますね。
場所的にグラフに対するコメントなんだから直近のグラフにいないのは変だろ
検証お疲れ様です。
更新の際には「4070 Ti Superを追加しました〜」といった具合に、記事冒頭にでも添えていただけるとわかりやすいかと思いますが、いかがでしょうか
記事の最後についてるよ。
正直スクロールで飛ばす部分だよね
4070TiSuperがTiとキャッシュ量が同じなためかあまり伸びないケースがあるようで、4080の代わりにはなりそうにないですね。
4090は4080より実売価格では1.8倍も違ったりもありで、総合的にみると4080か4080 Superのお安いのが色々と良さそうですね。
更新お疲れ様です。
4080superを自分も買いました。3060からの買い替えでしたが、こちらの記事のような結果にはならず、むしろ遅くなりました。
ドライバ更新やcuDNN更新など試しましたが一向に速度が改善されません。
VRAMの恩恵は受けているようで、16G分でできることは増えました。
換装時、4080super含む、40シリーズで他にしなければいけないことって何かあるんでしょうか?
筆者さん以外にも知っている方がいらっしゃいましたら是非ご助言お願いいたします。
Pytorchのバージョンが2.0?以降でないと40系に最適化されない
少し検証状況がズレ始めてるかな
細部まで描かれた絵を出すにはhiresや拡張機能必須になってるから、別でVRAMに着目したベンチとった方が良いと思うよ。
結局ローカル環境構築して迄SD使う人は突き詰めてく人が多いからVRAMの壁にぶち当たる
Forgeがあんまりアプデしてくれないのでこのペースだと夏前には本家1111の環境に置いて行かれるかも。
速度面はLightningとか技術面である程度カバーできる部分があるからよりハードの部分でVRAM偏重化しそうだね。
本家が処理(メモリ)の効率化を放棄するとでも宣言したのか?
実際はともかく一時の時間だけの判断でどうこうは気が早すぎかと。
そして有意義に使えるとしても、まだまだ過渡期で進化の途中。
forgeはアップデートが少ないことで
どの部分が劣ってるのか教えて頂けませんか?
>結局ローカル環境構築して迄SD使う人は突き詰めてく人が多いから
何か根拠は有るのか?
俺の周辺だとグラボは有るからとゲームの延長でやったりして
生成だけのカジュアル用途が多いんだが
しれっと4090と4080のデータを差しかえてませんか?
そんなら4070と4060Ti辺りも再測定して差しかえていただけるといいかもです。
より重要な価格の方も一般的なものに差しかえていただけたらと。
2024年4月で4090が27万円で4080が20万円と記事にはありますが・・・
複数モデル複数店でのWEB価格を掲載する価格コム情報では、4090が29万円 4080が17万円ですね。それぞれ1種だけの最低価格
さらに4080はディスコンで価格が上がっているためでもありですが、4080 Superがより安く16万円台のモデルが4種もあるようです。
それをやったらコスパが変わるからと
寸評の差し替えも要求するんだろ?
2024年4月の価格として表記するならより実勢にあったものが普通に良いでしょう。
コスパがより正確に違ってくるのも当然で割と無視できないのでは?最も無視できないポイントでもあるとも普通に思えますが。
実勢価格ってのはヨドバシ・アマゾン・ソフマップ等の
有名通販で普通に買える価格だな
あなたが保証無しの並行輸入品を掴んだりするの勝手だが
それはただの自己責任
価格コムの囮価格が実勢価格だと思ってるならそうかもな
メモリ容量の記載のないGPUのメモリ容量を教えてもらえませんか?
記載が無い物は一種類しかないから
検索AIにでも聞けば判る
一応言っておくとNVIDIAなりAMDが決めるもので
MSIや玄人志向、ましてユーザーが増減できる物ではない
末尾でおすすめしている4090ですが、筆者さんのように電源と冷却フローとマザボ含むcpu周りが揃った環境ならば、価格に見合った性能として間違いないと思います。
ただ、世の中の多くの人は4090を動かせるパソコンを持っていないのです。特に450Wの消費電力とそこから生み出される莫大な排熱はこれからの季節の悩みの種です。
なので、おすすめするだけでなくその部分も少し触れた方が親切じゃないかと思います。
まあ電力制限かけても4090の方が速い場合も多いので突き詰めたら4090で間違いないですが。
うちの5年くらい前の古いGPU(2070 Super)でもちょっと動かすくらいならできるのね
試しに遊んでみようかしら
9700K(MAX140W)+2070 Super(MAX215W)でも部屋の気温上がってこの時期は悩みのタネなのに
GPUだけで450Wとか正気の沙汰じゃねぇ……
[…] てメモリが多いからAIに向いてると聞くっす それの上を目指すと一気に価格が跳ね上がる印象っす https://chimolog.co/bto-gpu-stable-diffusion-specs/上記は管理外のサイトへのアクセスとなります。 […]
2080tiを使ってて、とてもここに出てるようなスピード出ないんですが
CPUが貧弱なことと関係あるとおもいますか?
