
無料で使えるAIイラスト「Stable Diffusion」で、推しのキャラクターや癖に刺さるシチュエーションを狙って生成するには「LoRA」の作成が必要です。
LoRA作成は「学習」と呼ばれ、イラストの生成よりもVRAMの使用量が増えます。必要なVRAMが増えるとLoRA作成に適したグラフィックボードはハイエンドに偏りそうですが、実際はどうなのか?

(公開:2023/8/10 | 更新:2023/8/10)
LoRA(AIイラスト学習)におすすめなグラボを検証
テスト環境:使用したグラボとPCスペックを紹介

| テスト環境 「ちもろぐ専用ベンチ機(2023)」 | |
|---|---|
| スペック | Raptor Lake |
| CPU | Core i9 13900K |
| マザーボード | ASUS TUF GAMING Z690-PLUS WIFI D4 |
| メモリ | DDR4-3200 16GB x2使用モデル「Elite Plus UD-D4 3200」 |
| グラボ | RTX 4090 24 GB RTX 4080 16 GB RTX 4070 Ti RTX 4070 RTX 4060 Ti 16 GB RTX 4060 Ti RTX 4060 RTX 3090 24 GB RTX 3080 10 GB RTX 3070 Ti RTX 3070 RTX 3060 Ti RTX 3060 12 GB RTX 3050 RTX 2080 Ti RTX 2060 12 GB GTX 1660 Super GTX 1080 Ti GTX 1060 6 GB |
| SSD | NVMe 1TB使用モデル「Samsung 970 EVO Plus」 |
| OS | Windows 11 Pro(22H2) |
| ドライバ | NVIDIA 536.67 DCH(cuDNN 8700) |
今回のLoRA学習ベンチマークで使用するテスト機のPCスペックです。
一応、CPUにCore i9 13900K(24コア32スレッド)、メモリ容量をたっぷり32 GBなど。グラフィックボードの足を引っ張らないスペックを使っています。
テストに使用したグラフィックボードは全部で20枚です。
筆者の時間と技術的な都合で、LoRA学習ベンチはすべてNVIDIA GeForceシリーズのみ検証します。AMD RadeonやIntel ArcもLoRA学習が可能だと思われますが、今回は検証から外します。
検証方法:LoRAの学習にかかった時間をテスト
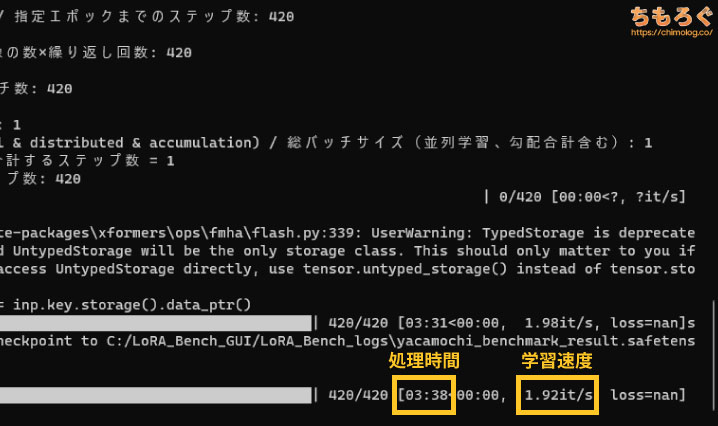
AIイラスト(Stable Diffusion)のLoRA学習におすすめなグラフィックボードをテストする方法はシンプルです。
実際にLoRAモデルを学習させて、学習にかかった処理時間を記録します。速く学習を終えたグラフィックボードが、LoRA学習に適したグラボです。

(LoRA学習で特定のキャラクターや概念を教えられます)
