
GeForce RTX 50シリーズ(Blackwell世代)がついに登場。RTX 40シリーズ(Ada Lovelace世代)から約2年半ぶりの後継モデルです。
すでに正式リリースされた「RTX 5090」「RTX 5080」「RTX 5070 Ti」「RTX 5070」のスペック、性能、そして価格やコスパについて。本記事でわかりやすく解説します。
(公開:2025/1/15 | 更新:2025/2/1)
全部で4つある「RTX 50」シリーズ
これから約21000文字を使ってRTX 50シリーズを解説しますが・・・「長いよ!! 読んでられない。」という人向けに、「結論まとめ」から始めます。
RTX 50シリーズの発売日と価格は?
| SKU (型番) | 発売日 (予想) | MSRP (国内想定価格) |
|---|---|---|
| RTX 5090 | 2025年1月30日 | 1999ドル (国内は約45万円~) |
| RTX 5080 | 2025年1月30日 | 999ドル (国内は約20万円~) |
| RTX 5070 Ti | 2025年2月頃 | 749ドル (国内は約15万円~) |
| RTX 5070 | 2025年2月頃 | 549ドル (国内は約11万円~) |
最上位モデル「RTX 5090」のMSRPが1999ドル、日本国内の想定価格は約45万円(税込)から。
2番目のグレード「RTX 5080」はMSRPが999ドル、日本国内で約20万円(税込)から。「RTX 5090」と「RTX 5080」の発売日は2025年1月30日(23:00)です。
一般向けハイエンドモデルに位置づけられる「RTX 5070 Ti」「RTX 5070」はそれぞれ749ドルと549ドルで、日本国内の想定価格がそれぞれ約15万円と約11万円(税込)です。
具体的な発売日がまだ発表されておらず、過去のケースから2025年2月頃になると予想されます。
なお、従来世代(RTX 40)と違い今回(RTX 50)は過去モデルとの併売をしない方針です。すでに生産ラインをRTX 50向けに切り替えており、RTX 40は在庫がなくなり次第終息します。
NVIDIAが発表する希望小売価格「MSRP」には、各国の商習慣や税金を含まない理論値です。
日本国内の場合、MSRPに対して為替レート(ドル円)や為替手数料のほか、消費税(10%)も含まれます。さらに小売店や代理店の利益となるマージンも入るので、MSRPとの乖離が拡大する傾向です。
実際に計算してみましょう。
- MSRP:1999ドル
- 送料:49ドル
- ドル円:150~160円
- 為替手数料:3.85%
- 消費税:10%
1999ドルが約35.1~37.4万円に跳ね上がります。差額の7~10万円が小売店と代理店の取り分です。
・・・差額が高すぎると思いませんか?
実は、RTX 5000シリーズのMSRPを遵守するメーカーがほとんどいません。RTX 5090やRTX 5080の場合、MSRPに200~1000ドルも追加された価格になり、NVIDIAが示したMSRPを大幅に上回ります。
RTX 50シリーズのスペック(仕様)は?
| スペック | CUDAコア | 処理性能 (TFLOPS) | VRAM |
|---|---|---|---|
| RTX 5090 | 21760 (16384) | 104.8 (82.6) | GDDR7:32 GB (GDDR6X:24 GB) |
| RTX 5080 | 10752 (9728) | 56.3 (48.7) | GDDR7:16 GB (GDDR6X:16 GB) |
| RTX 5070 Ti | 8960 (7680) | 44.4 (40.1) | GDDR7:16 GB (GDDR6X:12 GB) |
| RTX 5070 | 6144 (5888) | 30.8 (29.2) | GDDR7:12 GB (GDDR6X:12 GB) |
RTX 50シリーズとRTX 40シリーズの重要スペックをまとめました。( )内が従来モデルRTX 40シリーズの数値です。
最上位モデル「RTX 5090」を除いて、ほぼすべてのRTX 50シリーズでCUDAコア数が約4~17%の微増にとどまります。コア数から計算できる処理性能も伸びが悪く、せいぜい約6~15%程度です。
一方で、VRAMは全モデルでGDDR6X規格から最新のGDDR7規格に更新されます。VRAM速度が約3割も高速化され、性能が伸びづらかったWQHD~4Kゲーミング性能で性能アップを期待できます。
同じランク同士なら、おおむね性能アップです。RTX 5070がRTX 4070に負けたり、RTX 5080がRTX 4080に負ける可能性はほとんど無いでしょう。
各ランクごとに1段階ずつ性能が上がるイメージで、RTX 5090のみ過去最強の性能に達する見込みです。
RTX 50シリーズの性能とコスパは?
| スペック | 処理性能 | 性能アップ | コスパ |
|---|---|---|---|
| RTX 5090 ($ 1999) | 104.8 TFLOPS | +27 % | +2 % |
| RTX 4090 ($ 1599) | 82.6 TFLOPS | ||
| RTX 5080 ($ 999) | 56.3 TFLOPS | +15 % | +39 % |
| RTX 4080 ($ 1199) | 48.7 TFLOPS | ||
| RTX 5070 Ti ($ 749) | 44.4 TFLOPS | +11 % | +18 % |
| RTX 4070 Ti ($799) | 40.1 TFLOPS | ||
| RTX 5070 ($ 549) | 30.8 TFLOPS | +11 % | +15 % |
| RTX 4070 ($ 599) | 29.2 TFLOPS |
搭載CUDAコア数とクロック周波数から処理性能(FP32)を計算して、価格に対するコストパフォーマンスをまとめました。
RTX 50シリーズは全体的に性能の伸びが地味ですが、(RTX 5090を除き)価格設定が50~200ドルも値下げされ、特にRTX 5080のコスパが大きく改善する予定です。
・・・ただし、日本国内はRTX 40発売当時よりドル円が大幅に円安に振れてしまっている影響で、せっかくの値下げを為替レートで打ち消してしまいます。
北米市場ならコスパが改善、日本市場はコスパが大差ないか、むしろ悪化する可能性がやや高いです。
なお、上記の性能はあくまでも処理性能(FP32)に基づいた理論値であり、実際のゲーミング性能はさらに上がる可能性もあります。
全モデルでVRAM帯域幅(速度)がおよそ3割も改善した影響があり、WQHD~4Kゲーミングで予想以上に高い性能アップをもたらすかもしれません。
NVIDIAの製品発表によると、RTX 5070はRTX 4090に相当する性能を持ちながら、わずか549ドル(RTX 4090より7割も安い)と発表しました。
非常にキャッチーで一般ウケのいい発表でしたが、残念ながら誤解を招く可能性が高い表記です。