Ryzen7 5000なんですが。
それともメモリやマザボも関係あるんでしょうか。
そもそもforgeにしても1111と速度が全く変わらない。少しは効きそうなものですが。
可能性が高いものを挙げると
・サンプラーは同じか、例えばeulerとheunでは速度が2倍違う。
・生成サイズは同じか。
・グラボのドライバは最新のものか。
・xformersなどのコマンドライン引数は適切に設定しているか、なお、channelslastは推奨されていることが多いが、逆効果になる場合もある。
・ハードの問題はないか、特に電源ユニットは消耗品なので経年劣化の影響を受ける。OCソフトを使っているなら低電圧化で多少は改善するが、根本的な解決には交換するしかない。
開設11年目おめでとうございます
生成速度検証とても参考になりました
dGPUをマザボ出力検証も初めて知りました
こちらのブログにはいつもお世話になってます
1024×1536:神里綾華(Hires.Fixアップスケーリング)
でRTX3080でSDの設定は同じでやってみたのですが
Memory cleanup has taken 0.32 seconds████████████████████████████████████████████████| 300/300 [02:11<00:00, 1.16it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 300/300 [02:18<00:00, 2.17it/s]
Total progress: 100%|████████████████████████████████████████████████████████████████| 300/300 [02:18<00:00, 1.16it/s]
これぐらいの数値に鳴ってしまいちもろぐ様のような数字にはなりません
CPUは13世代i5ですがほかなにか設定が悪かったりしますかね?
forge完全に実験用にするとよ
大抵の機能が使えなくなるからA1111へ戻るの推奨だと
上で叩いてた連中は目が覚めたか
何も答えられずぐうの音も出なかったアホの人か?
ぐうの音所か当時はこれからそうするよって関係者から聞いてたんだよ
勝手にリークするのも申し訳ないから遠回しに教えたのに叩かれる始末
ここのコメ欄何も知らないのにすぐ攻撃してくる人が多過ぎる
もう教えん
何も教えてないのに「もう教えん」ってのは君の周りだとウケるギャグ?
それはA1111がForge並のVRAM消費と速度が達成出来たからでしょ
なら最初の話に戻るだけじゃないの、何と戦ってるのかしらないけど
最高のまとめサンクス(^ω^)
forgeは方針転換のせいでどうも今後は消費者が画像生成して遊ぶソフトではなくなってくる感じなので
今後は本家1111の方基準に考えないといけなくなって来た感じですね
本家の方も以前よりかなり早くなってますが
結局Fluxにも早々に対応して本家より楽しく遊べてるんだけどね
[…] GPUによる生成速度差は、ちもろぐさんの描写時間の比較が参考になります。 […]
現状、(ほぼ)ドスパラで揃えた最安KAKAKUが
4060Ti16:69K
4070:84K
4070Super:99K
4070Ti:(在庫が安定してないが120K程度)
4070TiSuper:132K
4080Super:150K
4090:300K
ぐらいで価格低下で4080Superが地位向上した感じ。
裏返すと、4090が値崩れしなかった=最初に臆せず4090を買って使い倒した人が現世代の勝利者、なのでしょう。
レンダリング性能が近接している7800XTと6800XTでAI性能の差が生じているのはWMMAの効果ってことでいいんですかね
とんでもなく高価なので無理でしょうがCDNA3のMFMAの挙動が知りたいです
さすがに情報が古くなってきたわね
今はA1111でもかなり効率的にVRAM使えてるし(forgeの開発意図通りだけど)
でもまあグラボ性能の目安としてはまだまだ有用
GeForce RTX 50シリーズも正式発表されましたので、ミドルレンジのRTX5060辺りまで出揃ったら最新の生成AI環境で、どういった結果になるのかベンチマークが欲しいですね。
特にVRAM12GB版があると噂されるRTX5060と、コスパが良いと噂されるRTX5060Tiでの結果が気になります。
5090購入のXのコメントでAI生成に関心が残ってるみたいで安心しました。
①更新期間もあいたし、今のページを残して新ページで刷新して欲しい。
②というのも、SD1.5はもうベンチしなくて良い気がしますし。
今なら個人的にSDXLとWAN VIDEOが熱いですね。