LoRA学習に使うソフトは定番の「Kohya_SS GUI版」です。当ブログのマスコット「やかもち」のイラスト(計21枚)を学習データに用いて、やかもちを生成できるキャラクターLoRAを作ります。
ベンチマークに使用する細かい設定は以下の通りです。
ベンチマーク時のバージョンは以下のとおり。
- GUI:v21.8.5
- python:3.10.6
- torch:2.0.1+cu118
- xformers:0.0.20
- cuDNN:8700
Kohya_SS GUI版で設定したパラメータは以下のとおり。
| LoRA学習ベンチマークの設定 | |
|---|---|
| パラメータ(引数) | accelerate launch –num_cpu_threads_per_process=4 “./train_network.py” –enable_bucket –min_bucket_reso=256 –max_bucket_reso=2048 –pretrained_model_name_or_path=”/7th_anime_v3_ A.safetensors” –train_data_dir=”/train” –reg_data_dir=”/reg” –resolution=”512,512″ –output_dir=”/LoRA_Bench_logs” –logging_dir=”/LoRA_Bench_logs” –network_alpha=”2″ –save_model_as=safetensors –network_module=networks.lora –text_encoder_lr=5e-05 –unet_lr=0.0001 –network_dim=64 –output_name=”yacamochi_benchmark_result” –lr_scheduler_num_cycles=”1″ –no_half_vae –learning_rate=”0.0001″ –lr_scheduler=”cosine” –lr_warmup_steps=”84″ –train_batch_size=”1″ –max_train_steps=”840″ –save_every_n_epochs=”1″ –mixed_precision=”fp16″ –save_precision=”fp16″ –seed=”42″ –caption_extension=”.caption” –cache_latents –optimizer_type=”AdamW8bit” –max_train_epochs=1 –max_data_loader_n_workers=”0″ –clip_skip=2 –bucket_reso_steps=64 –xformers –bucket_no_upscale –noise_offset=0.0 |
- 教師データ:20_yacamochi
- batch size:最高速度に達するまで高い数値に
- epoch:1