さきほどのスペック比較を見てのとおり、RTX 5070の処理性能はせいぜい「30.8 TFLOPS」で、RTX 4090の「82.6 TFLOPS」に遠く及ばないです。
しかもVRAM容量が2倍も違ううえ、VRAMの速度も3割足りてません。どう見てもRTX 4090に相当する性能を出せるはずがないわけですが、実は注釈で小さく条件が記載されています。
- DLSS 4(MFG)モード使用時にRTX 4090と並ぶ
要するに、RTX 50シリーズ限定で使える最新のフレーム生成機能「MFG(マルチフレーム生成)」を使えば、フレームレートが4倍以上に跳ね上がってRTX 4090に相当する・・・。
と言っているだけで、MFGを使わず普通にゲームを動かすだけならRTX 5070がRTX 4090に並ぶ可能性は皆無といっていいです。
RTX 50シリーズの技術的な進化は?
RTX 30 → RTX 40と同じく、RTX 50シリーズもカタログスペック面の進化がやや弱いです。一方で、ソフトウェア面での技術的な進化がいろいろと盛り込まれます。
- 「DLSS 4 MFG」でフレームレートが4倍?
- AIで性能アップ「ニューラルレンダリング」
- 「DLSS Override」で非対応ゲームをDLSS化
- ドライバ側でフレーム生成「Smooth Motion」
- 「FP4」対応でAI性能は最大3400 TOPSに
- コンシューマ向けで初のトリプルエンコーダー
- 帯域幅80 Gbps「Display Port 2.1」ポート
- 高速化 & 大容量化する「GDDR7」メモリ
- 製造プロセスはおそらく微細化していない
興味があるところは、↑それぞれの解説を読んでみてください。
RTX 50シリーズのスペックまとめ
| GPU | RTX 5090 | RTX 4090 | RTX 5080 | RTX 4080 | RTX 5070 Ti | RTX 4070 Ti | RTX 5070 | RTX 4070 |
|---|---|---|---|---|---|---|---|---|
| CUDAコア数 | 21760 | 16384 | 10752 | 9728 | 8960 | 7680 | 6144 | 5888 |
| RTコア数レイトレ用の特化コア | 170 | 128 | 84 | 76 | 70 | 60 | 48 | 46 |
| ブーストクロック | 2407 MHz | 2520 MHz | 2617 MHz | 2505 MHz | 2475 MHz | 2610 MHz | 2510 MHz | 2475 MHz |
| VRAM | GDDR7 32 GB | GDDR6X 24 GB | GDDR7 16 GB | GDDR6X 16 GB | GDDR7 16 GB | GDDR6X 12 GB | GDDR7 12 GB | GDDR6X 12 GB |
| 理論性能(FP32) | 104.8 TFLOPS | 82.58 TFLOPS | 56.28 TFLOPS | 48.74 TFLOPS | 44.35 TFLOPS | 40.09 TFLOPS | 30.84 TFLOPS | 29.15 TFLOPS |
| エンコード | x 3第9世代 | x 2第8世代 | x 2第9世代 | x 2第8世代 | x 2第9世代 | x 2第8世代 | x 1第9世代 | x 1第8世代 |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 575 W | 450 W | 360 W | 320 W | 300 W | 285 W | 250 W | 200 W |
| MSRP | $ 1999 | $ 1599 | $ 999 | $ 1199 | $ 749 | $ 799 | $ 549 | $ 549 |
| 発売価格 | 452800 円 | 289300 円 | 199800 円 | 219800 円 | 148800 円 | 149000 円 | 108800 円 | 99800 円 |
| GPU | RTX 5090 | RTX 4090 | RTX 5080 | RTX 4080 | RTX 5070 Ti | RTX 4070 Ti | RTX 5070 | RTX 4070 |
|---|---|---|---|---|---|---|---|---|
| 世代 | Blackwell | Ada Lovelace | Blackwell | Ada Lovelace | Blackwell | Ada Lovelace | Blackwell | Ada Lovelace |
| プロセス | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC | 5 nm製造 : TSMC |
| トランジスタ数 | 922 億 | 763 億 | 456 億 | 459 億 | 456 億 | 358 億 | 311 億 | 358.0 億 |
| ダイサイズ | 750 mm2 | 608 mm2 | 378 mm2 | 379 mm2 | 378 mm2 | 294 mm2 | 263 mm2 | 294 mm2 |
| シェーダー数CPUのコア数に相当 | 21760 | 16384 | 10752 | 9728 | 8960 | 7680 | 6144 | 5888 |
| TMU数Texture Mapping Unitのこと | 680 | 512 | 336 | 304 | 280 | 240 | 192 | 184 |
| ROP数Render Output Unitのこと | 192 | 176 | 128 | 112 | 128 | 80 | 64 | 64 |
| 演算ユニット数 | 170 | 128 | 84 | 76 | 70 | 60 | 48 | 46 |
| Tensorコア数機械学習向けの特化コア | 680 | 512 | 337 | 304 | 280 | 240 | 192 | 184 |
| RTコア数レイトレ用の特化コア | 170 | 128 | 84 | 76 | 70 | 60 | 48 | 46 |
| L1キャッシュ演算ユニットあたり | 128 KB | 128 KB | 128 KB | 128 KB | 128 KB | 128 KB | 128 KB | 128 KB |
| L2キャッシュコア全体で共有 | 88.0 MB | 72.0 MB | 64.0 MB | 64.0 MB | 64.0 MB | 48.0 MB | 40.0 MB | 36.0 MB |
| L3キャッシュコア全体で共有 | – | – | – | – | – | – | – | – |
| クロック周波数 | 2017 MHz | 2235 MHz | 2295 MHz | 2205 MHz | 2300 MHz | 2310 MHz | 2165 MHz | 1920 MHz |
| ブーストクロック | 2407 MHz | 2520 MHz | 2617 MHz | 2505 MHz | 2475 MHz | 2610 MHz | 2510 MHz | 2475 MHz |
| VRAM | GDDR7 32 GB | GDDR6X 24 GB | GDDR7 16 GB | GDDR6X 16 GB | GDDR7 16 GB | GDDR6X 12 GB | GDDR7 12 GB | GDDR6X 12 GB |
| VRAMバス | 512 bit | 384 bit | 256 bit | 256 bit | 256 bit | 192 bit | 192 bit | 192 bit |
| VRAM帯域幅 | 1787.1 GB/s | 1008 GB/s | 960.0 GB/s | 716.8 GB/s | 896.3 GB/s | 504.2 GB/s | 672.2 GB/s | 504.2 GB/s |
| 理論性能(FP32) | 104.8 TFLOPS | 82.58 TFLOPS | 56.28 TFLOPS | 48.74 TFLOPS | 44.35 TFLOPS | 40.09 TFLOPS | 30.84 TFLOPS | 29.15 TFLOPS |
| SLI対応 | – | – | – | – | – | – | – | – |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 575 W | 450 W | 360 W | 320 W | 300 W | 285 W | 250 W | 200 W |
| 補助電源 | 16-pin | 16-pin | 16-pin | 16-pin | 16-pin | 16-pin | 16-pin | 16-pin |
| MSRP | $ 1999 | $ 1599 | $ 999 | $ 1199 | $ 749 | $ 799 | $ 549 | $ 549 |
| 参考価格 | 389800 円 | 298000 円 | 198800 円 | 179800 円 | 148800 円 | 113800 円 | 108800 円 | 86800 円 |
| 発売価格 | 452800 円 | 289300 円 | 199800 円 | 219800 円 | 148800 円 | 149000 円 | 108800 円 | 99800 円 |
| 発売 | 2025/1/30 | 2022/10/12 | 2025/1/30 | 2022/11/16 | – | 2023/1/5 | – | 2023/4/13 |
2025年1月時点、NVIDIAから正式アナウンスされているRTX 50シリーズは以上4つです。
RTX 50シリーズは従来世代と同じTSMC 4N(5 nm)プロセスを使って製造されるため、チップ面積あたりに実装できるトランジスタ数がほとんど変わってません。
よって、RTX 5090以外の下位モデルではスペックの伸びが地味です。チップを大きくしてスペックを向上しようとしたら価格を維持できず、結果的にスペックを抑えざるを得ないわけです。
幸い、VRAMの規格がGDDR6XからGDDR7へ更新され、VRAM帯域幅が約3割も向上します。チップ自体の改善よりVRAMの規格更新の方が性能アップに貢献する予感がしています。
たとえば「VRChat」や「タルコフ」など、VRAMを異様に酷使するタイプのゲームなら、スペック以上の性能アップが見られるはずです。
RTX 5090(RTX 4090の約1.3倍)
【唯一無二】性能1.3倍、価格も1.3倍

| GPU | RTX 5090 | RTX 4090 |
|---|---|---|
| CUDAコア数 | 21760 | 16384 |
| RTコア数レイトレ演算用 | 170 | 128 |
| ブーストクロック | 2407 MHz | 2520 MHz |
| VRAM | GDDR7 32 GB | GDDR6X 24 GB |
| 理論性能(FP32) | 104.8 TFLOPS | 82.58 TFLOPS |
| エンコード | x 3第9世代 | x 2第8世代 |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 575 W | 450 W |
| MSRP | $ 1999 | $ 1599 |
| 発売価格 | 452800 円 | 289300 円 |
| 発売 | 2025/1/30 | 2022/10/12 |
| GPU | RTX 5090 | RTX 4090 |
|---|---|---|
| 世代 | Blackwell | Ada Lovelace |
| プロセス | 5 nm製造 : TSMC | 5 nm製造 : TSMC |
| トランジスタ数 | 922.0 億 | 763.0 億 |
| ダイサイズ | 750 mm2 | 608 mm2 |
| シェーダー数CPUのコア数に相当 | 21760 | 16384 |
| TMU数Texture Mapping Unitのこと | 680 | 512 |
| ROP数Render Output Unitのこと | 192 | 176 |
| 演算ユニット数 | 170 | 128 |
| Tensorコア数機械学習向けの特化コア | 680 | 512 |
| RTコア数レイトレ用の特化コア | 170 | 128 |
| L1キャッシュ演算ユニットあたり | 128 KB | 128 KB |
| L2キャッシュコア全体で共有 | 88.0 MB | 72.0 MB |
| L3キャッシュコア全体で共有 | – | – |
| クロック周波数 | 2017 MHz | 2235 MHz |
| ブーストクロック | 2407 MHz | 2520 MHz |
| VRAM | GDDR7 32 GB | GDDR6X 24 GB |
| VRAMバス | 512 bit | 384 bit |
| VRAM帯域幅 | 1787.1 GB/s | 1008 GB/s |
| 理論性能(FP32) | 104.8 TFLOPS | 82.58 TFLOPS |
| SLI対応 | – | – |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 575 W | 450 W |
| 補助電源 | 16-pin | 16-pin |
| MSRP | $ 1999 | $ 1599 |
| 参考価格 | 389800 円 | 298000 円 |
| 発売価格 | 452800 円 | 289300 円 |
| 発売 | 2025/1/30 | 2022/10/12 |
「RTX 5090」はRTX 50シリーズのエンスージアスト向けを謳う、いわゆるフラグシップモデルです。
かつて「TITAN」と呼ばれていた、業務向けとコンシューマ向けの中間モデルの後継に位置づけられます。一般向けじゃない圧倒的なスペックを誇り、価格設定も1999ドルと過去最高。
従来世代(RTX 4090)から500ドルも価格が上がったためコスパが悪化したように見えて、実は意外とコスパが変わっていないのが特徴です。
- CUDAコア数:1.33倍(16384 → 21760)
- VRAM容量:1.33倍(24 → 32 GB)
- VRAM帯域幅:1.77倍(1.01 → 1.79 TB/s)
- 処理性能(FP32):1.27倍(82.6 → 104.8 TFLOPS)
値上がり幅25%以上のスペックアップです。
特にVRAM容量と帯域幅が大きく伸びていて、高解像度ゲーミング(WQHD~4K)やAI生成性能で、価格差以上の性能アップを見込めます。
加えて、RTX 5090に競合するグラフィックボードが他にない状況です。他社で代替できない唯一無二の性能と考えれば、高い価格もある程度は正当化されてしまいます。
4K 240 Hzゲーミングモニターを使うようなハイエンドゲーマーだけでなく、個人でAI生成を使った開発や業務を行っているコアなユーザーからも人気が殺到する可能性が高いです。
RTX 5080(RTX 4080の約1.2倍)
【汚名返上なるか】性能1.2倍、価格は2割引