ComfyUIで「1024×1648:神里綾華(SDXL + LoRA + ControlNet)」をやってみました。GPUはARC B580です。47.60秒でした。あれですかね、最近だとComfyUIの方が速いんですかね。Forgeは使ったことないのでわからないですが。
Arc B580 pytorch(v2.5.10xpu)
ハローアスカ:20.6s
神里綾華1024×1024:28.8s
RTX4070並みの速度でこれは中々。
書き忘れました。
上はstable diffusion forgeの時の速度でA1111ではこれより遅いです(ReForgeでもほぼ同等)。
forgeで1月くらい使っていますが、拡張機能が使えない等の不便は今の所ありません。
reforgeでも同等というのは、Arc B580でのreforgeとforgeの生成速度がほぼ同等という意味です。
度々すいません・・・。
RX7900xtxのLORA学習のベンチが気になります
Vram効果で上位に入るのか…
Will you be testing 5xxx series? I am curious about 5060 ti 16gb and how faster it is from 4060 ti 16gb
Hocam detaylı bir anlatım olmuş eline sağlık
[…] 速度の参考:もちろぐ […]
RTX 5090での画像生成比較も追記してほしいです
データとしてはすごいありがたくて目安として使うにはとても良いのですが、
一番古いデータは2023/3/8公開時点に基づく速度データで
完全に同じグラボでもSD A1111、SD Forgeがさらに最適化されて2023年よりも2025年の方が早く生成されたりするので過去のデータから新グラボ(RTX5000シリーズ)を追記という形はあまり正確ではないんですよね…
もしも記事を作り直す場合はSD1.5は集計データから外す(2025年現在SDXLがメインで旧環境を使うメリットがほぼない)・ComfyUIで取り直すとかやっていただけるとありがたいです。
ご検討よろしくお願いいたします。
wan videoはメインメモリを使うので、PCIeのボトルネックの話題が出てくる。
最高はPCIe5の16レーンで、実用上の最低はssdとレーンを分割してPCIe4の8レーンと帯域に4倍の差がある。
誰か比較してくれないかなぁ・・・チラッチラッ
おー、更新されてますね。
意外だったのは、3050と1070Tiの性能差。
去年の今頃、自分で3050_8GBと1070無印を比較してみたんですが、
当時のForgeだと同等か1070無印の方が生成速度上まであったんですよね。「所詮は50番台か!」と思ってましたが、今回のベンチだと大差ついてますね。ComfyUIとの違いか?
ComfyUIはGTX 10xxシリーズをFP32で動かすらしいです。
RTX 30シリーズはFP16対応なので、単純にスループットが2倍です。Forge版はこのあたりをうまく動かす特殊なノウハウがあった・・・可能性?
RTX 50xxシリーズを追加するだけでは不足だったので、ベンチマーク内容を全体的に刷新し、最新環境であらためてやり直しました。
【使用ライブラリ】
・GeForce:前回と同様にCUDA続投(cu128に更新)
・Radeon:コンパイルが長ったらしいZLUDAをやめて、AMD推奨のROCm版PyTorchに切り替え
・Intel ARC:oneAPIをやめて、Intel推奨のXPU(Intel版PyTorch?)に切り替え
以上の変更で、RadeonとARCの安定性と速度が改善しました。しかし、GeForce環境には「Sage+Triton」加速ライブラリが登場し、さらなる進化を遂げています。
Radeon環境も一応Sage+Tritonを入れてはいますが・・・、まったく勝てる気配を感じなかったです。
【生成ソフト】
A1111版とForge版を全面的に取りやめ、最新技術てんこ盛りの「ComfyUI」に切り替えました。ComfyUIのベンチ結果は、ReForgeとも一定の互換性はあります。
Forge系はComfyUIを背後で動かす、いわばComfyUI Web UI的な構造をしているのでけっこう似ています。
と言っても、Forgeは更新停止中、ReForgeも先ほどアーカイブ化されるなど。あまり未来のないソフトです。QwenをベースにしたFTモデルに備えて、ComfyUIの乗り換えるべきでしょうね。
【ベンチマーク】
1.
伝統的なHello Asuka Benchmarkのみ残し、他はすべてSDXL 1.0とQwen Imageモデルに変更。
2.
連続キュー(Batch Count)より並列スレッド(Batch Size)を重視する内容に変更。せっかくVRAM容量があるんだからガシガシ使ってあげて、1枚あたり速度を稼ぐ方針です。
3.