- network dim:64
- network alpha:2
- mixed precision:fp16
- optimizer:AdamW8bit
※GTX 10xx~16xxはAdamW
512×512サイズの教師データ(学習元の画像)を21枚用意して、リピート回数を20、周回数(epoch)を1に設定します。21x20x1 = 420ステップの学習回数です。
学習の規模(network_dim)はキャラクターLoRAで割りと見かけるdim=64(約72 MB)とし、alphaはなんとなく2に設定しています。
グラボ別:LoRA学習ベンチマークの結果
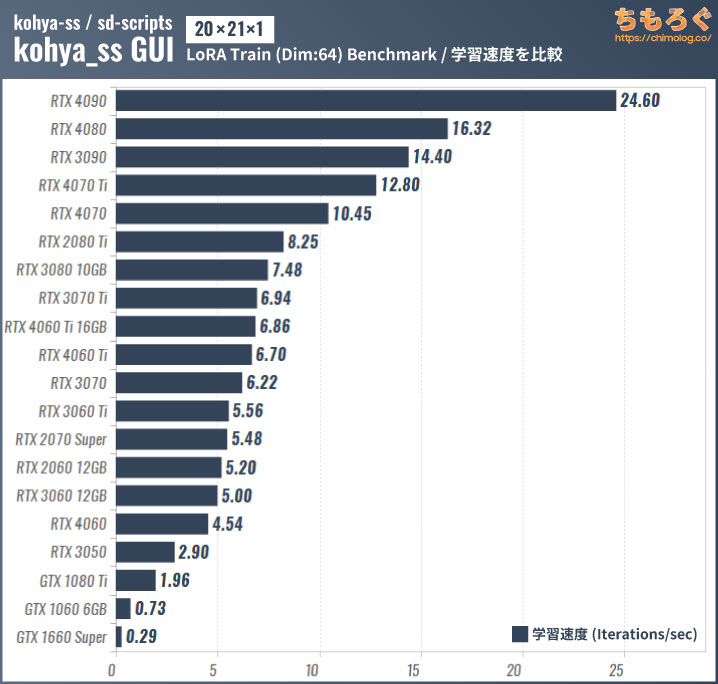
LoRA学習はVRAM容量が多いほど、学習の並列数(バッチサイズ)を大きく設定できます。
だから同じVRAM容量ならグラボの持つ演算性能の差で処理速度が変わり、VRAM容量に差があるとグレードや世代がかえって逆転するシーンも見られます。
たとえばRTX 2080 Tiが分かりやすいです。1世代前のハイエンドでVRAM容量が11 GBあり、後から出てきたRTX 3080 10 GBより学習速度が速いです。
一方、RTX 4060 Ti 16 GBと8 GB版の性能差がほとんどないですが、単にVRAM容量よりも先にグラボの演算性能が頭打ちの状態です。
学習規模(network dim)を引き上げてVRAM使用量を増やしたり、もっとVRAM使用量が多いDreamBooth学習であれば、16 GB版が完膚無きに8 GB版をボコボコに打ち負かすので安心してください。
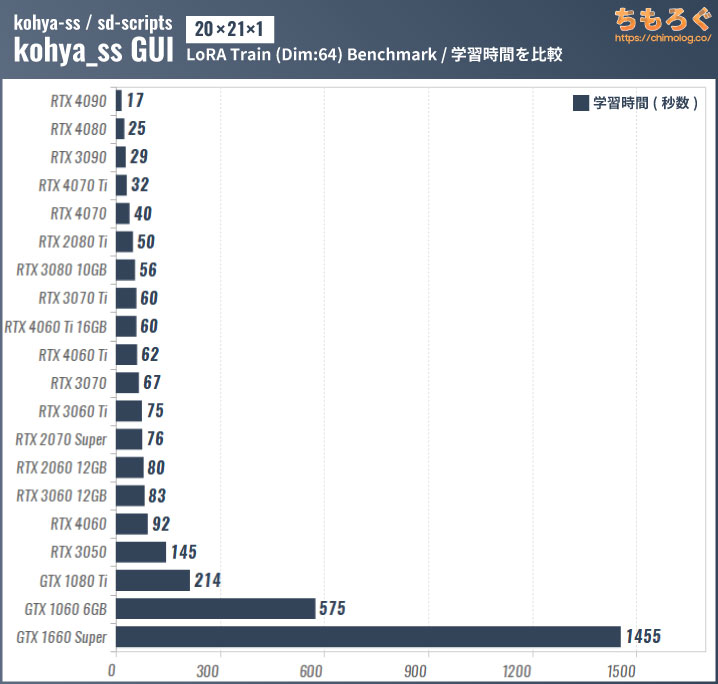
ログに記録された学習時間で比較したベンチマーク結果です。
GTX 10~16番台はLoRA学習にまったく向いていません。差分学習法でミニサイズのLoRAモデルを作るならかろうじて我慢できるでしょうが、容量の大きいキャラクターや絵柄LoRAモデルの作成は待ち時間が長すぎます。
上記のデータはあくまでも1 epochで、実際に高い再現性を持つLoRAを作るなら8 epoch(8倍)や20 epoch(20倍)を使う場合もあります。
安くてVRAM容量が多いRTX 3060 12 GBや、もう少し予算があればRTX 4060 Ti 16 GBがLoRA学習におすすめなグラボです。
バッチサイズ別:学習時間とVRAM使用量
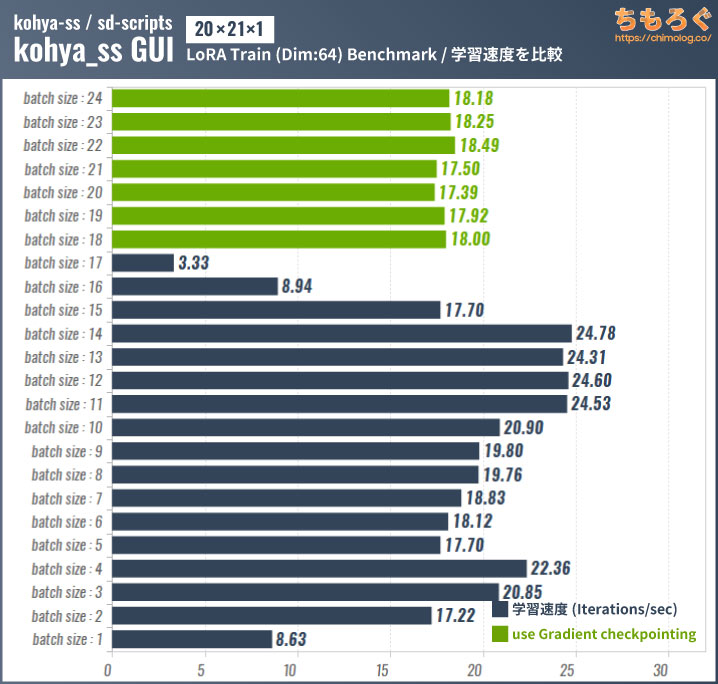
一般向けで最強のAIグラボ「RTX 4090」を使って、バッチサイズ別の学習速度をテストします。
バッチサイズが大きいほどVRAM使用量が増えて学習速度も速くなりますが、VRAMから溢れるほど大きいバッチサイズに設定すると逆に学習速度が下がってしまいます。
VRAMに収まりきらない大きなデータを使う場合は「Gradient checkpointing」にチェックを入れてください。VRAMの利用効率が改善され、VRAMが少ない環境でも学習速度が速いです。