| GPU | RTX 5080 | RTX 4080 |
|---|---|---|
| CUDAコア数 | 10752 | 9728 |
| RTコア数レイトレ演算用 | 84 | 76 |
| ブーストクロック | 2617 MHz | 2505 MHz |
| VRAM | GDDR7 16 GB | GDDR6X 16 GB |
| 理論性能(FP32) | 56.28 TFLOPS | 48.74 TFLOPS |
| エンコード | x 2第9世代 | x 2第8世代 |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 360 W | 320 W |
| MSRP | $ 999 | $ 1199 |
| 発売価格 | 199800 円 | 219800 円 |
| 発売 | 2025/1/30 | 2022/11/16 |
| GPU | RTX 5080 | RTX 4080 |
|---|---|---|
| 世代 | Blackwell | Ada Lovelace |
| プロセス | 5 nm製造 : TSMC | 5 nm製造 : TSMC |
| トランジスタ数 | 456.0 億 | 459.0 億 |
| ダイサイズ | 378 mm2 | 379 mm2 |
| シェーダー数CPUのコア数に相当 | 10752 | 9728 |
| TMU数Texture Mapping Unitのこと | 336 | 304 |
| ROP数Render Output Unitのこと | 128 | 112 |
| 演算ユニット数 | 84 | 76 |
| Tensorコア数機械学習向けの特化コア | 337 | 304 |
| RTコア数レイトレ用の特化コア | 84 | 76 |
| L1キャッシュ演算ユニットあたり | 128 KB | 128 KB |
| L2キャッシュコア全体で共有 | 64.0 MB | 64.0 MB |
| L3キャッシュコア全体で共有 | – | – |
| クロック周波数 | 2295 MHz | 2205 MHz |
| ブーストクロック | 2617 MHz | 2505 MHz |
| VRAM | GDDR7 16 GB | GDDR6X 16 GB |
| VRAMバス | 256 bit | 256 bit |
| VRAM帯域幅 | 960.0 GB/s | 716.8 GB/s |
| 理論性能(FP32) | 56.28 TFLOPS | 48.74 TFLOPS |
| SLI対応 | – | – |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 360 W | 320 W |
| 補助電源 | 16-pin | 16-pin |
| MSRP | $ 999 | $ 1199 |
| 参考価格 | 198800 円 | 179800 円 |
| 発売価格 | 199800 円 | 219800 円 |
| 発売 | 2025/1/30 | 2022/11/16 |
「RTX 5080」はゲーマー向けの最上位モデルに位置づけられます。
RTX 5090がゲーマー以外からの需要も見込む旗艦モデルなら、RTX 5080は明確にゲーマー向けです。スペックや価格差からもRTX 5090と明確に差別化されているのが明らかです。
従来世代(RTX 4080)の反省を活かし、今作RTX 5080のMSRPを1199ドルから200ドル値引きして、999ドルに設定しています。
- CUDAコア数:1.11倍(9728 → 10752)
- VRAM容量:1.00倍(16 → 16 GB)
- VRAM帯域幅:1.34倍(717 → 960 GB/s)
- 処理性能(FP32):1.15倍(48.7 → 56.3 TFLOPS)
200ドルの値下げに対して、スペックの伸び幅が最高です(※RTX 5090を除く)。
ほぼ2割引しながら処理性能は2割アップと計算され、コストパフォーマンスの改善が大きいです。最初からお買い得感のあるグラフィックボードに仕上げてきた様子。
・・・よっぽどRTX 4080の評判が悪かったと読めます。
ただし、せっかく200ドル値引きしてもらっても生憎の円安で、国内販売価格はおそらくRTX 4080発売時と大差ない可能性あり。
RTX 5070 Ti(RTX 4070 Tiの約1.1倍)
【売れ筋の予感】性能1.1倍、価格は6%引き

| GPU | RTX 5070 Ti | RTX 4070 Ti |
|---|---|---|
| CUDAコア数 | 8960 | 7680 |
| RTコア数レイトレ演算用 | 70 | 60 |
| ブーストクロック | 2475 MHz | 2610 MHz |
| VRAM | GDDR7 16 GB | GDDR6X 12 GB |
| 理論性能(FP32) | 44.35 TFLOPS | 40.09 TFLOPS |
| エンコード | x 2第9世代 | x 2第8世代 |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 300 W | 285 W |
| MSRP | $ 749 | $ 799 |
| 発売価格 | 148800 円 | 149000 円 |
| 発売 | 2025/2ごろ | 2023/1/5 |
| GPU | RTX 5070 Ti | RTX 4070 Ti |
|---|---|---|
| 世代 | Blackwell | Ada Lovelace |
| プロセス | 5 nm製造 : TSMC | 5 nm製造 : TSMC |
| トランジスタ数 | 456.0 億 | 358.0 億 |
| ダイサイズ | 378 mm2 | 294 mm2 |
| シェーダー数CPUのコア数に相当 | 8960 | 7680 |
| TMU数Texture Mapping Unitのこと | 280 | 240 |
| ROP数Render Output Unitのこと | 128 | 80 |
| 演算ユニット数 | 70 | 60 |
| Tensorコア数機械学習向けの特化コア | 280 | 240 |
| RTコア数レイトレ用の特化コア | 70 | 60 |
| L1キャッシュ演算ユニットあたり | 128 KB | 128 KB |
| L2キャッシュコア全体で共有 | 64.0 MB | 48.0 MB |
| L3キャッシュコア全体で共有 | – | – |
| クロック周波数 | 2300 MHz | 2310 MHz |
| ブーストクロック | 2475 MHz | 2610 MHz |
| VRAM | GDDR7 16 GB | GDDR6X 12 GB |
| VRAMバス | 256 bit | 192 bit |
| VRAM帯域幅 | 896.3 GB/s | 504.2 GB/s |
| 理論性能(FP32) | 44.35 TFLOPS | 40.09 TFLOPS |
| SLI対応 | – | – |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 300 W | 285 W |
| 補助電源 | 16-pin | 16-pin |
| MSRP | $ 749 | $ 799 |
| 参考価格 | 148800 円 | 113800 円 |
| 発売価格 | 148800 円 | 149000 円 |
| 発売 | 2025/2ごろ | 2023/1/5 |
「RTX 5070 Ti」は型番的にミドルクラスに位置づけられますが、約15万円近い価格を考えればミドルクラスと呼ぶのは無理があります。どう見てもハイエンドモデルです。
決して安くない価格ですが、それでも従来世代(RTX 4070 Ti)から50ドル値引きされ、VRAM性能が大幅に向上します。
- CUDAコア数:1.17倍(7680 → 8960)
- VRAM容量:1.33倍(12 → 16 GB)
- VRAM帯域幅:1.78倍(504 → 896 GB/s)
- 処理性能(FP32):1.11倍(40.1 → 44.4 TFLOPS)
スペックから計算される処理性能の伸び自体は約1.1倍程度で正直かなりしょっぱい印象を受けますが、よく見るとVRAM性能の伸びが凄まじいです。
VRAM容量は16 GBに増量(+33%)され、帯域幅はなんと約900 GB/s(+78%)と完全に別物に進化しています。
約900 GB/sの帯域幅といえば、RTX 5080(960 GB/s)やRTX 4090(1008 GB/s)に迫るレベルの帯域幅にあたり、コスパ的に美味しい雰囲気が漂っています。
実際のゲームプレイでスペック以上にフレームレートが伸びる可能性が、おそらくRTX 50シリーズでもっとも高いグラボです。
たとえば「VRChat」「タルコフ」「Call of Duty」など、VRAM依存度が高いゲームタイトルで従来比で1.1倍を超える性能アップに期待できます。
RTX 5070(RTX 4070の約1.1倍)
【予算10万で存在感】性能1.1倍、価格は1割引