Hires.Fixベンチマークは「VAE分割技術(Tiled VAE Encode & Decode)」を導入し、生成品質を維持しつつ、少ないVRAMでパスさせる方針に変更。この変更で相対的にRadeonを優位性が削がれ、GeForceとIntel ARCがさらに躍進します。
Tiled VAEはあれば使う人のほうがずっと多いですし、Easyシリーズで知られるZuntan氏もワークフローに取り入れられてるポピュラーな技術です。
なお、Tiled VAEは逆に分割数を減らすことも可能です。4090や5090など、莫大なVRAM容量があれば、あえてタイル数を減らして、速度をさらに稼げます。(この手はRadeonには通用しなかったです・・・なぜならVRAMの食い方がそもそも異常に多いから)
4.
Qwen Imageはどちらかといえば「Edit」モデルが本体だと感じていますが、とりあえず今回は無難にそのままネイティブ生成を評価しました。
そもそもネイティブ生成が通らないようでは、Edit版も当然無理です。
とりあえず現状こんな感じです。
とんでもないNSFW性能(= 人体の破綻なくcrowedやmultiple boysではないプレイアブルな複数人を同時に生成可能とか)を備えた、Qwen版PonyやNAI-XLが出てきたら、またあらためてベンチマークするかもしれません。
やっぱりえっちは重要だもんね!
そろそろComfyUIに移行すべきか…
ComfyUIいいですよ。
たとえば、Qwen Image Editだと
1. 推しキャラの生成イラスト
2. 自分の部屋を撮影した写真
この2つをかなり違和感なく合体して生成できます。
これを今度はWan2.2(動画生成)に突っ込んで、つづきを生成できます。日常の中に推しが侵食して、なかなか凄いです。
大変な労力の要る検証あざす!
検証お疲れ様です。大変参考になります。
表を見るとB580が異様に高性能ですね。5060Tiが霞むほどのレベルです。
そして5070も値段以上の性能を見せてくれました。
やはり5070もお買い得でしょうか。入門用の低価格帯ならB580が最高ですね。
最近、RadeonでもPROのR9700というAI用のGPUが話題になっているようです。
5090より低コストでありながら、AIを使う用途に関しては5090よりも優れた性能らしいのでこの表に載せられたら面白そうだと思いました。
もしも入手できそうなら、検討して欲しいです。
画像生成で、PRO R9700がRTX 5090を上回る可能性はちょっと厳しい予感。
ComfyUIで計算すると
・RTX 5090:104.8 TFLOPS(1:1)
・R9700:48.66 TFLOPS(1:1)
単純な計算性能だけで、2倍以上の差があります。
Qwen Imageなど、一部の最新モデルで対応が進みつつある「FP4」で計算すると
・RTX 5090:3352 TFLOPS(FP4)
・R9700:1531 TFLOPS(INT4)
最大の理論値でも、やはり2倍以上の性能差です。
共有メモリ漏れによるペナルティをリカバーする能力も、GeForceが全体的に優秀で、同じ32 GBだとメリットを見いだせないです。
たぶんR9700はLLM向けに用意された特殊なモデルだと思います。一般人が画像生成を趣味で使うには、だいぶクセが強い印象。
いつも楽しく拝見しております。
RTX5070のネガティブキャンペーンはなんなんですかね…?
海外の人の動画だと割と評価されてる気はするのですが、国内動画はネガキャンばかりで疑問でした
価格が下がった現在でも、MFGを使わないなら5070よりCUDAが多くてワッパの良い4070Sのほうがオススメ!!とか発信してしまうブロガーもいるんですよ
初期にむやみに叩いてしまった人は手のひらを返したくないんでしょうね
※ここの計測だと5070の方がワッパ良いです
海外でも初期はVRAM容量で大不評ですよ
値段が落ちてから光るタイプというか、結局このTierはコスパなので値段大事
YouTubeのアルゴリズム的に、その方が再生数が回ると思います。
動画投稿する人も(たぶん)生活とか提供元との兼ね合いとか色々あるので、やっぱり再生数的に今は革ジャンを下げた方が良いのではないかと。
実際、RTX50シリーズの初動対応(ex. 高すぎる国内価格、ひどい品薄)が悪かったのは事実ですし、それで恨みを買った側面も否定できないですね。
ただRTX 5060 Ti以下はともかく、RTX 5070以上は無難にいいラインまで戻したと、個人的に思ってます。
検証お疲れ様です。
ほぼどころか完全にページが一新されていますね…すごい
ComfyUIで使用するテンプレートが見当たらないのですがどこにあるでしょうか?