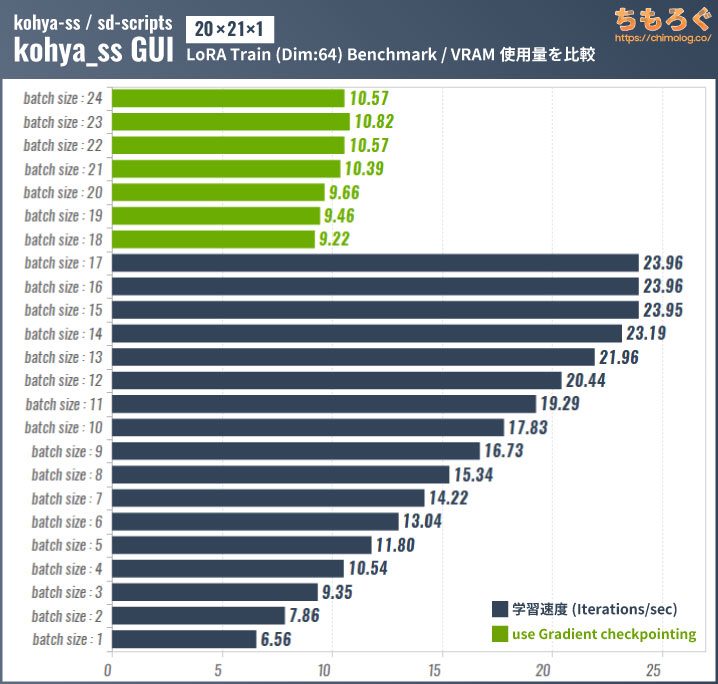
VRAM使用量を確認するとGradient checkpointingの効果は一目瞭然。
ただし、Gradient checkpointingを使うとグラボの性能を100%出せないです。RTX 4090のように巨大なVRAMを持つグラボや、学習内容に対してVRAM容量が足りている状況では使わないオプションです。
Dim(学習規模)別:学習時間とVRAM使用量
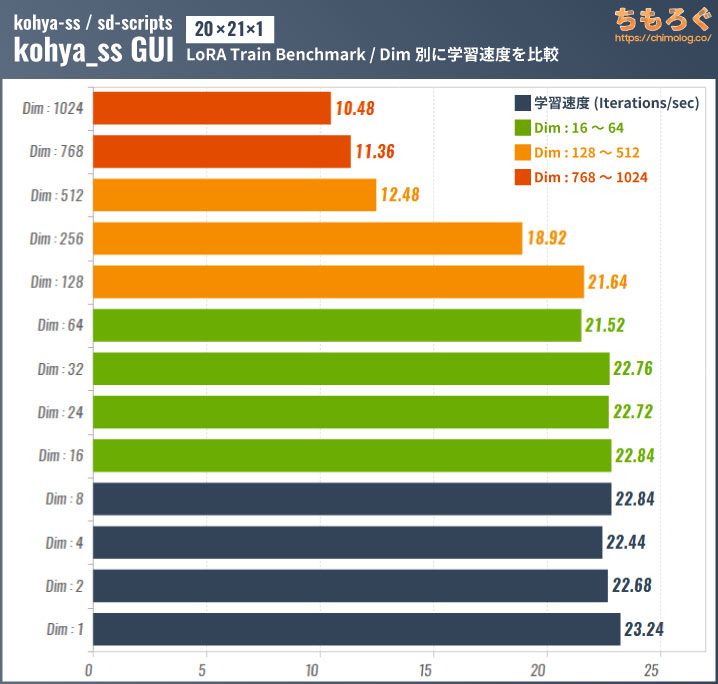
学習規模(network dim)別に、LoRA学習の速度とVRAM使用量をテストします。
ベンチマークの結果、network dim:1~128までほとんど学習速度に変化が出ないと判明。network dim:256から学習速度が下がり、768以上でほぼ半減します。
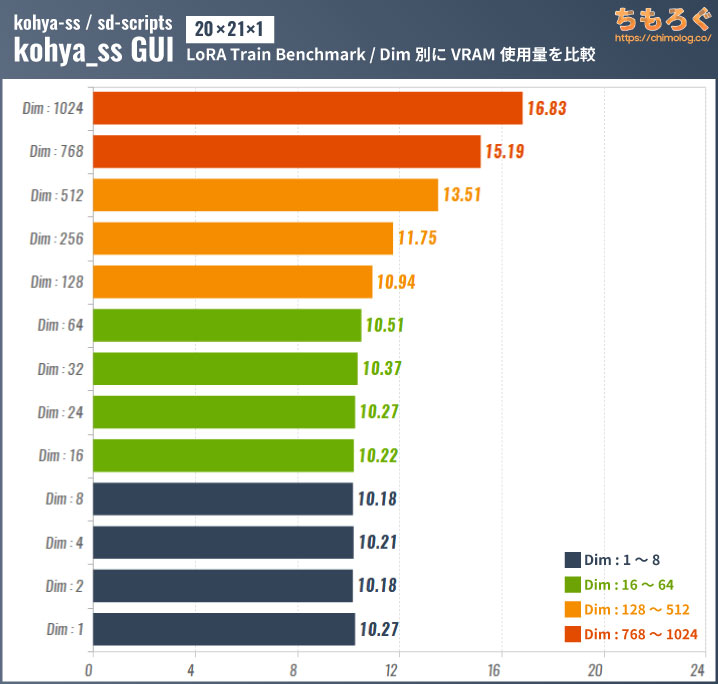
VRAM使用量の変化を見ると、network dim:256からVRAMの使用量が増えていると分かります。
network dim:1024では約17 GBもVRAMを消費しており、ほとんどのグラフィックボードで性能を出せなくなります。が、dim:1024を実際に使うシーンはほぼないです。
今まで見てきたキャラクターLoRAはdim:128~256が多いです。線の太さやディティールを調整するスライダー系LoRAだとdim:4~8が多い印象で、基本的にdim:256以上はあまり使われていません。
そもそもdim:512~1024だと、出来上がるLoRAモデルの容量が約600~1200 MBと巨大になってしまい、LoRAのメリットである「容量が軽い」が失われる本末転倒です。
【参考】DreamBoothベンチマークの結果
今ではほとんど使われていない「DreamBooth」学習のベンチマーク結果も参考程度に掲載しておきます。
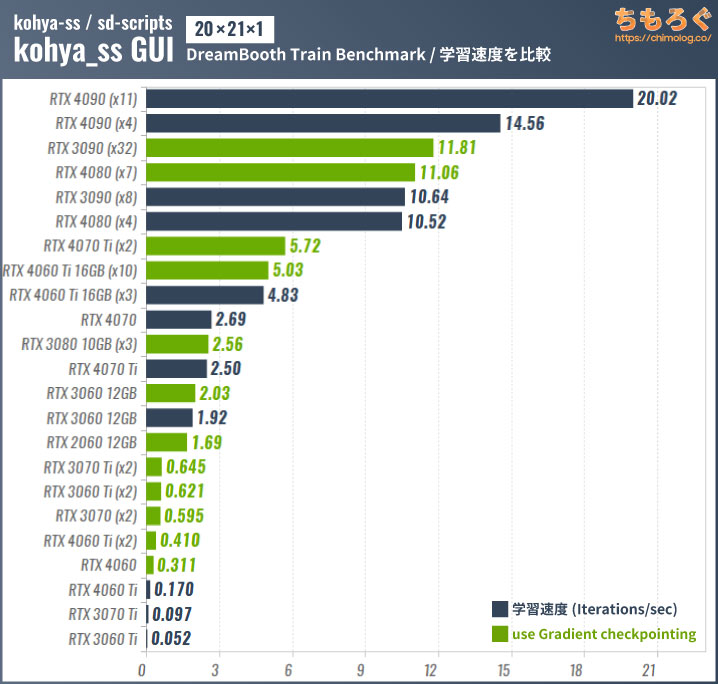
()内はテスト時のバッチサイズ
DreamBoothはVRAMの使用量が多い(batch size:1で約12 GBを消費)ので、VRAM容量が16 GB以下のグラボでは「Gradient checkpointing」を使ってバッチサイズを大きく設定しないと学習速度がうまく出ません。
VRAMが8 GB以下だと「Gradient checkpointing」を使っても学習速度がほとんど伸びず、途方もない待ち時間が発生します。
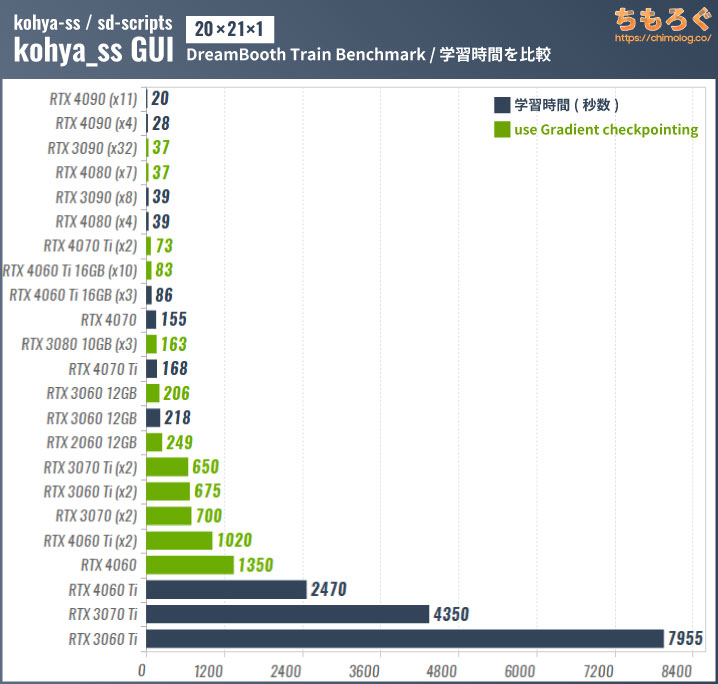
学習にかかった時間を見ると、VRAM格差が分かりやすく反映されます。
RTX 4060 Ti 8 GB版はGradient checkpointingを使っても1 epochに約17分もかかりますが、16 GB版なら1 epochに約1分20秒です。性能差はなんと約12.3倍で、容量16 GBのVRAMが大活躍です。
