ローカル環境で軽快に動作でき、Webサービス版の動画生成AIにも迫る生成品質を誇る「Wan2.2」モデルが大人気です。
そのWan2.2の推奨スペックを検証した記事で、「VRAMは16 GB以上欲しいかも」と結論を出しました。しかし、「BlocksToSwap」を使えば12 GBまで裾野が広がるらしいです。
(公開:2025/8/14 | 更新:2025/8/14)
「BlocksToSwap」でVRAMの比率を最適化
前置き:VRAMに入り切る軽量化モデルはダメ?
Wan2.2は、品質をなるべく維持しつつモデルサイズ(= VRAM使用量)を大きく削減した、「量子化モデル」が用意されています。
モデルサイズが小さいほどVRAM使用量を減らせるメリットがある一方、計算量もある程度比例して減ってしまい、せっかくの品質を損なう可能性が高いです。
| Q2_K版 (VRAM:~ 12 GB) | Q3_K_M版 (VRAM:~ 16 GB) | 14B_Fp8版 (VRAM:~ 32 GB) |
|---|---|---|
RTX 5090を使って、まったく同じ設定でモデルだけ切り替えて生成したサンプル映像です。
軽量なモデルになればなるほど、目で見て分かるレベルで品質が劣化します。映像のアーティファクト(ガビガビ)具合や解像度の粒度まで、画質が明らかに悪いです。
- VRAMに入り切る軽量化モデルはダメ?
結論、Wan2.2を動かすだけなら軽量化モデルは大いに便利ですが、肝心の品質を目当てにするなら・・・軽量化モデルに過度な期待は禁物です。
問題:高品質モデルはVRAM容量もたくさん必要
共有メモリ(漏れ)VRAM使用量
| Wan2.2(モデル一覧) | モデルサイズ |
|---|---|
| 27B_fp16.safetensors (※オリジナル版) | 53.3 GB |
| 14B_fp16.safetensors | 26.6 GB |
| Q8_0.gguf | 14.3 GB |
| 14B_fp8_scaled.safetensors | 13.3 GB |