各検証設定のタブの最下層に
ComfyUI用
ワークフローをダウンロード
の項目はあるのですが。ワークフローのDLのリンクが入ってない状態になってますかね?
すみません。URL入れるのを忘れてました。
先ほど「.zip」形式に圧縮したワークフローまとめをアップしました。zipを展開して、中に入ってる「.json」をComfyUIにドラッグ & ドロップでテンプレートを開けます。必要な各モデルのURL一覧もワークフローの中に入れてあります。
いつも楽しく拝見しております。
愛用のRTX-3060(12G)がコスパが良くてビックリですが、絶対的な速度が低いのも低いのもまた事実かと思います。
そこで相談ですがグラボの2枚挿しでの性能はどうなると思われますか?
クラボの2枚挿しがマザボと電源は対応可能な場合、約4万で性能2倍になったら個人的には非常に嬉しいのですが、定量的に評価した記事が見当たらず迷ってます。
約8万でVRAM24Gは魅力的に思えるのですが、罠でしょうか?
ニッチなニーズですが 考察 or 検証いただけると非常に嬉しいです。
カード間通信は結局PCI-Eとなりますので遅いです(VRAMバスと比べたら)
なので2倍はどの道難しいです
ComfyUIのマルチGPUでできること
1. ComfyUIを2つ起動して、別々のタスクをそれぞれ個別に処理
2. Multi-GPUノードを使用して、生成モデルとテキストエンコーダーの役割分担をする
くらいですね。
要するに、一般にイメージされるマルチGPU本来の使い方はできません。
ただ単に「役割分担ができる程度」で、2枚合体させて1つのGPUとして振る舞う・・・といった使い方に画像生成が対応してないです。LLM(言語)なら対応してるのに、画像はなかなか対応しないですね。
ちもろぐ読者様 やかもち様
早速の回答ありがとうございます。
ご指摘の通りグラボ2枚挿しでLLMを高速化してる方を見かけるので、画像生成でも同じかと期待したのですが対応してないのですね。 CUDAが自動でグラボをまとめてくれるかと期待したのですが甘かったです。 高速化はやはり良いグラボを買うしかないということでお財布と相談します。
待ってましたっ!
しかしコメント欄長すぎ問題
ここでコメントするとコメント欄が長くなってしまいますが言わせてください
検証お疲れ様です!
4070無印ユーザーにはやっぱ「5070tis24Gまで待て!」かねえ。
R9700が出る頃にはROCmが使い物になるかと期待してたけどまだまだか…
成程5070Tiじゃなくて5070なのか…と思ったが、70Tiや80は5090の代替えや代理案の方な訳ですね。ゲームも高画質・AIも色々やりたいってなったらどんどん上を見始めるし背伸び出来る限界はここまでって人にはとても参考になる。5070Tiも値段落ち着いてきたしBTOも値段改訂し始めたし年末セール辺りが買い替え時かもね(そしてsuperが発表されて時期が悪いおじさんになるっと)。
ネットではラデオンも問題なくAI使えるとか聞いてたのでもうちょっとまともな性能が出る思ってたけどまるで駄目ですね…
RTXも日々進化してるし追いつくのは一生無理そう
SD1.5で512px、SDXLで832px程度を1枚ずつ出すだけなら、Radeonでもそれなりにできるくらい。
RadeonがWindows環境でちゃんと使えるようになるには、ROCm7.1~7.2以降になりそうな予感。
一応、今回のベンチでは
・ROCm 6.4.2(AMD公式build)
・ROCm 6.5.0rc(Scott氏build)
・ROCm 7.0
で検証して、一番成績がよかった6.4.2を採用してます。
RTX50シリーズさらに速度アップ
https://blog.comfy.org/p/comfyui-now-supports-qwen-image-controlnet
一番下の方に書いてあります
大変な労力を要する検証お疲れ様です
この流れでArc B580の(ゲーミング含めての)レビューを出していただけるとありがたい…
やっぱメモリの容量がもの言うんですな、当たり前って言えば当たり前だけど
5080、5070Ti、5070は出てくるであろうSuper版だと随分と変わってくるんでしょうねぇ、ただ値段の問題があるけど・・・5080Superが4090に肉薄するかどうかだが・・・5090は高くて買えねぇ(5080Superも高そうだけど)
RTX 5080 SUPER(仮称)ですが、CUDAコア数が増えないと一部の用途でしか性能向上が見られない、微妙なリフレッシュモデルになりそうな予感。
・GB203:10752コア
・RTX 5080:10752コア
しかも、5080に使われてるGB203ダイはすでにフルスペック仕様です。物理的にコアを増やす余地が残されていないので、これ以上のコアはGB202(PRO 6000 Blackwell)が必要なわけですが、原価が高いGB202をゲーマー向けに流用する可能性はあまり高くないですね。
コアが欠けたGB202は、基本的にPRO 5000 workstationや5090に回されて、5080まで降りてこなさそう。
検証お疲れ様です。
最近のGeForceならVRAMより大きいサイズのモデル使ったりしても理不尽な速度にはならないんですね。RadeonやArcもそうなれば話は変わってくるかもしれません。
ベンチマークとは無関係ですが、神里綾華がお好きなんです?