まとめ:LoRA学習におすすめなグラボ【3選】
今回のLoRA学習ベンチマーク調査で、「AIイラストの学習におすすめなグラボ」がざっくりと判明しました。
RTX 3060 12GB:LoRAに適した低予算グラボ


RTX 3060 12GBは約4万円台の価格で、容量12 GBのVRAMが付いてきます。DreamBooth学習だと少々厳しいですが、負荷の軽いLoRA学習なら問題なく動作します。
複雑なキャラクターや概念を教えられるnetwork dim:256まで対応でき、LoRA学習用にコストパフォーマンスの良いグラフィックボードです。


RTX 3060は12 GB版と8 GB版があります。LoRA学習の場合はベンチマークで見たように、VRAM容量が多いほうが有利です。多少安いからと言って8 GB版を買うのはやめましょう。
RTX 4060 Ti 16GB:LoRA学習でコスパ最強グラボ


約8万円の価格ながら、容量16 GBものVRAMを搭載する「RTX 4060 Ti 16GB」は10万円以下で買える最高のAIグラボです。
容量16 GBのVRAMパワーでnetwork dim:1~512までLoRA学習をこなせます。使うかどうかは別としてDreamBooth学習も対応できます。
生成性能もそこそこ優秀で、2023年7月末に公開された最新のAIイラスト「SDXL 1.0」でネイティブ高解像度なイラスト生成も可能です。
RTX 4090 24GB:学習と生成どちらも最強格グラボ


民生向け(業務向けを含まない)のグラフィックボードで、現行最速モデルが「RTX 4090 24GB」です。
他製品でまったく替えが効かない唯一無二の性能を誇る、文句なしの最強グラボです。予算に糸目をつけず最高のモノを買いたいなら、RTX 4090 24GBで決まりです。
- 最速のLoRA学習速度
- dim:1024まで対応可能
- 最速のDreamBooth学習速度
- AIイラスト生成も最速(SDXL 1.0も余裕)
価格は決して安いとはいいづらいものの、性能面にまったく不満がないです。一度RTX 4090のスピードを知ると、もう二度とRTX 4080以下に戻れないでしょう。

中古グラボなら:もっぱらRTX 3090 24GBが熱い
中古市場で約10~12万円で買えるRTX 3090 24GBがLoRA学習向けに悪くないです。
LoRA学習でRTX 4080に迫る速度、DreamBooth学習でRTX 4080に匹敵します。生成性能も優秀で、SDXL 1.0ならRTX 4080とほぼ同じ生成スピードです。
ただし、中古グラボはマイニングによる経年劣化リスクがあり保証期間も短いです。おすすめしません。
以上「AIイラストのLoRA学習におすすめなグラボを検証【Stable Diffusion】」でした。
LoRA学習でAIイラストの幅を広げよう

AIに新しい概念を教える「LoRA」で、自分が必要とする表現が可能になります。