| Q6_K.gguf | 11.1 GB |
| Q5_K_M.gguf | 10.0 GB |
| Q4_K_M.gguf | 9.0 GB |
| Q3_K_M.gguf | 6.7 GB |
| Q2_K.gguf | 4.9 GB |
モデルサイズが大きいほど、VRAMの使用量も増えます。
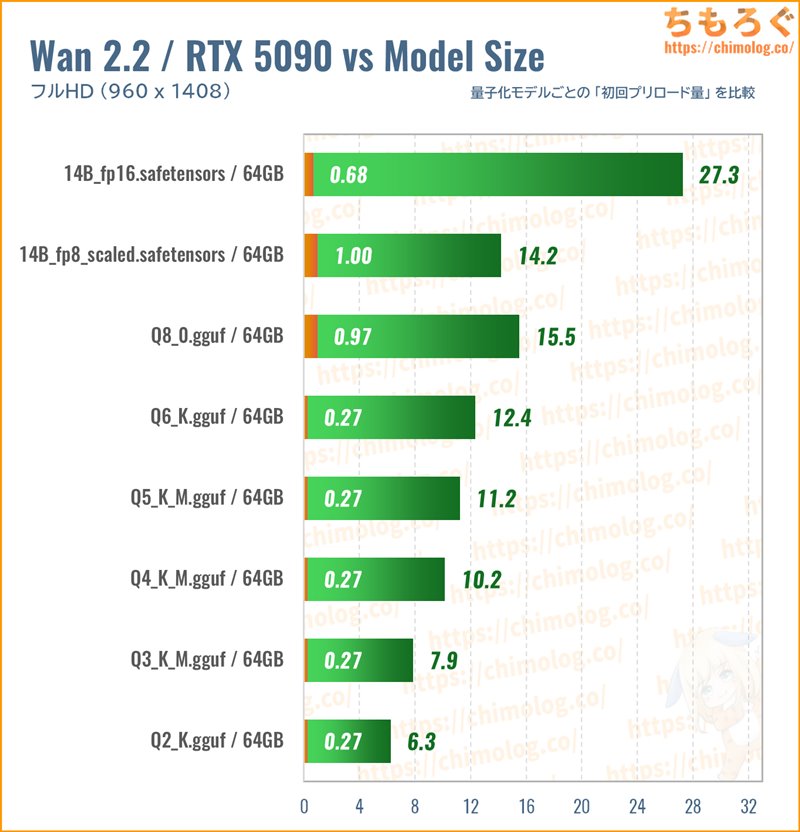
オリジナル版(27B)を半分に小型化した「14B_fp16」ですら、約27 GBものサイズです。試しにRTX 5090(32 GB)でロードすると、VRAM使用量は約30 GBに達します。
VRAM容量が20 GBにも満たないコンシューマ向けグラボにとって、14B_fp16版は大きすぎて論外です。
現実的にギリギリ使えそうな大型モデルは「Q8_0」や「14B_fp8」以下に限られます。Q8_0版や14B_fp8版なら、VRAM容量16 GBでギリギリ収納可能です。
さらに、VRAMの利用比率を最適化する「BlocksToSwap」を使えば、VRAM容量12 GBでも希望が見えてきます。
解決:「BlocksToSwap」でVRAM比率を効率化
Wan2.2の生成に対応する「ComfyUI」自体、とても省VRAM性に優れたソフトウェアです。
しかし、いくら省VRAM性に優れたComfyUIでも、Wan2.2の大型モデルを公式ワークロードで動かすと初回プリロードですら乗り越えられないグラボが多かったです。
- ComfyUI-WanVideoWrapper(github.com)
VRAMが足りない問題に対して、海外の有志ユーザー(kijai氏)が「WanVideoWrapper」なる拡張プラグインを開発しています。
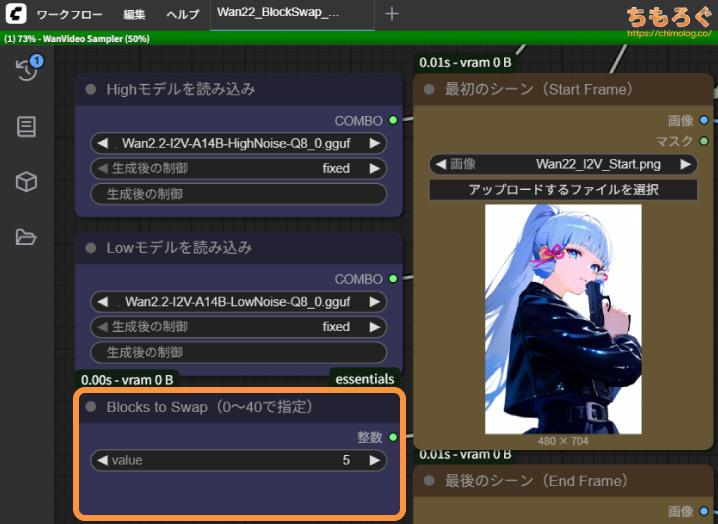
その拡張プラグインの中に、VRAM比率をコントロールして少ないVRAM容量で大型モデルを動かせるようにする「BlocksToSwap」機能が盛り込まれています。