| GPU | RTX 5070 | RTX 4070 |
|---|---|---|
| CUDAコア数 | 6144 | 5888 |
| RTコア数レイトレ演算用 | 48 | 46 |
| ブーストクロック | 2510 MHz | 2475 MHz |
| VRAM | GDDR7 12 GB | GDDR6X 12 GB |
| 理論性能(FP32) | 30.84 TFLOPS | 29.15 TFLOPS |
| エンコード | x1第9世代 | x1第8世代 |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 250 W | 200 W |
| MSRP | $ 549 | $ 599 |
| 発売価格 | 108800 円 | 99800 円 |
| 発売 | 2025/2ごろ | 2023/4/13 |
| GPU | RTX 5070 | RTX 4070 |
|---|---|---|
| 世代 | Blackwell | Ada Lovelace |
| プロセス | 5 nm製造 : TSMC | 5 nm製造 : TSMC |
| トランジスタ数 | 311.0 億 | 358.0 億 |
| ダイサイズ | 263 mm2 | 294 mm2 |
| シェーダー数CPUのコア数に相当 | 6144 | 5888 |
| TMU数Texture Mapping Unitのこと | 192 | 184 |
| ROP数Render Output Unitのこと | 64 | 64 |
| 演算ユニット数 | 48 | 46 |
| Tensorコア数機械学習向けの特化コア | 192 | 184 |
| RTコア数レイトレ用の特化コア | 48 | 46 |
| L1キャッシュ演算ユニットあたり | 128 KB | 128 KB |
| L2キャッシュコア全体で共有 | 40.0 MB | 36.0 MB |
| L3キャッシュコア全体で共有 | – | – |
| クロック周波数 | 2165 MHz | 1920 MHz |
| ブーストクロック | 2510 MHz | 2475 MHz |
| VRAM | GDDR7 12 GB | GDDR6X 12 GB |
| VRAMバス | 192 bit | 192 bit |
| VRAM帯域幅 | 672.2 GB/s | 504.2 GB/s |
| 理論性能(FP32) | 30.84 TFLOPS | 29.15 TFLOPS |
| SLI対応 | – | – |
| PCIe | PCIe 5.0 x16 | PCIe 4.0 x16 |
| TDP | 250 W | 200 W |
| 補助電源 | 16-pin | 16-pin |
| MSRP | $ 549 | $ 599 |
| 参考価格 | 108800 円 | 86800 円 |
| 発売価格 | 108800 円 | 99800 円 |
| 発売 | 2025/2ごろ | 2023/4/13 |
「RTX 5070」も、RTX 5070 Tiと同様にミドルクラス型番ですが、想定で11万円近い価格をミドルクラスと捉えるのがやはり無理があるでしょう。価格的にほぼハイエンドモデルです。
NVIDIAが発表会で大々的に「RTX 5070はRTX 4090相当の性能」などと盛大にフカシていますが、大げさなアピールをする製品に限って・・・もっとも地味なアップグレードでした。
- CUDAコア数:1.04倍(5888 → 6144)
- VRAM容量:1.00倍(12 → 12 GB)
- VRAM帯域幅:1.33倍(504 → 672 GB/s)
- 処理性能(FP32):1.06倍(29.2 → 30.8 TFLOPS)
スペックから計算できる処理性能はたった6%しか伸びず、VRAMの容量は12 GBのまま据え置き。VRAMの帯域幅は約1.3倍に伸びますが、約1.8倍も伸びたRTX 5070 Tiと比較すると大きく見劣りします。
従来世代(RTX 4070)からの伸びが乏しいため、価格を50ドル値引き(約1割引)してコストパフォーマンス路線を強く主張する狙いです。
もちろん、RTX 4090に相当する性能を出せるスペックに到底届いていないから、基本的に「DLSS 4 MFG(マルチフレーム生成)」機能が前提のグラボです。
フレーム生成を使わず、そのままゲームを動かせば良いところRTX 4070 Tiを超える程度の性能しか期待できません。
それでもRTX 2000~3000番台から乗り換えるのにちょうどいいポジションになる可能性を否定できず、乗り換え需要で人気になってしまうグラボでしょう。
「予算10万円で買える中で最高のグラボ」と呼ばれる、従来世代と同じ立ち位置をRTX 5070が確保するはずです。
RTX 5070 Ti以上にライバルがほとんど存在しない悲惨な状況ですが、RTX 5070に限っては「Radeon RX 9070 XT」が強力なライバルになる予定です。
なお、肝心の具体的なスペックをAMDが何も開示していません。型番から推測するにRTX 5070を意識しているのが確かなものの、スペックも価格も未だ不明。
すでに、AMDのマーケティングは失敗していると言っても過言じゃないです。
RTX 50シリーズの技術的な進化ポイント
- 「DLSS 4 MFG」でフレームレートが4倍?
- 「DLSS Override」で非対応ゲームをDLSS化
- ドライバ側でフレーム生成「Smooth Motion」
- AIで性能アップ「ニューラルレンダリング」
- 「FP4」対応でAI性能は最大3400 TOPSに
- コンシューマ向けで初のトリプルエンコーダー
- 帯域幅80 Gbps「Display Port 2.1」ポート
- 高速化 & 大容量化する「GDDR7」メモリ
- 製造プロセスはおそらく微細化していない
RTX 50シリーズの技術的な進化ポイントざっくり6点あります。順番に解説します。
「DLSS 4」による「マルチフレーム生成」機能
| 対応状況 | RTX 50 | RTX 40 | RTX 30 | RTX 20 |
|---|---|---|---|---|
| 【DLSS 4】 マルチフレーム生成 | 対応 | なし | ||
| 【DLSS 4】 フレーム生成 | 対応 | なし | ||
| 【DLSS 4】 レイ再構築 | 対応 | |||
| 【DLSS 4】 超解像 | 対応 | |||
| 【DLSS 4】 DLAA | 対応 | |||
GeForce RTXシリーズが対応する、AIによるアップスケーリング機能「DLSS」が最新バージョン「DLSS 4」に更新されます。
「DLSS 2」以来、過去最大級の機能更新アップグレードになり、その中にRTX 50シリーズ限定で使える「MFG(マルチフレーム生成)」機能が含まれます。
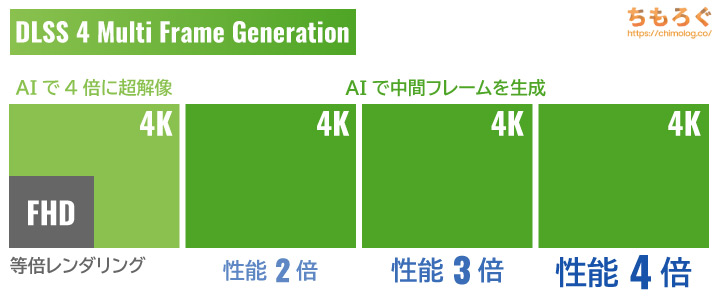
マルチフレーム生成は、AIによる超解像(アップスケーリング)と、AIによるフレーム生成のさらなる進化モデルです。
従来のフレーム生成機能だと中間フレームを1枚しか生成できなかったのが、最新のマルチフレーム生成機能では中間フレームを3枚に増やします。
たとえば、レイトレーシング最高画質の4Kゲーミングを考えてみます。
- 忠実に4Kレンダリング:平均10 fps(等倍)
- フルHDからDLSS超解像:平均40 fps(4倍)
- フレーム生成で1枚追加:平均80 fps(8倍)
- マルチフレーム生成で3枚追加:平均160 fps(16倍)
NVIDIAが派手にアピールする4倍以上の性能が何を意味するか、そのカラクリが理解できたはずです。
最新モデルのマルチフレーム生成を使えば、忠実にレンダリングする場合と比較して、理論値で16倍のフレームレートまで底上げできます。
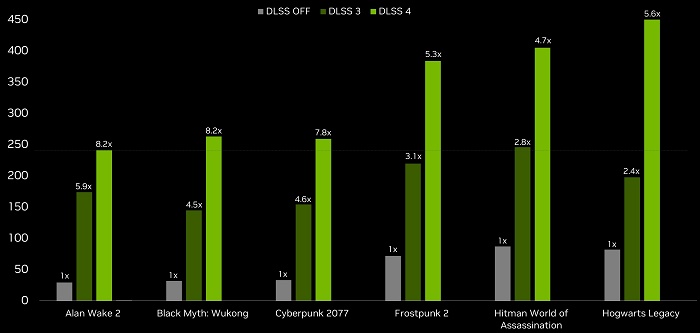
なお、16倍の性能はあくまでも理論値で、NVIDIAによる実測値だと約5倍~8倍の性能アップでした。
中間フレームを3枚も生成して映像が破綻しないのか、入力遅延が増大してゲーム体験を逆に損なってしまう危険性は無いのか?
- 映像の破綻:最新モデル「DLSS 4」では生成品質が向上し、破綻の発生率を抑制
- 入力遅延:最新モデル「DLSS 4」自体の処理速度が速いうえに、遅延カット機能「Reflex 2」でさらに短縮
要するに、今回のアップデートで実装される「DLSS 4」モデル自体がなかなかに高性能だから、実用上の問題はないはず・・・とNVIDIAは主張します。
| 【DLSS 4】 対応ゲームタイトル(75個) | ||
|---|---|---|
| A Quiet Place: The Road Ahead | God of War Ragnarök | Ready or Not |
| Akimbot | Gray Zone Warfare | Remnant II |
| Alan Wake 2 | GROUND BRANCH | Satisfactory |
| Aunt Fatima | HITMAN World of Assassination | SCUM |
| Backrooms: Escape Together | Hogwarts Legacy | Senua’s Saga: Hellblade II |
| Bears in Space | ICARUS | SILENT HILL 2 |
| Bellwright | Immortals of Aveum | Skye: The Misty Isle |
| Crown Simulator | Indiana Jones and the Great Circle | Slender: The Arrival |
| Cyberpunk 2077 | Jusant | Squad |
| D5 Render | JX Online 3 | S.T.A.L.K.E.R. 2: Heart of Chornobyl |
| Deceit 2 | Kristala | Star Wars Outlaws |
| Deep Rock Galactic | Layers of Fear | Star Wars Jedi: Survivor |
| Deliver Us Mars | Liminalcore | Starship Troopers: Extermination |
| DESORDRE: A Puzzle Adventure | Lords of the Fallen | Still Wakes The Deep |
| Desynced: Autonomous Colony Simulator | Marvel Rivals | Supermoves |
| Diablo IV | Microsoft Flight Simulator | Test Drive Unlimited Solar Crown |
| Direct Contact | Microsoft Flight Simulator 2024 | The Axis Unseen |
| Dragon Age: The Veilguard | Mortal Online 2 | The Black Pool |
| Dugeonborne | NARAKA: BLADEPOINT | THE FINALS |
| DYNASTY WARRIORS: ORIGINS | Need for Speed Unbound | The First Descendant |
| Enlisted | Once Human | The Thaumaturge |
| Flintlock: The Siege of Dawn | Outpost: Infinity Siege | Torque Drift 2 |
| Fort Solis | Pax Dei | Tribes 3: Rivals |
| Frostpunk 2 | PAYDAY 3 | Witchfire |
| Ghostrunner 2 | QANGA | World of Jade Dynasty |
「DLSS Override」機能で非対応ゲームをDLSS化