人間絵師が誰一人として供給してくれないマイナーなキャラクターですら、適切な教師データ(学習元画像)とタグ付けを与えてやれば、再現率の高いLoRAモデルを作成できます。
誰も描いてくれない供給がゼロに近いマイナーキャラや、特定キャラクターの珍しい組み合わせやシチュエーションも、AIイラスト + LoRAで生成が可能です。
あとはラフ画をControlNetに取り込んでポーズや構図を指定したり、モデル側が持つ顔成分を薄めるために他のキャラクターLoRAを混合したり、スケール系LoRAを併用してあえてアニメ調に仕上げたり、InpaintやPrompt Editingで服装を変えたり差分を作ったり・・・などなど。
あらゆる手段を駆使して、自分が頭の中に思い浮かべているイラストに近づける試行錯誤を繰り返します。
たとえば筆者の場合、刻晴(原神のキャラクター)とマツダロードスターの組み合わせで4K解像度の壁紙を作ったり、推しの同人誌風なCG集を作ったりしていて・・・時間の溶け方が異常です。
インターネットに接続せずすべてローカルで完結するため、Google Colabのようにうっかり垢BANを食らう心配もありません。
AIイラストの「生成」におすすめなグラボ

AIイラストの生成におすすめなグラボは↑こちらの記事で検証しました。最新のSDXLでグラボ別に生成速度をベンチマークしたデータです。
RTX 4000搭載のおすすめゲーミングPC【解説】


- 2023/08/10:LoRA学習のGPUベンチマーク結果をアップ(UPDATE !!)












 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選

 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


3090 VRAM 24GBあっても 16GBの4080と変わらなかったり遅いのは意外でした。
また4070系と4080と4090が等間隔くらいにそれぞれクラス格差がしっかりしている印象。VRAM 12GBと16GBが割と差があるなと。
4060Tiの16GB版が8GB版より12倍速いケースありで、8GBでは十分でない場合は4060Ti 16GBの価値がうなぎのぼりですね。16GBの優位性はここぞというときに割と大きく出るんだなと。
学習速度もだけど熱や消費電力も知りたい
基本はcolabで動かしてるけどテストのために自分のPCで動かすとGPUの裏とか激熱になるから…
ほとんどの場合で4070/12GBのほうが4060tiを上回るが、在庫処分したいショップの回し者か?
何を以ってそんなことを言うのか理解に苦しむんだが
4060Ti 16GBが4070 12GBよりほとんどの場合は下になるのは当たり前じゃん
上回るのは「どうしても16GBが必要な場合」だけだよ
4070と4060ti16gbは最安値同士なら価格差4,000円程度で、LoRAに限っては4070のがコスバ良さそうじゃない?