今回の検証記事では、上記の機能を使ってRTX 5070で大型モデルが動くか検証します。
「RTX 5070 12 GB」で重量版Wan2.2を動かす
テスト環境:使用したグラボとPCスペックを紹介

| テスト環境 「ちもろぐ専用ベンチ機(2025)」 | ||
|---|---|---|
| スペック | NVIDIA GeForce | |
| CPU | Ryzen 7 9800X3D(レビュー) | |
| マザーボード | ASUS TUF GAMING X670E-PLUS WIFI | |
| メモリ |
| |
| グラボ | ZOTAC RTX 5070 12GB(レビュー) | |
| SSD | WD Black SN850X 8TB → 8 TB版レビューはこちら | |
| OS | Windows 11 Pro (24H2) | |
| 生成ソフト | ComfyUI v0.3.49 pytorch 2.7.1 + cu128 | |
| –use-sage-attention –fast ※高速化オプション | ||
| ドライバ | Game Ready 572.83 WHQL | |
| ライブラリ | NVIDIA CUDA | |
今回のWan2.2ベンチマークで使用するテスト機のPCスペックです。
BlocksToSwap機能はVRAMとメインメモリの比率を変更して、通常は動かせないサイズのモデルを動かせるようにする仕組みです。
- DDR5-5600 128GB(64GB 2枚組)
- DDR5-5600 64GB(32GB 2枚組)
メインメモリが生成速度に大きく関わる可能性が予想されるため、メモリの容量を2パターン用意しました。


ベンチマーク設定:解像度「720p」を5秒生成
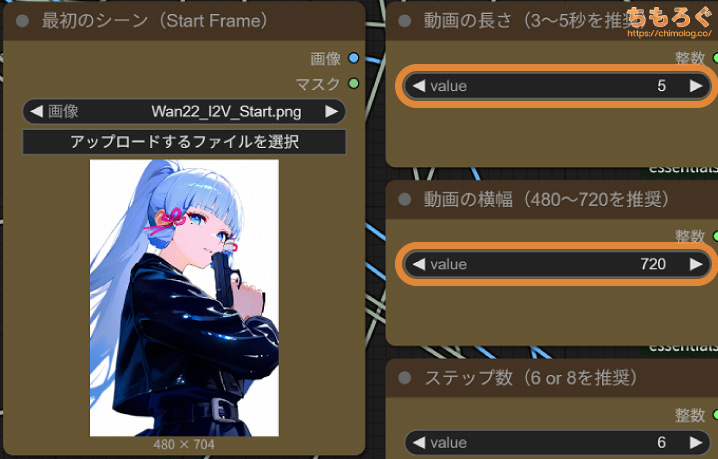
静止画から動画(I2V : Image to Video)を生成します。解像度は720p(720 x 1056)、動画の長さは5秒(81フレーム)です。