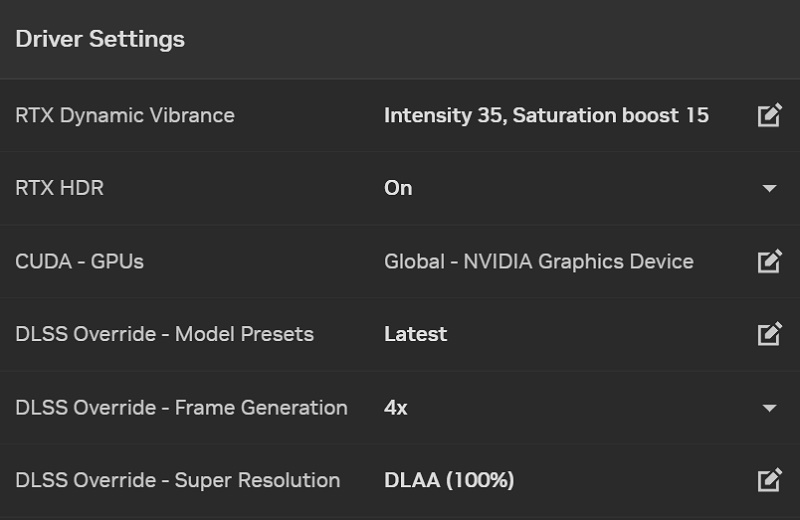
ゲーム側が最新モデル「DLSS 4」に対応していない場合、GeForce専用ユーティリティソフト「NVIDIA App」から強制的にDLSS 4に変更できる新機能「DLSS Override」が実装される予定。
たとえば、DLSS 2.2のまま放置されている「フォートナイト」や、今さらDLSS 2.0が実装された「崩壊スターレイル」など。
旧世代の古いDLSSモデルを使っているゲームに対して、Transformer SRモデルを内蔵する最新の「DLSS 4」に書き換えが可能になる・・・らしいです。
- Model Presets:適用するDLSSモデル
- Frame Generation:フレーム生成の設定
- Super Resolution:アップスケーリング設定
3つの項目でDLSSの設定を上書きします。
Model Presetsで適用するDLSSモデル(DLSS 4など)を選び、Super Resolutionからアップスケーリング品質を選びます。現時点では、ウルトラパフォーマンス、またはDLAAモードを適用できる予定。
Frame Ganerationは対応するグラフィックボード限定の機能です。「フレーム生成(DLSS FG)」はRTX 40シリーズ以降、「マルチフレーム生成(DLSS MFG)」はRTX 50シリーズ以降に限られます。
残念ながら、ドライバ側から強制的に適用するライバルの機能「AMD FSR」や「AFMF 2」ほどの汎用性は提供できない様子です。
ドライバ側でDLSSの設定を強制的に変更するとアンチチートツールが誤作動を引き起こし、アカウントがロックされるリスクがあります。
有名な実例がAMD Radeonで使える「Anti-Lag+」です。Anti-Lag+を適用してFPSゲームをプレイすると、アンチチートが誤作動を起こして、SteamからBANされる事例が相次ぎました。
他には、有志が制作したDLSS上書きツール(.dllファイルの上書き)を使うと、アンチチートが発動してしまう事例もあるそうです。
NVIDIAはこのようなアンチチートの誤作動を引き起こさないよう、ゲーム開発側と密接にやり取り(= 根回し)を行い、事前に問題が起きないよう徹底して対策すると回答しています。
ドライバ側でフレーム生成「Smooth Motion」機能
「Smooth Motion」機能は、RTX 40~50シリーズに内蔵されているTensor Core(AI性能)を活用して、競合する「AFMF 2」より高品質なフレーム生成を可能にする機能です。
現時点でRTX 50シリーズのみ対応ですが、今後のドライバ更新でRTX 40シリーズもSmooth Motionに対応します。
60 fps上限のゲームを120 fps化したり、120 fps上限のゲームを240 fps化するときに便利です。視点を大きく素早く振ったときにも破綻なく機能するかどうかが焦点です。
AI処理でfps向上を狙う「ニューラルレンダリング」技術

RTX 50から対応する「ニューラルレンダリング」は、ものすごく大雑把に例えると、計算をAIで省略して処理性能を高速化する技術です。
身近な例としてAI生成された画像が分かりやすいでしょう。適切な訓練を受けていない人間にとって、AI生成された画像と、人間が描いた画像を見分けるのは意外と難しいです。
人間の視覚は思っている以上に大雑把に映像を捉えていて、画像や映像に多少の誤差やエラーが含まれていても気づかない傾向があります。
つまり、ニューラルレンダリングはいわば「等倍レンダリングのAI生成」です。
RTX 50シリーズが対応するニューラルレンダリングにより、人間の目で見て分からない程度までAI処理でゲーム画面をレンダリングして、VRAM消費量と計算負荷を大きく下げられる技術です。
超解像(DLSS)や中間フレーム挿入(MFG)だけでなく、元となる最初の等倍フレームそのものからAI生成モデルを用いて高速化を狙います。
RTX 50シリーズはニューラルレンダリングを効率よく処理するため、CUDAコア単体でFP32とINT32を動かせるように設計を変更します。3世代ぶりにPascal世代の設計に戻ってきたようです。
「FP4」演算に対応してAI処理性能を大幅アップ
ニューラルレンダリングで説明した「いかに処理を端折るか?」と似た概念が、RTX 50シリーズから対応が始まった「FP4」演算です。
| 演算タイプ | 解像度 | スループット | |
|---|---|---|---|
| FP4 | 4ビット | 16段階 | 4倍 |
| FP8 | 8ビット | 256段階 | 2倍 |
| FP16 | 16ビット | 65536段階 | 1倍 |
RTX 50シリーズのAI処理性能が信じられないほど大幅にアップした理由が「FP4」演算対応です。
RTX 5090を例に計算してみましょう。
- CUDAコア数:1.33倍
- クロック周波数:0.96倍
- FP8 → FP4演算:2.00倍
- 合計:2.54倍
理論上のAI処理性能は約2.54倍と計算でき、RTX 4090の公称値1321 AI TOPSに掛け算すると、RTX 5090の公称値に近い3360 AI TOPS(公称値:3352 AI TOPS)が得られます。
しかし、FP8からFP4へ移行すると演算の解像度が大幅に悪化します。256段階から16段階まで粗くなってしまい、AI生成モデル側がFP4を前提にトレーニングされなければ無意味です。