原神で25万円くらい突っ込んで、キャラ武器完凸させる程度には気に入ってます。
で、この「神里綾華」が原神全体では割とマイナー寄りで、人間からのFAや同人供給がかなり稀です。
非常に困ったことになった・・・というところに、AnimagineやPony V6が登場して一気に世界が変わりましたね。生成AIにハマる最大級の動機になったキャラクターだから、ベンチマークでも採用してます。
ComfyUIの起動時オプション「–supports-fp8-compute」は試されましたか?
Radeonの一部GPUにおいて、fp8演算が可能であるのにもかかわらず使用されていないことがあるようです
個人的には「GTX系とか一部Radeonの検証結果要らなくない?」と感じました
最初はバーの長さを見て「あれ?意外とRadeon善戦してるじゃん!」と思って読んでましたが、後々数値を見返すと数十秒~分単位で遅れててびっくらこいたので、あまりに生成に時間がかかっているグラボはグラフから外したほうがパット見でもわかりやすいかもしれません
例えば一つ上の結果と比べて1分以上遅れの結果が出た場合は掲載しない(もしくは別枠で記載する)とかどうでしょう?
FLUX.1はされなかったんです?
Fluxシリーズは、リアル系ならQwen Image超の品質だと主観的に思える、素晴らしい生成モデルですね。
ただ・・・個人的に好みに合わないので使ってないんです。
EVO-X2のテスト結果も載せてよ
EVO-X2まだ開封すらしてない。
たぶん、ミニPCとしては最高のスコアを出せる予定です。
Thanks from France, most useful article about AI and GPU I’ve ever read
フランスからありがとう!AIとGPUについて、今まで読んだ中で一番役に立った記事だよ
色々ご確認・ご説明ありがとうございます。
Qwen ImageのQ3_K_M軽量化版は9.68GBのサイズですが、どうやって劣化なさそうで8GBのグラボで実行しますか。
あ、普通にできるようですね。勉強になりました。
Helta 4K Hires.Fix Benchmark での
RTX 2080Ti 11GBの生成時間は115~118秒でした
5000番代は問題なく使えるようになったの?
まだ対応が甘いから4000番代で頑張ってるけど全部が問題なく対応しているわけじゃない?
1111がオワコンなだけ?
5090以外なら別に4000番代で静止画なら問題ないかな
返信どもでした。
今4000番代で頑張れているならばそれで良いと思うけれど、これから始める人が積極的に4000選ぶ理由はほぼ無くなっているの思いますよ。
ただAIじゃないけど5090でSteamのニーアオートマタが赤く滲むようになりました。(設定次第かもしれませんがWebで情報見つからず)eGPUの3060繋ぐと問題無しなので、ドライバの熟成はもうちょっとかな?
なんかネットでは5000番代は対応が甘いみたいなことずっと言われてるけど
5000番代が発売された2025年2月時点でComfyUIやForge系は対応されて新規インストールする場合は何ら問題なく画像生成は出来ましたよ。
A1111はもう1年以上更新されていなく、5000番代使いたい場合はDevでセットアップする必要ありオワコンだと思いますよ。
検証ありがとうございます。よく参考にさせていただいてます。
自分でも試してみたく、RX 9060XT 16GBで「02_SDXL_Benchmark.json」を
読み込み実行したところ1枚あたり22.2秒、1.49it/sほど出ました。
検証結果の倍程度の速度が出ていて戸惑っています。とは言え、生成される
方々からすると候補にもならない性能とコスパだと思いますが。
何か不足したり間違った設定やモデルがあったのでしょう。
残念ながらGeForceは1000、2000番代しか持っていないのでROCmの完成度が
あがるのを気長に待つことにします。
please use this pytorch wheels, you need the latest rocm for 9000 series https://github.com/scottt/rocm-TheRock/releases/tag/v6.5.0rc-pytorch-gfx110x y
Rocm版PyTorchで動かすよりまだZLUDAで動かす方が主流だし速いからじゃないですかね
Radeon環境でWindows環境でRocm版PyTorchって聞かないです
ひとつ気になったのですが、もし記事の趣旨とズレていたらすみません
ベンチのほぼ全てのプロンプトに入っている\(chainsaw man\)とは一体どういう意図で入っているのでしょうか
今回のベンチの設定をお借りしてComfyUI触り始めてみた身としては夜しか眠れません!
info@yamato-ai.jp
ワットパフォーマンスの検討がされていませんが、ゲーム時と同じような傾向なのでしょうか?また別の傾向なのでしょうか?