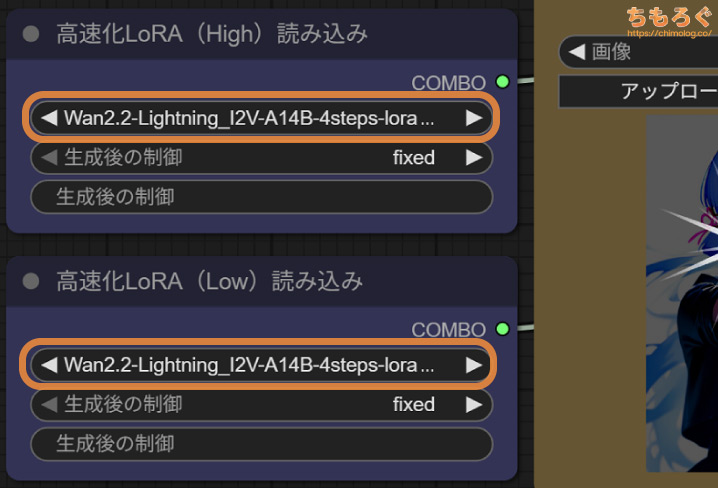
高速化LoRA「Lightx2v(4 steps)」を適用して処理を高速化します。もともと10~20ステップ必要な処理を、3~4ステップまでカット可能です。
今回はHigh側を3ステップ、Low側も3ステップで合計6ステップです。CFGスケールは両方とも「1.0」です。0.9や1.1など、1.0以外を入れると速度が50%鈍化します。
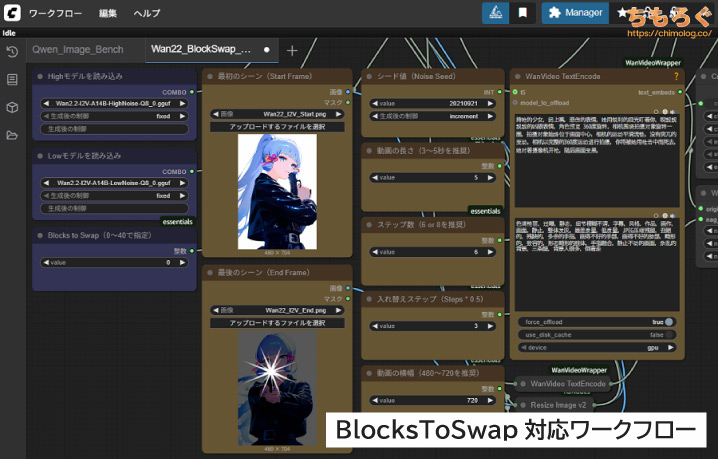
(ベンチマーク用に自作)
ベンチマーク用のワークフロー(Workflow)は、筆者が自作したテンプレートを使います。
- Wan22_BlockSwap_Bench.zip(BlockSwap対応版)
ダウンロードした.zipファイルを展開して、中に入っている.jsonファイルをComfyUI画面に放り込むだけでテンプレが開きます。
Wan2.2モデル本体や高速化LoRAモデルなど、必要なファイルはComfyUI-Managerが親切に表示してくれるので、検索してダウンロードしてください。
RTX 5070 + メモリ容量:64 GBの場合
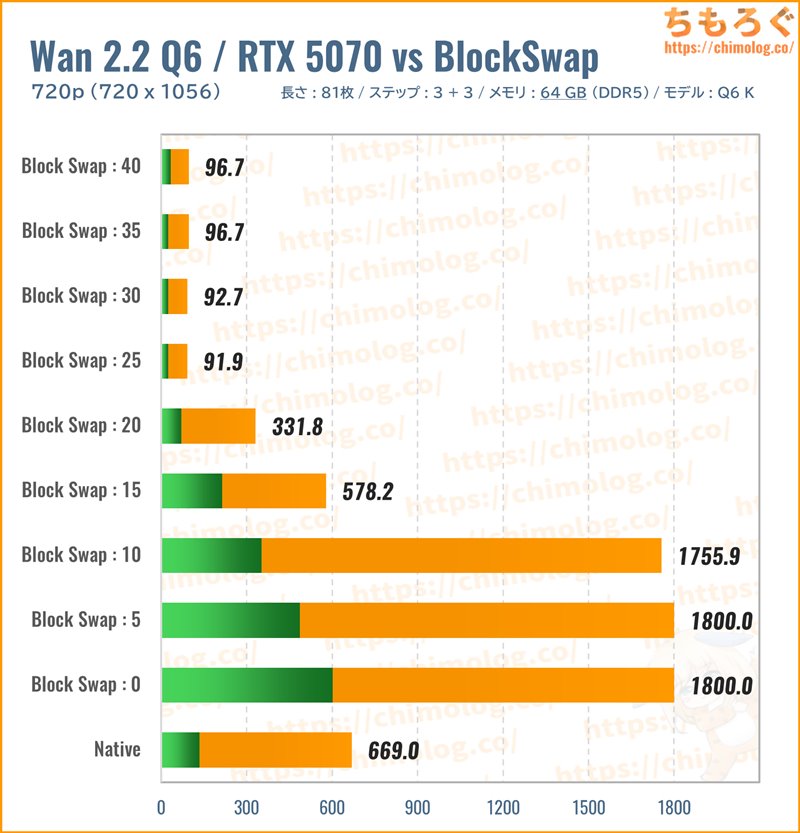
生成時間(秒)共有メモリ(MB)
標準的なサイズ感の量子化モデル「Q6_K.gguf(約11.1 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
ネイティブモードだと当然ながら初回プリロードだけでVRAM容量の大部分を消費してしまい、生成に必要なVRAMを確保できず大幅な速度低下です。
次に「BlocksToSwap」を5ずつ増やしていきます。0~10(VRAM比率100~75%)まで共有メモリ漏れが止まらずひどい遅さです。
15~20(VRAM比率68~50%)でようやくネイティブモードより高速化し、25(VRAM比率37%)以上からRTX 5070の性能をほぼ100%出し切れます。