画像生成モデル「FLUX」など、一部のAIモデルがNVIDIAと提携してFP4対応をアピールしていますが、他の大人気モデルにまでFP4対応が波及するかどうかは不透明。
言語生成モデル(LLM)もFP4に対応(4ビット量子化)させると、入力に対する応答がかなり怪しくなる傾向があるし、今後の技術革新に期待・・・です。
コンシューマ向けGPUで初の「エンコーダー3基」搭載
| GPU | エンコーダー | デコーダー |
|---|---|---|
| RTX 5090 | x 3 第9世代NVENC | x 2 第6世代NVDEC |
| RTX 4090 | x 2 第8世代NVENC | x 1 第5世代NVDEC |
| RTX 5080 | x 2 第9世代NVENC | x 2 第6世代NVDEC |
| RTX 4080 | x 2 第8世代NVENC | x 1 第5世代NVDEC |
| RTX 5070 Ti | x 2 第9世代NVENC | x 1 第6世代NVDEC |
| RTX 4070 Ti | x 2 第8世代NVENC | x 1 第5世代NVDEC |
| RTX 5070 | x 1 第9世代NVENC | x 1 第6世代NVDEC |
| RTX 4070 | x 1 第8世代NVENC | x 1 第5世代NVDEC |
動画エンコード勢に朗報です。
RTX 50シリーズには最新の「第9世代NVENC」エンコーダーと、「第6世代NVDEC」デコーダーが導入されます。
第9世代NVENCエンコーダーにより、HEVC形式とAV1形式の変換品質(VMAFスコア)が約10%向上します。第6世代NVDECデコーダーには4:2:2サポートが導入され、高品質でスムーズな動画編集が可能に。
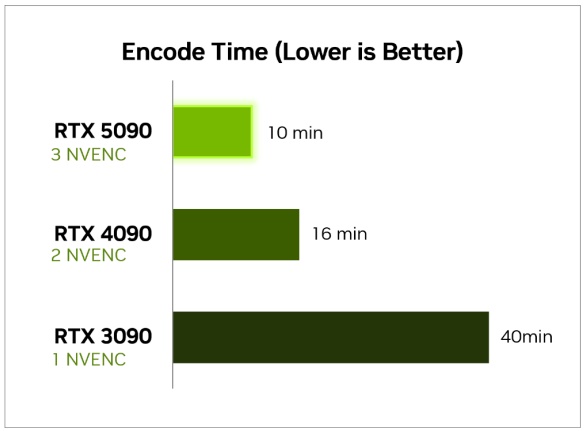
さらに、RTX 5090のみNVENCエンコーダーを「3基」搭載し、スプリット方式エンコードによる変換速度が最大で3倍(RTX 4090比で1.6倍)まで高速化する見込みです。
しかし、4K解像度の重たい素材を読み込ませるとデコードの負荷が大きすぎてエンコード速度がデコード律速になる現象があったため、対策としてNVDECデコーダーが「2基」に増設されました。
より高品質で高速なハードウェアエンコードが可能です。
- MV-HEVC(Multiview HEVC)形式をサポート
- AV1形式に「Ultra High Quality」モードを実装
(現行のP7 = quality以上の品質プリセット?)
帯域幅80 Gbpsに達する「Display Port 2.1」
| GPU | DP規格 | 帯域幅 | 実効レート |
|---|---|---|---|
| GeForce RTX 50 | Display Port 2.1a (UHBR20) | 80 Gbps | 77.37 Gbps |
| GeForce RTX 40 | Display Port 1.4a | 32.4 Gbps | 25.92 Gbps |
| Radeon RX 7000 | Display Port 2.1a (UHBR13.5) | 54 Gbps | 52.22 Gbps |
RTX 50シリーズに「Display Port 2.1(UHBR20)」端子が実装されます。
Radeon RX 7000シリーズの「Display Port 2.1(UHBR13.5)」より帯域幅が約50%も多い、最高グレード「UHBR20」に対応します。
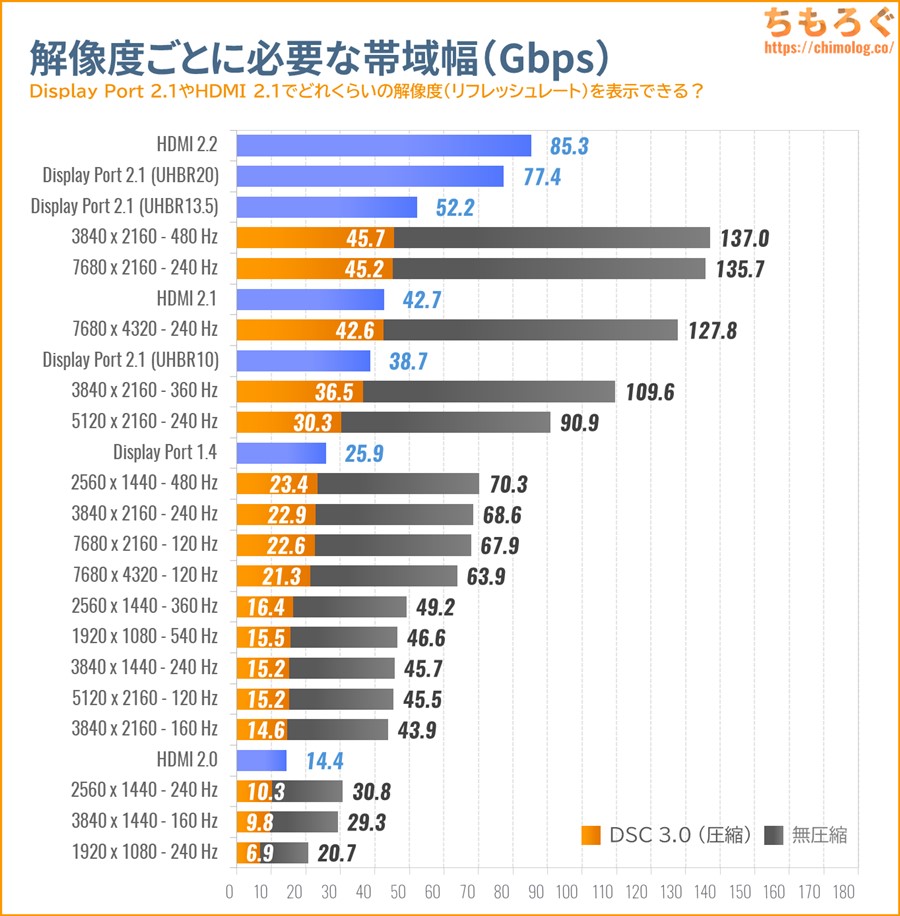
(※クリックでグラフ拡大)
帯域幅が約50 → 80 Gbpsへ大幅に増え、無圧縮で4K 240 HzやWQHD 480 Hzを表示可能です。DSC 3.0(圧縮)モード時なら、4K 480 Hzや8K 240 Hzですら表示できます。
おそらく今後発売されるハイエンドなゲーミングモニターで、「UHBR20」や「80 Gbps」などを宣伝文句に使う製品が増えるはずです。
RTX 50シリーズのDisplay Port 2.1を目当てにしている方は、ゲーミングモニター側もきちんとDisplay Port 2.1(UHBR20)を実装しているか要チェック。
「GDDR7」メモリで速度1.3倍 & 容量1.5倍へ