追記 生成の場合は遅くても電力が低ければ、時間当たりは悪評価ですが、1枚当たり高評価ということになるので
IntelのB580(Xe2世代)が意外なほど健闘していて驚いています。
これはXe3やXe4にもちょっと期待できそうですね。
Xe3やXe4世代でVRAM24GBや32GBの製品がNvidiaよりも安く手に入るようなら、生成AIやVR Chatユーザーに刺さるかもしれないですね。
……というよりも、エンタープライズ向けのAI用途でNvidiaに対抗できてしまうかもしれないというほうが重要か。
contact@gcconsulting.site
「ComfyUI」と「ReForge」が主流
って書いてあるけどほんとなの?
ARC B580で生成してるんだけど、
「Forge」は出力の傾向がバラバラで使い勝手良くなくて
「ComfyUI」はプロンプト書き換えて数を出力したい場合に面倒で
結局A1111に戻ったんだけど
RTXだと全然違うとかあるのかな?
Arc B580使っていますが、ComfyUIの起動OPに–bf16-unetを入れた場合、私の環境では入れない場合に比べて、1枚当たりの速度が15-20%程度遅くなります。(832×1216でstep28 –bf16-unet有では平均11.5s ナシでは平均9.9s ただしpcieはチップセット側の4.0×4に接続してるため少し遅いです。)。
–bf16-unetを入れなくても安定する場合は入れないほうが良いかもですね。
A1111で 728×1024のhi-res:1.5で1152×1536でやってます。現状5枚が限界くらいですかね、それ以上だとメモリでエラー。一枚15sくらいです。出てくる絵面の傾向がA1111のが好みで。うーんComfyUIいぢくり度が足りないのかなあ
いつも読み応えのある記事を提供してくれてありがとうございます。
9070XTで生成AIを始めたのですが、VAE周りがどうしても遅く追加で5070を注文しました。
分割VAEを使っても3060よりVAEが遅かったです。
非常に分かりやすい比較記事のおかげでスムーズに選ぶことができました。
今後の記事も楽しみです。
Please use this https://github.com/scottt/rocm-TheRock/releases/tag/v6.5.0rc-pytorch-gfx110x rocm 6.5 fixed most of my vae issues.
Hi I was able to complete your 4kHiresFix benchmark which you said you werent able to on a radeon with a 7900xt 20gb in 73 seconds, I think you forgot to change to vae decode for the starting image, but the other benchmarks were mostly accurate except for the Herta hires which I got 37.5 vs the 50 you mention on the xtx. I’m running Rocm6.5 on Windows 11 from https://github.com/scottt/rocm-TheRock/releases/tag/v6.5.0rc-pytorch-gfx110x
いつも拝見しております。
Control Netを使用するとIntel Arc B580の生成速度が大幅に落ちるんですね。生成AIに興味があって、生成AI用に安くPCを組みたいと思ってたのですがイマイチそうです。
バッチサイズを小さくすれば速度を落とさずに使えるのでしょうか。
AIイラスト面白そうだなあ
5070tiもやっと手が出る範囲まで値下りしたし、PC新調ついでに初めてみようかな。
ついでにゲームができるようCPUは7800x3dで組むつもりですが、AI生成はIntelの方がよかったりしますか?