もっとも生成時間が短い設定は「BlocksToSwap:25」です。生成に必要なVRAM容量のうち、63%をメインメモリに移動して効率よく処理します。
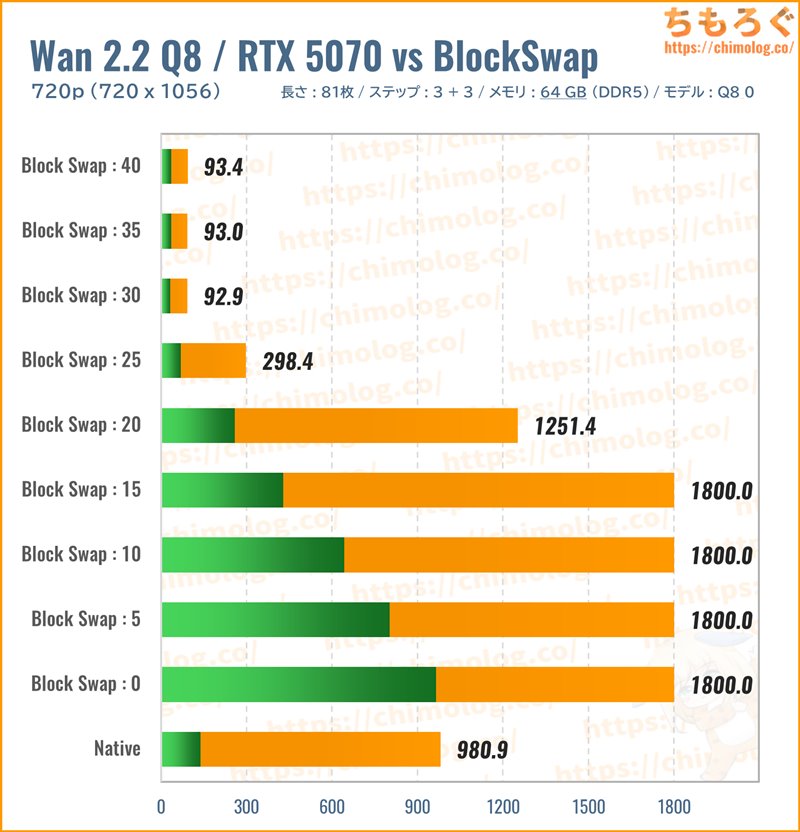
生成時間(秒)共有メモリ(MB)
実用的な性能を出しやすい大型な量子化モデル「Q8_0.gguf(約14.3 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
ネイティブモードは初回プリロードだけで一杯です。BlocksToSwapを0~20(VRAM比率100~50%)まで、まったく動作しません。
30(VRAM比率37%)以上からVRAMに余裕ができ、RTX 5070で難なくQ8_0.gguf(約14.3 GB)を処理できます。
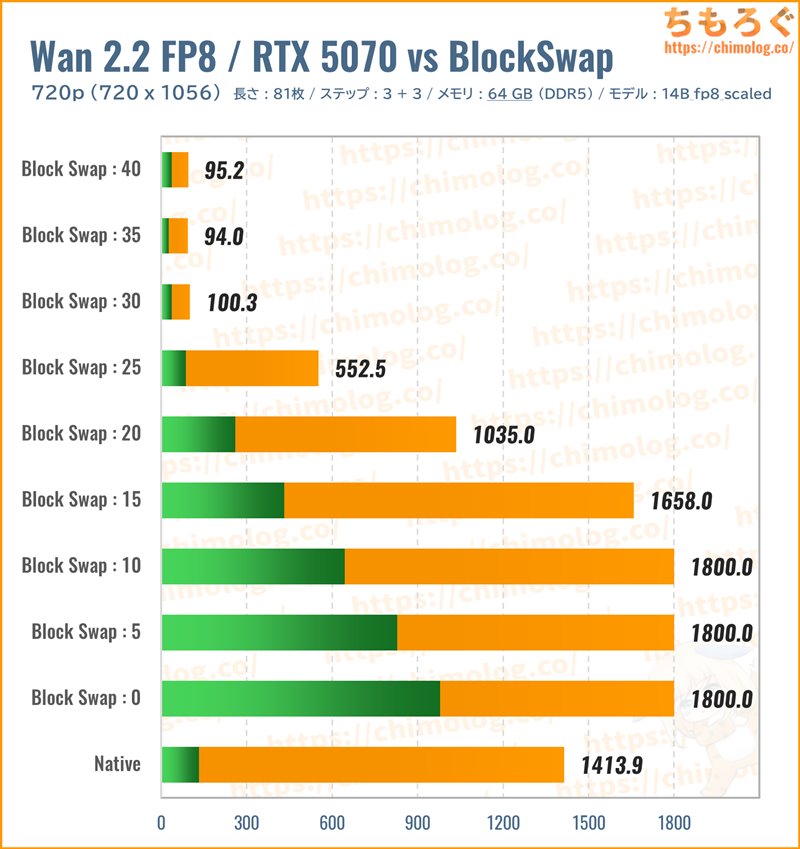
生成時間(秒)共有メモリ(MB)
オリジナルモデルを4分の1まで小型化した量子化モデル「14B_fp8_scaled.safetensor(約13.3 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
ネイティブモードは初回プリロードだけで一杯です。BlocksToSwapを0~25(VRAM比率100~37%)まで、ほとんど生成速度を出せません。
30(VRAM比率37%)以上からVRAMに余裕ができ、VRAM容量が12 GBしかないRTX 5070でも14B_fp8_scaled.safetensor(約13.3 GB)を動かせます。
RTX 5070 + メモリ容量:128 GBの場合
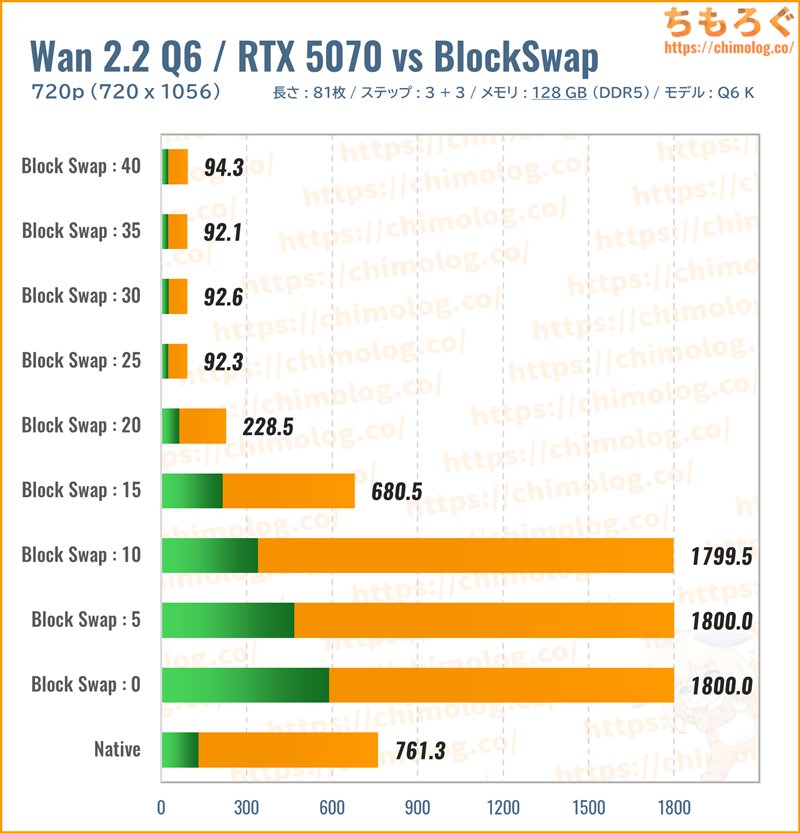
生成時間(秒)共有メモリ(MB)
標準的なサイズ感の量子化モデル「Q6_K.gguf(約11.1 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