| VRAM | 転送レート | 記憶密度 |
|---|---|---|
| GDDR7 | 32 Gb/s | 24 Gb 1個あたり3 GB |
| GDDR6X | 24 Gb/s | 16 Gb 1個あたり2 GB |
| GDDR6 | 20 Gb/s | 16 Gb 1個あたり2 GB |
RTX 50シリーズは、Micron 1β世代プロセスで製造される「GDDR7」メモリをVRAMとして搭載します。
転送レートが従来世代のGDDR6Xメモリと比較して約33%向上、2世代前のGDDR6メモリと比較して約60%も向上し、VRAM依存度の高いタスクに対して処理速度が高速化する見込みです。
特にVRChatやタルコフなど、L2~L3キャッシュヒット率が悪く、VRAMの物理帯域幅を異常に浪費するゲームにおいて。
約1.3倍の帯域幅を持つGDDR7が高い効果を発揮するかもしれません。
メモリの記憶密度は1.5倍の最大24 Gbまで拡張され、24 Gb = メモリ1個あたり容量3 GBが可能に。2世代ぶりにようやくメモリ1個あたりの容量が増えます。
しかし、捉え方をクルッと変えるとイヤな予感が・・・ たとえばRTX 5080を例に挙げてみます。
現時点のRTX 5080はVRAM容量が16 GB(8個)です。もし、容量3 GB版を使えば24 GBまで容量を増設できます。同じ理屈で、理論上はRTX 5070の18 GB版だって製造できます。
GDDR7メモリに容量3 GBがある以上、来年(2026年)以降に追加が予想されるRTX 50 SUPERシリーズで、VRAM容量のアップグレードがかなりの確率で想定できます。
引き続き「TSMC 4N」プロセスを採用
最後は技術的な進化ポイントではなく、まったく進化していない部分を紹介して終わります。
| GPU | RTX 5090 | RTX 4090 |
|---|---|---|
| 世代 | Blackwell | Ada Lovelace |
| プロセス | TSMC 4N製造 : TSMC 5 nm | TSMC 4N製造 : TSMC 5 nm |
| トランジスタ数 | 922.0 億 | 763.0 億 |
| ダイサイズ | 750 mm2 | 608 mm2 |
| 密度 | 122.9 MTr/mm2 | 125.5 MTr/mm2 |
台湾TSMC社がNVIDIA向けに、5 nmノードシリーズをベースにカスタムした製造プロセスが「TSMC 4N」です。
従来世代(RTX 40)で使われた「TSMC 4N」と同じく、5 nm EUVマシン(ASML製)で製造される5 nmプロセスに属する製造プロセスです。
ややこしいのでざっくりと、「TSMC 4N = TSMC 5 nm」と捉えておおむね間違いありません。
製造プロセスの技術的進化を端的に示す「トランジスタ密度」に注目しましょう。
- RTX 5090:1億2290万個/mm2
- RTX 4090:1億2550万個/mm2
搭載されているトランジスタ数を、ダイサイズ(チップ面積)で割り算すると、チップ面積1 mm2あたりのトランジスタ数(= トランジスタ密度)を計算できます。
見ての通り、RTX 5090とRTX 4090のトランジスタ密度はほとんど同じで、NVIDIAがホワイトペーパーに記載したとおり従来世代とほぼ同じプロセスだと分かります。
実質5 nm級のまま進歩していない「TSMC 4N」プロセスの流用が、RTX 50シリーズのスペックが全体的に伸びていない主な要因です。
仮にTSMC 3 nmプロセス(約2億個/mm2)へ移行した場合、同じチップ面積のまま、トランジスタ数を約1.6倍の規模にまで拡張可能です。
半導体の理論性能は搭載したトランジスタ数の平方根に比例するから、ハードウェアだけで約1.27倍(1.60^0.5)の性能アップを狙えます。
しかし、RTX 50シリーズは5 nmプロセスを続投しました。
理由はシンプルに製造コストです。TSMC 5 nmがウェハ1枚あたり15000ドル(約225万円)に対して、TSMC 3 nmだとウェハ1枚あたり30000ドル(約450万円)と推定されています。
チップ1枚あたりの製造コストが2倍に跳ね上がってしまい、従来世代と同じMSRP(価格)を維持できないです。
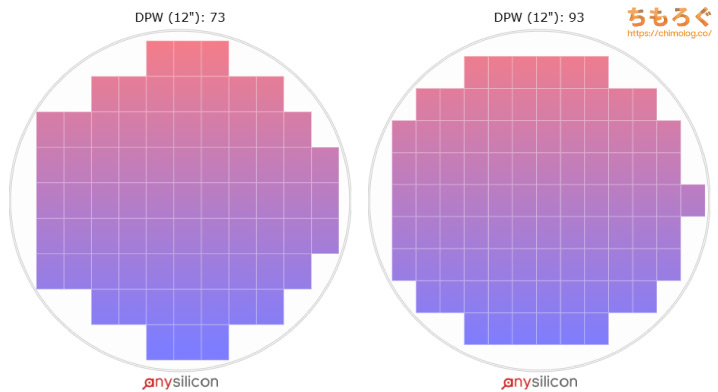
微細化でトランジスタ数が増えた分だけチップ面積を節約したシミュレーション(750 mm2 → 588 mm2)でも、チップ1枚あたり21%のコスト削減に過ぎず・・・到底同じ価格を維持するのは不可能です。
要するに、製造プロセスの微細化に頼った性能アップはすでに物理的な限界に到達しています。
だからNVIDIAはAI処理性能を活用した「DLSS超解像」「DLSSフレーム生成」「RTXニューラルレンダリング」など、処理する内容そのものの効率化に全力を挙げています。
- 実効フレームレート:ハードウェア性能 x 処理負荷(ソフト側)
ハードウェア側の進歩が限界なら、ソフトウェア側を進歩させれば良い、とするのがNVIDIAの現行スタンスです。
まとめ:ハードの進化はもっぱら「GDDR7」頼み
「RTX 50シリーズ」の微妙なとこ
- 実質5 nmな「TSMC 4N」製
- チップの設計規模はあまり変わらない
(RTX 5090のみ大幅増築) - 引き続き「NVLink SLI」は非対応
- 消費電力がやや増加傾向
- 円安進行で国内価格は値上げ
「RTX 50シリーズ」の良いところ
- 「ニューラルレンダリング」に対応
- DLSS 4「マルチフレーム生成」対応
- ドライバ側でDLSSを適用「DLSS Override」
- 帯域幅1.3倍「GDDR7」メモリ搭載
- VRAM帯域幅は1.3倍以上に進化
- 第9世代NVENC + 第6世代NVDEC
- エンコーダー(3基)+ デコーダー(2基)
(※RTX 5090のみ) - AI処理性能が2倍「FP4」演算対応
- 「Display Port 2.1(UHBR20)」実装
- 全体的にMSRP(価格)を引き下げ
(※RTX 5090は値上げ)
現時点の情報をざっくりまとめました。
RTX 50シリーズはハードウェア面で「GDDR7」の躍進が大きく、逆にチップ自体の設計があまり変わっていません。
その代わりと言うべきか、ソフトウェア面の進歩は相変わらず凄まじいです。AI技術を活用した処理負荷の軽減にコストを割いています。
PCゲーマーにとっては、RTX 5080以下の価格値下げが嬉しいです。ドルベースで全体的に安くなり、コストパフォーマンスの改善がほとんど確定します。
しかし、日本国内の価格はあいにくの円安により期待できないです。
RTX 4000ユーザーがわざわざ乗り換えるコスト的なメリットを見込みづらく、明確な性能アップを体感できるRTX 2000~3000ユーザーからの乗り換え需要が熱くなるシリーズです。
以上「RTX 5090 / 5080 / 5070 Ti:RTX 50シリーズの性能と仕様を解説」でした。
RTX 50シリーズにおすすめなCPU

最有力候補は「Ryzen 7 9800X3D」です。筆者やかもちも、RTX 5090や5080のレビューでRyzen 7 9800X3Dを投入します。
(2025年1月時点)地球上でもっともCPU側フレームレートが高い、ダイヤモンド級ゲーミングCPUです。