7900XTXをROCm 7.0.0、Linuxの環境で試してみたところ「3840×2160:ヘルタ4K(Hires.Fix)ベンチマーク」が安定して完走するようになりました。
4k出力に耐えられないというのは一応汚名返上ってことになろうかと思います。
ただキャッシュの生成のせいか初回は15分。
2回目以降は100秒をギリギリ切るか切らないかなのでここ基準ですと実用にならない判定になるとは思います。
やらかした……5070のおすすめBTOパソコンを買ったら古いマザボでPCIe4
Redditで「BIOS更新したら5になった」とあったので確認したら5だった(付属のマニュアルの記載は4)
ASUSのB650なんだけど、これが普通なのかな? 普通じゃなかったら、他の方お気をつけてください
306012GBを使ってるのですがflux.1とかqwenとか使うと生成に時間がかかるので5070あたりの買い替えを考えてます
ゲーム目的で9060XT搭載の買って生成方面ではどんなもんなのよと見てみたら5年前のミドルクラスにすら負けてんのか、流石にどうしようもないね
ROCm7.0でradeon全体かなり早くなったらしい
9060XT16GBでcomfyUI(ROCm)で神里ベンチのSDXLで1枚のやつなら12秒台だった
There is definately a lot to find out about this subject. I like all the points you made
最近話題の32GB RADEONでベンチマーク
(1) Hello Asuka Benchmark 未実施
(2) Ayaka XL Benchmark 45s
(3) Ayaka XL x10 Benchmark (a)475s (b)484s
(4) Ayaka XL ControlNet Benchmark (a)327s (b)325s
(5) Helta Hires.Fix Benchmark
(a) 87s(1280,1280)
(b) Tiled VAEのDecoderの最後のステップでループして525s
(6) Helta 4K Hires.Fix Benchmark (a)485s, (b)500s (1280, 1280)
(5)で問題が出た(b)はなぜか普通に動く
(a) i5-12400F, Windows 11 Zuluda, OCuLink PCIex4*4
(b) i5-10400, ubunntu 22.04, ROCM, OCuLink PCIex3*4(3*16でも大差ない)
起動オプション –use-pytorch-cross-attention –fp32-vae (sage環境は作れていない(環境壊れた))
4070で比べるとfastの方が影響が大きかったので影響は少なそう
4070記事結果比較 (2)7.3s(同等) (3)75s(+7s) (4)54s(+8s) (5)38s(+4s) (6)1280 83s, 1024 80s(-15s)
遅いのはCPU性能差として(6)は何かが改善されたせいでRADEONでも実行できるようになったのかもしれない
GPUはR9700じゃなくてLLM用で極一部で話題のRADEON INSTICT MI50 32GB(Radeon VII 32GB相当)です
AliExpのセールで少し安く売っていた(ファン付き送料込み\26K)ので興味本位で思わず買ってしまった
自分で何か冷却方法を考えないと予想通りファンの音がうるさすぎる
CPU:Ryzen AI Max+ 395
GPU:RX 8060S
ドライバ:25.10.2
ライブラリ:ROCm 7.10.0dev+Pytorch 2.10.0a(TheRockリポジトリをCloneしてドキュメント通りにビルド)
でComfyUIを入れてVAEをPytorch Cross Attention有効に書き換えたらアスカベンチ33.82秒でした。(KSampler 28stepsのみは27秒)
9000系ならFP8対応が入るのとLinuxの方ならAMD公式TritonホイールでFlash Attentionオプションも正式に有効にできるので更に速くなりそうです。
デュアルブート環境を構築できたらまた再試します。
RX7000(RDNA3)シリーズ用
rocm.nightlies.amd.com/v2/gfx110X-dgpu/
RX8050/60S(RDNA3.5)用
rocm.nightlies.amd.com/v2/gfx1151/
RX9000(RDNA4)シリーズ用
rocm.nightlies.amd.com/v2/gfx120X-all/
コメ欄見ててもわかるけど、Radeon周りとか事情が変わりすぎて
このページの情報が陳腐化してるから流石に更新した方がいいのでは…
https://wccftech.com/nvidia-to-bring-back-geforce-rtx-3060-q1-2026-tackle-memory-shortages/
やったぜ!
Windows版ComfyUIがROCm7 for Windowsに正式対応しました。
レビュー追試をお願いしたいですね…
https://blog.comfy.org/p/official-amd-rocm-support-arrives
Radeon周りとか事情変わって更新してほしいっていうコメントが多数あるけど
GeForceでさえ特にBlackwellシリーズの最適化が進んで速度が速くなってるので単純にRadeonの最新データを追加して終わりっていうわけにもいかないんだよね。
管理人さんのAI熱が続いていたら2027年くらいに出ると言われているRubinのRTX60xxシリーズが出てドライバやツールも成熟してからすべて更新してくれた方が個人的に助かります。
rtx50シリーズについて、pcie4.0のマザーボードで使った場合に生成速度が低下するのかどうか調べてほしいです。
レーン数が少なく、vram容量も小さいモデルは影響ありそうな気もしています。
我希望询问,radeon,是否使用了zluda。
[…] ラー設定により変動します。参考:ちもろぐ AIイラスト向けグラボ検証、A-X Inc. 生成AI向けグラボガイド […]
2025どころか2026にもなって再販される3060… vram高騰対策の苦肉の策だろうけどかなり長寿だねぇ