メモリ容量を128 GBに増設した結果、メインメモリの使用量が少し増えて、全体的に生成時間がわずかに短くなりました。
それでもBlocksToSwapを入れなければマトモに動かない状況に変わりなく、メモリを増やして得られる恩恵はあまり多くない印象です。
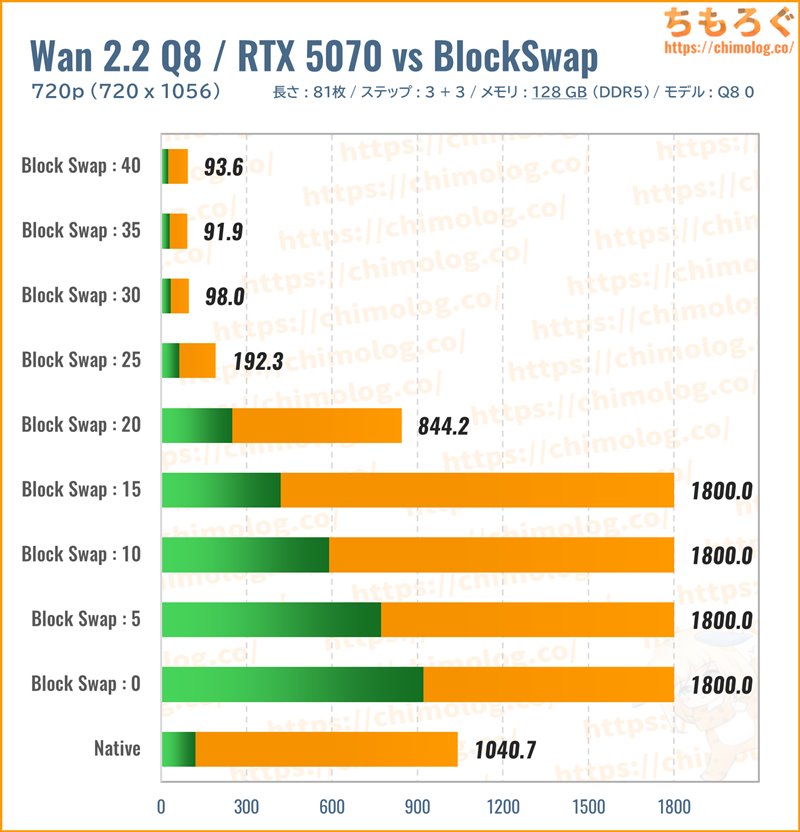
生成時間(秒)共有メモリ(MB)
実用的な性能を出しやすい大型な量子化モデル「Q8_0.gguf(約14.3 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
メモリ容量64 GBと比較して、生成時間の傾向に想定以上の変化がなく、正直ちょっと落胆しています。せっかくメモリ容量を128 GBまで盛っても、VRAM容量12 GB程度だと速度低下を防げないです。
結局、BlocksToSwapを使ったほうがはるかに効率よく生成時間を高速化できます。
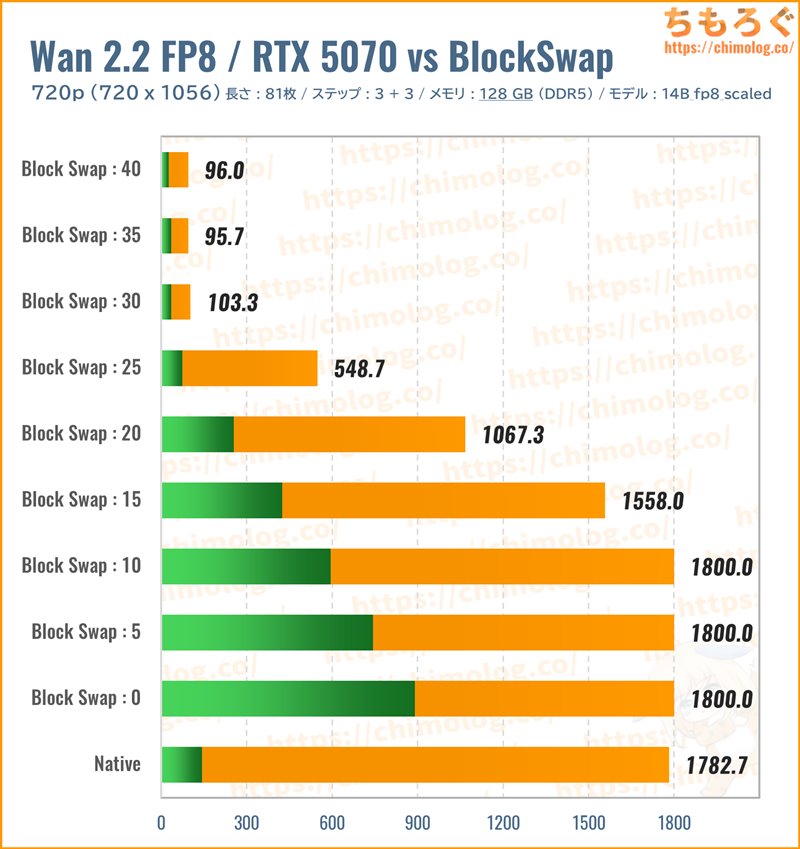
生成時間(秒)共有メモリ(MB)
オリジナルモデルを4分の1まで小型化した量子化モデル「14B_fp8_scaled.safetensor(約13.3 GB)」を読み込み、BlockSwapごとの生成時間を比較しました。
ネイティブモード時の挙動がやや変化し、メインメモリの使用量が10 GBほど増加します。もちろん、メインメモリはVRAMと比較して大幅に遅い領域なので、速度ペナルティをまったく補えないです。
RTX 5070(VRAM:12 GB)で大型モデルを使う場合、メモリ容量よりもBlockSwap(VRAM比率)が効果的です。
メモリ容量:64 GB vs 128 GB
一応、メモリ容量の違いでどれくらい生成時間を短縮できているか、分かりやすく比較するグラフを確認します。
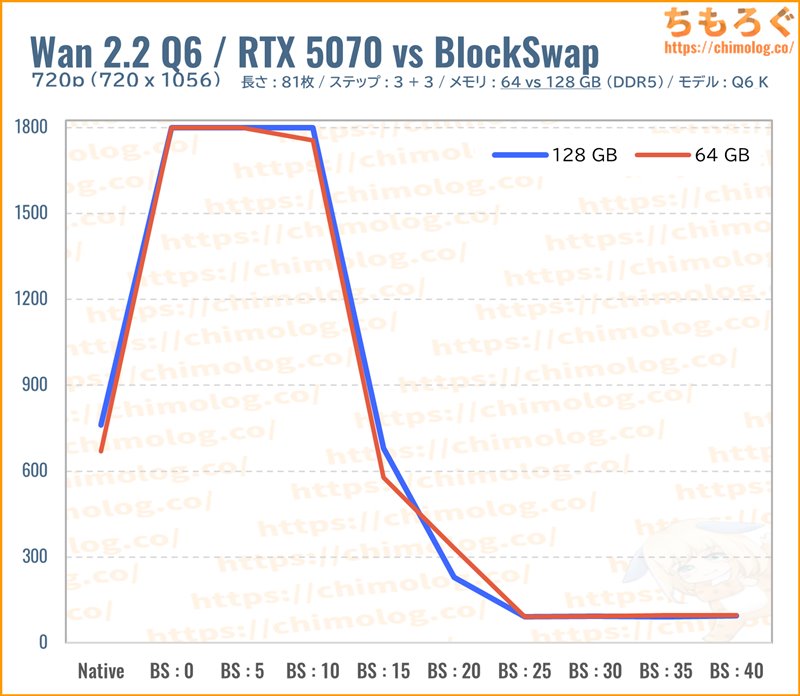
「Q6_K.gguf(約11.1 GB)」は、メモリ容量の影響がほとんど無かったです。ほんの少しだけ128 GBが有利な程度です。