これが「DreamBoothのコスパ」なら4060ti16gbでも不思議じゃないけど、LoRA学習で4060ti16gb押しなのは不思議に思うよ。
画像生成に関してはVRAM正義。今後パラメーター数が多いモデル主流になっていくとして、僅かな速さよりVRAMが4GB多いほうが遥かに重要。
画像生成に関してだけではなく、学習についてもデータ上、Dreambooth以外の結果は4070/12GBが優勢です。
データから見れる”客観的事実”と”希望的観測・予想”を分けたほうが良い。
客観的事実
・「Dreambooth以外の結果は4070/12GBが優勢」
希望的観測・予想
・「SDXLの普及により、よりVRAMの重要性が高まる」
希望的観測・予想を裏付けるには以下の2つの根拠が必要だが、現在はまだわからない
・ SDXLが主流になる
実際問題として、まだNSFWの画像生成がSDXLは弱い
( SDXLはSD1.5と異なり、NSFW画像を学習していないため、NSFW画像の生成に弱い。NSFW画像生成を甘く見ているのかもしれないが、これが生成できるか、できないかで大きくユーザー数が変化する.ソースはCivitaiのモデルでNSFW,Sexy,Porn系のモデルの人気を見ればわかる)
・ SDXLのLora生成が4060 16GB版より早い
(これ当たり前だと思っているかもしれないけど、そもそも、SDXL自体が容量大きすぎて、結局CPUメモリ使うのであれば、4070 12GBとそんな変化ないかもしれないし、SDXLの学習計算自体がボトルネックになる可能性もある。正直やってみないとわからない)
今後、Vramが重要になってくるという予想は持っているけど、正直16GBと12GBでそこまで大きな変化が生まれるか、は現在ではわからない。
だから、現状、コメ主の「4070/12GBが優勢」という主張は正しいと思う。
RTX A4000なら7万円で買えます(買いました)ね、まぁコアは3070Tiのでクロックダウンさせて性能的に事実上のRTX 3060Ti 16GBなのでコスパは微妙ですけど(ワッパは多少GeForceよりQuadro系の方が良いとはいえ4060Ti同等か若干悪い)
学習に特化した場合のコスパの話なんだから
VRAM16GB積んだ4060Tiが上位に来てもおかしくないでしょ
新品中古を含めてほかに16GB積んでいる8万以下で買えるグラボある?
Vtuberの使う3Dモデル作りに特化したイラスト描きユーザーやLive2D使いが居るように、学習モデル作りに特化したユーザーがこれから出現しないとも限らない
生成に関してはな
だがこの記事は学習の話だろ?
「やかもち」ちゃんのエ〇同人待ってます!
自分で書くんだよ
そして読ませろ
検証お疲れ様でした。
自作erでキチンと生成AI検証しているのは、やかもち氏しか見たこと無いです。
他の連中は相変わらずPCゲーム (原神は含めない) のベンチマーク回して「ゲーム最強!」と莫迦の一つ覚えで連呼しているだけ。
うんざりしてます。
FPSを4kで全部最高設定でやるみたいな検証は見るだけでうんざりする
ほんとこれ
海外も含めたほかのサイトやメディア、個人から大手Youtuberまで
みんなゲーム関連のベンチしかしないから
やかもちさんみたいなAI深堀りベンチはホント助かる
ここのAI関連の記事のせいで、グラボが品薄になりませんように。
AI画像生成で3060 12gbが入門に最適とさんざん言われているのに順調に値下がりしてるから大して影響ないんじゃないの?
1660tiを安価で買ったけど
色々なお遊びのためにここみて3060-12GBに買いなおした
動画の高解像度ソフトもゲームではさほど差がないのに、RTXとGTXで4倍くらい速度差がある
2070superのが安いんだけどね 8GBと消費電力がね…
4060-12GB出ないのかしら
わたしもRTX4060-12Gに期待したいけど、2024年に入っても動きなし…
3080でも12G版なら2080tiよりスコア高くなるのかな?
3080の12GBは3080TiにAI関連では近そうですね。
3080Tiのデータが無いですが、4070 12GBとの差を考えると11GBの2080Tiを上回る可能性大だと思います。
LoRA学習に要する時間
4090 17s
4080 25s
3090 29s
4070 40s Ti 32s
3080 56s
3070 67s Ti 60s
3060 83s
4060 92s Ti 60s
4090は3090の1.70倍速
4080は3080の2.24倍速
4070は3070の1.67倍速
4060は3060の0.90倍速
4060だけ先代よりVRAM容量減っているので順調な伸びではないのも見て取れますね。
再検証お疲れ様です。
AI動画(t2v や i2v)界隈が熱くなっていたので、
学習面で4060Ti 16GBがどんな感じか気になっていたところでした。
帯域が足を引っ張るかと思いきや、VRAMマシマシ16GBの効果のほうが大きくコスパ良くなっていたんですね。
今の最安7.78万円(MSI)からもうちょっと下がってくれると嬉しいのに…。
価格的に3080Tiや4070Tiが買えてしまいますが、
同じVRAM16GBでメモリー帯域256bitなRTX A4000の存在も気になります。
・4060Ti 16GB 8万
(3080Ti 12GB)
(4070Ti 12GB)
→A4000 16GB 12万
・4080 16GB 17万
検証お疲れ様でした。意外にも一般消費者向けビデオカードでAIのベンチマークを測っている方は少ないので、こういった情報は非常に助かります。
バッチサイズについて、今回はVRAMが許す限り大きくしたとのことでしたが、
「バッチサイズは大きければ大きいほど良いというものでもない(ミニバッチ学習)」と思うのですが、それについてどのようにお考えでしょうか?