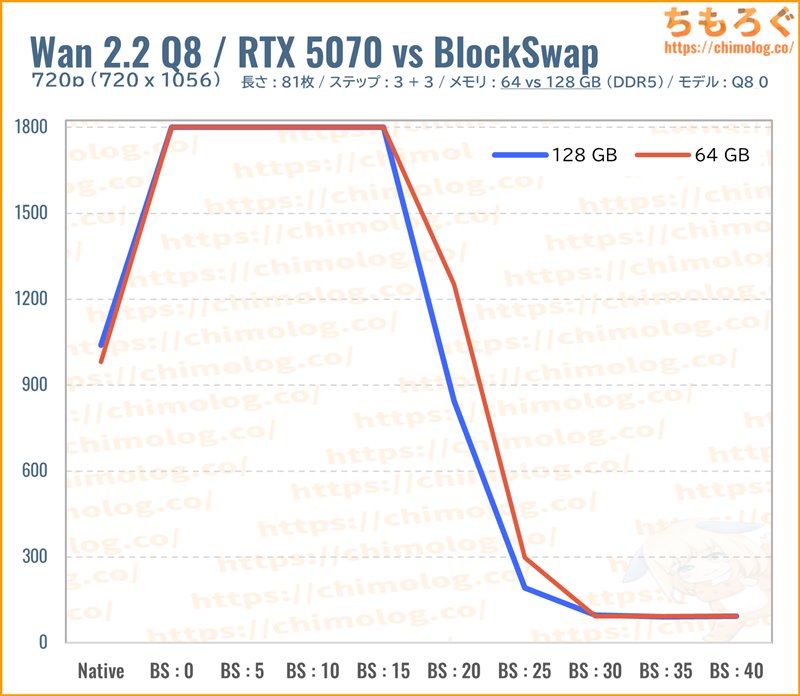
「Q8_0.gguf(約14.3 GB)」では、全体的にメモリ容量128 GBが目立って速くなる傾向があります。
と言っても、BlockSwap(VRAM比率)を導入する方がやはり効率的です。
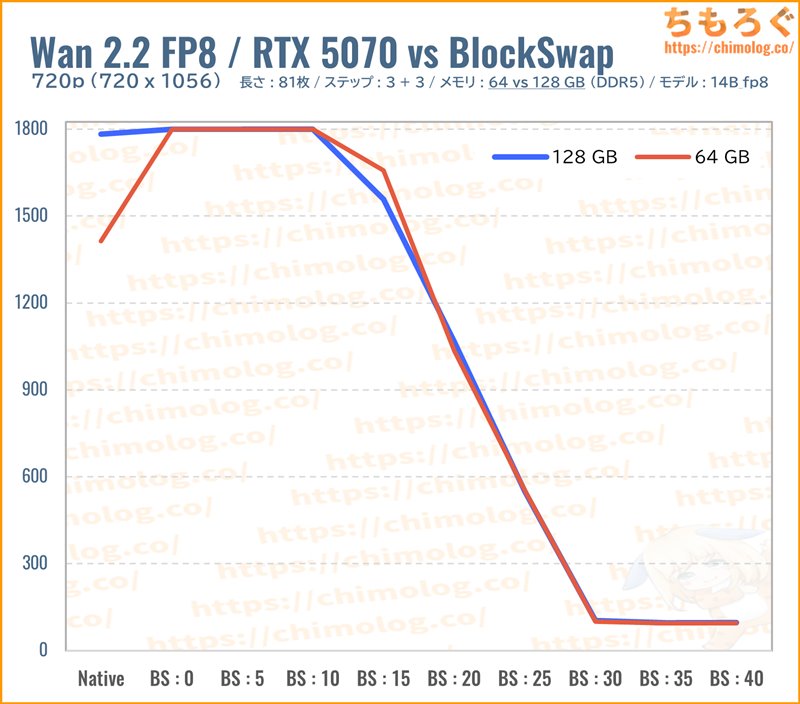
「14B_fp8_scaled.safetensor(約13.3 GB)」の場合、メモリ容量の性能差がまったく出なかったです。
びっくりするほど両者ともに同じ生成時間で変化がないです。メインメモリの消費量が増えたネイティブモード時だと、逆に64 GBの方がわずかに速かったほど。
まとめ:BlockSwapならRTX 5070も動画生成できます
以前のネイティブモードだったら、VRAM容量が12 GBしかないRTX 5070は動画生成AIで大型モデルを扱えず、品質の低い生成で妥協するしか無かったです。
しかし、今回の検証でBlockSwap(VRAM比率)を適切に扱えば、RTX 5070でも大型モデル「Q8_0」や「14B_fp8_scaled」を高速に動かせると判明。
低解像度な480pはもちろん、Wan2.2がターゲットにしている720p解像度もかなり現実的な速度で出力できます。
BlockSwapを最適化するコツを解説
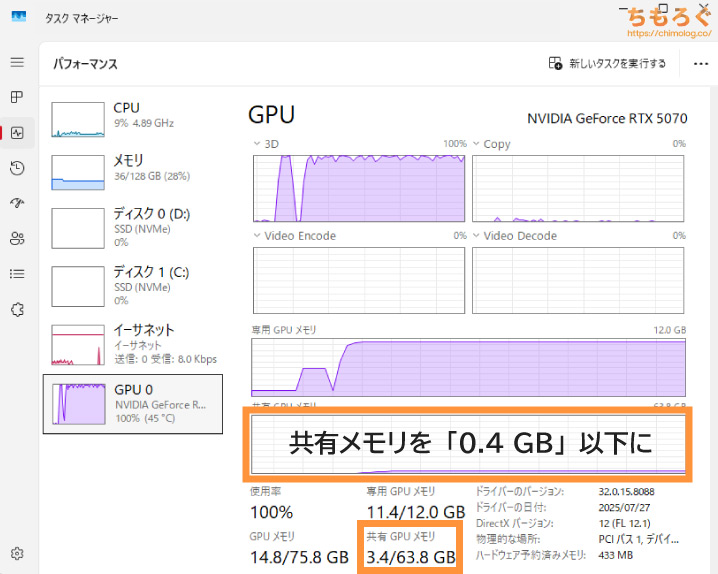
「BlocksToSwap」の設定値を最適化する方法はとてもシンプルです。
- タスクマネージャー「GPU」を開く
- 共有GPUメモリの使用量をチェック
- 「0.4」GB以下に収まっているか確認
Wan2.2モデルの初回プリロードを終えたあと、動画生成が始まってから共有GPUメモリの使用量が「0.4 GB」を超えないか要チェック。
0.5~0.6 GBを超えたあたりから、指数関数的に生成時間が鈍化し続けるため、0.4 GB未満が目安です。
BlocksToSwapを最適な数値に割り当てていれば、基本的に0.4 GB未満に収まります。実際に今回のベンチマークの場合、共有GPUメモリ使用量は平均300 MBです。
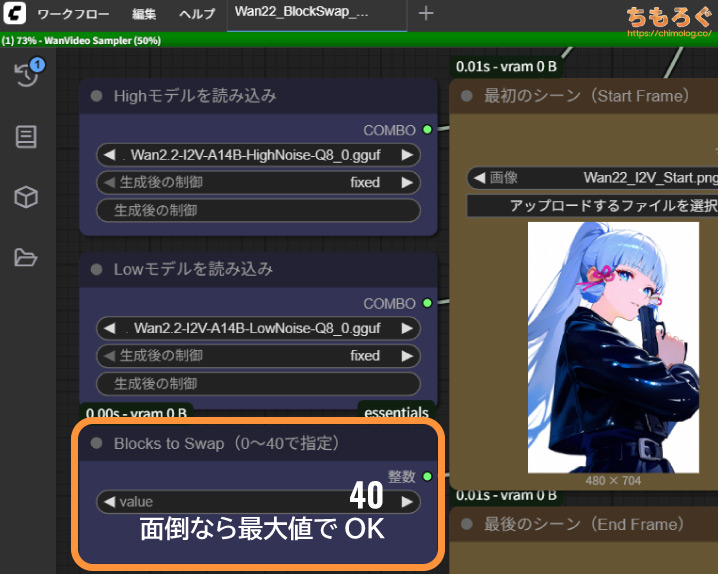
最適化が面倒なら、最大値「40」で大丈夫です。
今回の検証で見てきたとおり、最大値と最適値の性能差なんて、共有メモリに漏れた最悪ケースと比較すれば微々たるものです。
とりあえず40に設定して、共有メモリ漏れをとにかく防いだほうが効率的に生成速度を稼げるし、SSD寿命の無駄な浪費もほとんど防げます。

以上「【Wan2.2】RTX 5070(VRAM:12GB)で動画生成AIを快適に動かす設定」について、検証データと解説でした。
ローカル生成AIにおすすめなグラボ

ローカル版で最高性能の動画生成AI「Wan2.2」モデルにおすすめなグラボ解説です。

2025年現在も定番の「SDXL」モデルにおすすめなグラボ解説です。
RTX 5000搭載のおすすめゲーミングPC【解説】

これからAIイラスト用にパソコンを用意するなら、基本的にBTOパソコンを推奨します。手っ取り早く完成済みかつプロが組み立てたパソコンを入手できます。
すでにパソコンを持っている方は、「グラフィックボードの増設・交換ガイド」を参考に、新しく買ってきたグラボを増設・交換するだけでOKです。












 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選


 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


検証ありがとうございます。
BlocksToSwapの存在は知っていましたが、使い方や効果をここまで細かく検証している日本語記事は大変貴重です。
参考にさせていただきます。
検証ありがとうございます。
逆にこれを使えばRTX5090でネイティブ版の27Bが動かせたりするのでしょうか。