確かにバッチサイズが大きければ大きいほど、学習スピードは速くなります。ただ、学習データ1枚1枚の特徴量が抽出されにくくなってしまうという問題も生じてしまいます。今回の検証で、バッチサイズを変化させたことで、学習結果に大きく変化はございましたでしょうか。ぜひこの点について教えて頂きたいです
この指摘重要だと思います。
画像生成においてはバッチサイズを変更したことにより、生成画像が変更されることはほとんどありません。
(単に同時並行で実行されているだけ。それぞれの生成が他の生成に影響しない)
しかし、学習における”バッチサイズ”は画像生成時の意味する”バッチサイズ”とは異なります。
コメ主のご指摘の通り、ミニバッチ法のミニバッチサイズが変更されるので、異なる計算になります。
おそらく、生成されているLoraも異なるLoraになっているはずです。
その影響がどうなっているのか、気になりますね
検証お疲れ様でした。
検証内容というより用語に関するものですが現在の「LoRA学習」と呼ばれているものの大半が「LoRAを用いたDreambooth」学習です。
なのでDreambooth学習は今使われていないというのは語弊のある表現となります。
4060ti 16GBのVRAM容量は確かに魅力的だけど、値段が落ち着くまではほぼ同価格でVRAM12GBと遥かに高い演算力を持つ4070の方が良いと思うんだけどな
VRAM16GB以上の4060tiより高性能なRTXとなると、一気に値段が倍増する4080になるのが悔やまれる
流石に3090は今買うには…だし
見てみたところ4060ti 16GBはもう7万台がちらほら出てきているんだね
私もAI絵をそこまでやってる訳ではないけど、SDXL路線のVRAM is 正義な生成スタイルが流行していくのであれば選択肢としてはかなりアリ寄りになりそう
(7.5万ぐらいまでは落ちてほしいところですが)
4070と4060Ti 16GBが同価格なら、12GBで足りることが多いでしょうから4070がベストだと思います。
今日の時点では、4060Ti 16GBは77,800円(joshinでポイント還元が11678円あるので実質的には66,122円)で、少し安いくらいにはなっているようですが。
今は4060 Ti 16GBを買うべきではないと思います。
その理由は、VRAMをギリギリまで消費するタスクを実行すると速度が非常に遅くなるという問題があるためです。
詳細についてはAutomatic1111のissuesをご確認ください。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/11063
536.67のリリースノートでも、この問題が発生していることをNVIDIAが認めています。(なお、536.99のリリースノートでは、Stable Difussionに関する部分の記述だけが削除されていますが、修正されていません)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/11063#issuecomment-1666949472
現在主流のSD1.5系においては、512×512解像度でLoRA学習を行う場合、VRAMがギリギリになることはありませんので遅くなりませんが、
SD1.5の1024×1024解像度でバッチサイズを上げてLoRA学習を行う場合や、生成時にControlNet+LoRA+Hires.fixを使用した高解像度生成、
SDXLのLoRA学習ではVRAM16GBであってもVRAMがギリギリになると思いますので、非常に遅くなると思います。
この現象を回避するためには、ドライバのバージョンを531.61以下にダウングレードする必要があるのですが、
4060 Ti 16GBがサポートされたのは536.67からなので、4060 Ti 16GBを使用する場合、この問題を回避することができないのです。
なので、4060 Ti 16GBで高解像度の生成や学習もやりたい人はドライバの修正を待ってから買うべきだと思います。
本件ですが2023/10/31にリリースされた546.01でNVIDIAコントロールパネルの設定から除外できるようになったので、問題は解消されました。
This issue should now be entirely resolved. NVIDIA has made a help article to disable the system memory fallback behavior. Please upgrade to the latest driver (546.01) and follow the guide on their website: https://nvidia.custhelp.com/app/answers/detail/a_id/5490
4070Tiを使用しているのですが、LoRA学習のパラメータで-no_half_vaeをつけた場合、処理がかなり遅くなってしまいました。この辺りのパラメータは環境によって煮詰め具合が違ってくるのでアレなのですが、おそらく全て同じ設定にした場合に実際の最適値で行った場合より違う数値になってくると思われます。
追記、ですので先日まで3080の10GB版を使用していましたが、詳しくは書けませんがステップ数4500の学習が1時間15分程度掛かっていましたが4070Tiの場合、約25分程度まで処理時間が短くなりました。データは同じですが、この辺りもパラメータの違いとかも出ているのかもしれないです
そんなにグラボ持ってるならワークステーション向けも買ってみたら?w
正直sdxlLightning等の高速化が凄いので(最終的に電力制限60%の3060.12gbで8バッチで1024×1356,1枚10秒でできるとこまで来た)マルチキャラLoraとかを作るのでなければ4090は要らないかなぁ
単独キャラloraもprodigy法なら1時間〜2時間でできるし最終的に60クラスのVram大きいバージョンですむようになりそう。(1日5000枚、とか2,3loraなら)