【セール気味】RTX 40シリーズ搭載のゲーミングPC





【レビュー】グラフィックボードのベンチ記事

















 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選

 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


BTOで5080と5070Tiに全然価格差が無いみたいな奇跡が起き無い限り、Ryzen 7 9800X3Dと5070Tiの組み合わせが最強コスパみたいな紹介をみんな挙って動画で上げる流れになるのかな。でも4070Tisuperをあれだけ推してたから買ってる奴はもうそっちを買ってそうだし価格が40万越えするなら暫くは様子見が続きそう。なんにせよ性能発表からの発売前期間から実機での性能検証のこの時期が一番ワクワクしますね。
こう並べるとやっぱり70Tiと80の差が他の差に比べて物足りなくて70Tiで妥協するか90行ってらっしゃい見たいに感じてしまう
それが狙いみたいなことも言ってたし
>空気を読めない弱い日本円のせい
円安のおかげで輸出企業は売上が増加して業績が向上傾向にありますが
空気を読めないのはどちらでしょうか?
大局を見据えていない短絡的な発言は自重なさったほうがよろしいかと
円安局面ではエネルギーや食料品といった一次産品は必ず上がる訳です。つまり円安とは家計部門から輸出セクターへの利益移管にすぎません。
円高で悪いことは何もありません。
産業構造の転換もせず、まして何のイノベーションも起こし得ない日本。この先もゆるやかに沈むだけだと思っておいた方が良いでしょう。残念ですがね。
まぁそうだね。
悪いのは為替レートより、上がらない賃金の方。
消費者目線で話してるのに急に「輸出企業ガー」とかお前が一番空気読めてないやんけ笑。最近円安について勉強したから話したくなっちゃたのかもしれないけど、皆の会話に割り込んで自分の話したいことばっか話してると友達なくすからやめようね。
円安になったけど企業はデフレ円高だった時に海外に生産拠点を移しており、現在の円安環境にも関わらず貿易収支は赤字となっております。
海外のサブスクに課金してマネーが海外に流出し続けているデジタル赤字の影響も深刻です。
つまり円安の恩恵は10年前、20年前に言われていたような効果は発揮できていない可能性があるとの分析を証券会社のエコノミストさんが出しておりました。
また過度な円安は輸入物価の上昇に対して実質賃金の低下をもたらしており、現在悪いインフレが発生している最中です。
おそらく古いデータのイメージで語っていらっしゃるのだと思いますが、大局的な視点で見れば今の円安は〇ソでゴ〇です。
それから中長期的には各種資源やエネルギーの国際価格はパンデミックや世界不況的な一時的停滞や下落があっても、基本的に上がる一方なので、多少円高になったところで根本的に経済成長しなければ結局いずれは赤字になりますよ。
円高ではそもそも輸入の原資を稼げないわけだし。あと貿易収支は今年に入って改善してるんですね。ようやく円安の効果が出始めたみたいですね。
補足。
今までは国際価格が安かったから円高で少ない収益でもあまり問題にならなかっただけのこと。これからは為替で安く仕入れるより、根本の経済成長をして基礎購買力を上げないとダメなんだよ。
その絶好の機会がこの円安なわけよ。そもそも論として経済成長しなければ、通貨価値だって上がらない事くらいいくら849でも分かると思うけど(笑)
そうやってダダをこねて円安敵視したところで何も変わらないよ。拒絶ではなくどう付き合うか、つまりは活用するかを考えないとね。この30年間上がらなかった賃金がようやく上昇し始めたのも円安で企業収益が向上し物価高で上げねばならない決定的な理由が生まれたからこそ。物価も賃金も上がらなかった今までが異常なだけであり、ようやく正常化に向かい始めただけのこと。
「円高の物価安」のぬるま湯に長い事浸り込んでたから成長が止まったわけだよ。これから例えばインバウンド観光立国目指すにしろ円安はチャンスでしかないんだよね。
目先の物価に囚われてようやく始まった成長のチャンスを拒否したら、通貨価値だって上がらないしね。それともそうやってダダこねてりゃ勝手に通貨価値が上がると思ってる?
あと円高で国内産業が空洞化し雇用や賃金にダメージ与えたなら、それこそ円高が悪ってことになるんだけど。このブーメラン振りが849の限界ってところか(笑)
大局を見据えていない短絡的なコメントは自重なさったほうがよろしいかと
気持ちは分かります。
最近ネットでは日本を下げるような発言が多いですからね
社会で必死に働いていると、頭に来ますよね。
ちもさんはまだ若いようですし寛大な視点で見てあげましょう。
いい歳した大人ならばすぐ頭にくるその短絡的な性格を改善しましょうよ。
何様?
「ブレーダー様のつもりです」
普通のエンドユーザーとしては現在の円安は確実に損なわけだし、
少なくともここの趣旨として弱い日本円と言うのは間違っていない。
PCパーツ系の一ブログに大局を見据えろとか何言ってるのかと。
もうちょっとここの空気を読んだ短絡的ではないコメントをお願いします。
円安のせいでグラボが値上がっていると言う事を
言っているだけなのに「輸出企業は売上が増加して」なんて知ったこっちゃないよw
円安で儲かる人もいれば円安で損する人もいるし
視野狭窄ってこの国の代表者かよ
日本は輸入国で内需が基本、日本人の大半は円安で損している
念のため言っておくと、前コメの視野狭窄ってのは消費者は円安で損するって事を理解できてない元コメントに対してね
消費者が購入額を気にしてる話と輸出企業が儲かってるって話はそもそも話題の対象が違う事が分かっていない?
大局を見据えたつもりになっている視野狭窄な発言は自重なさったほうがよろしいかと
輸入頼りの製品を趣味として嗜んでれば為替レート一つに一喜一憂してしまう気持ちは理解できる
ここのブログ主は左寄りだからしゃーない
いちいち思想の相違を気にしてたらネットなんて見れないよ
ネトウヨきめえ
アホなネトウヨがちょっとした表現で発狂してるだけか。
本記事は世界情勢など「大局を見据えて」書いたモノではなく、一般消費者から見たグラフィックボード(輸入品)に限った話です。
政治経済の話はしてません。単なる趣味(ホビー)の話です。
ビデオカードを放り投げて、表だったら明日は晴れ。
「空気を読めない弱い」日本円のせいで台無しになりそう
PCショップにCPUのレビューのチラシを置いてるほどのブロガーさんなのですから、せめてカッコ内の文字は入れないで書いてほしかったですね。
「空気を読めない弱い」ネトウヨのコメントですね。
>PCショップにCPUのレビューのチラシを置いてる
で?
そのチラシは経済紙か何かなの?
何をおっしゃってるのでしょうか?
ただ単に余計な一言を付ける必要が無いって意味ですよ^ ^
皮肉にそんなクソ真面目に返事されるとは思わんかったよ^^;
輸入品を購入する際、一消費者から見たら円安が重くのしかかっているのは事実でそれを表現しただけなのに
記事主が自分にとって好ましい発言、思い通りの発言をしないと気が済まず噛みついていくのって普通に怖いよ
為替は全体の話でPCパーツは局所の話。
空気そのものに対して、空気読めない云々は変な話と私は感じました。
円安で高くなるのが普通な所、少し安く提供した革ジャンが空気読めてないというのであれば理解できますが。
そもそも基準が相当高くなったのであまり変わらん。
arc b辺りがミドルの値段の基準になってほしいところ。
まあこの辺を見てもわかる通り余計な一言だったということでね
デジタル機器はハードウェアからOSまで全部輸入なんで当然円高の方が良い
デジタル機器のブログで輸出企業云々はそれこそそっちの方が空気読めてない
輸出的云々はわざわざそこまで書かなくてもわかってるでしょ、グラボを購入するに当たって円安が憎いってだけだと思うで。
ただ受け手側によってはムカつく書き方だな〜とは思ったから変えたほうがいいよね。
受け手なんて千差万別なんだから気にしたら何も書けんわ
あくまでも空気読めない輸出君の言いがかりが発端以外何ものでもない
コメントする閲覧者がTPO 弁えた発言すればいいだけ
言う必要のない不快なフレーズだったからこういう反応が出るのも理解はできる
国内企業がグローバルにグラボを輸出するようになってから言ってくれ…
愚痴を言うのは自由だから売れ売らないは関係ない
そもそも世界に向けてグラフィックチップ・カードを輸出してる「国」がどれくらいあるかわかるか?俺には分らん
少なくとも言えるのは、あんたの理屈が当てはまるなら、ほとんどの国の民は愚痴を言うなってことだな
このブロクのどこに輸出企業の話が出た…?グラボの話じゃないのか?空気読めないのはどっちだ?
rx9070xt君がんばってね!10万ぐらいだったら買ってあげるから!
AIで誤魔化す癖覚えたせいで自滅して
AMDに取って変わられるかもねIntelのように
これな。AIパチモンのフレームはいらんわ
RTX4000シリーズがTSMC N4カスタムで既にびっしりだったので、N4Pカスタムを使っている5000シリーズでトランジスタ密度が一緒なのは仕方ないですよね。
それとクロックも殆ど変わってない(むしろ下がっている機種もある)のと、CUDAコアに手が入ってラスタライズの実行性能が良くなっているという事もNvidiaが全く発言していないのでAI性能以外は殆ど据え置きなのかなという印象です。
プロセスがRTX40と同じ4Nだと報道があったのでN4Pカスタムじゃなかったそうです。
ちもろぐさんも修正よろしくお願いします。
>MSRP $ 549 $ 599
>発売価格 108800 円 99800 円
割引がない
おかしいな
グラボ1660tiだけどワイルズの為に5070tiへ買い替えかなー
4000シリーズの人は別にスルーでも良さそう
今のゲームはVRAM16GBは必須だから5070は論値だなぁ
そこらへんロクに説明しないPCショップの「○○の何倍の性能!」とかいう文句の被害者が出ないことを願うよ
NVIDIAもVRAM容量の問題は把握してるようで、DLSS 4モデルを使ってVRAMの消費量を節約する方針みたいです。
DLSS 3モデルはフレーム生成を使うとVRAM使用量が逆に増えていたので、DLSS 4はけっこう期待してます。
4080→4080S→5080
4070Ti→4070TiS→5070Ti
と1年ごとに置き換えているというテイで見るか
やかもちさんのように
4080S
4080→5080
4070TiS
4070Ti→5070Ti
と置き換え比較するかで見方がかわるシリーズだと思う
4070TiS(底値実質12万)と5070Ti(おま値推定16万)と4080(底値実質15万)で見比べたらなんだコイツ感が漂わざるを得ない
キャッシュと帯域幅で差は出るんだろうけどさ…
2080Ti以降グラボ買ってないけど5090が色んな意味でインパクトだから買いたいな
ただハード面での性能は微増って話だとフラグシップ購入は次回まで待った方がいいのかな
それにしてもマルチフレーム生成だのフレームワープだのAI技術面は面白そう
はやく実際のゲームプレイで実用性を確認したいね
Tisと5070tiの性能差が非常に気になりますね。4080と同等か超えることがあればメモリ性能も含めてtisから買い替えたいです。ワッパは多少悪化していますが、個人的に40世代のネックだったメモリが解消されて価格ほぼ据え置きと考えればそんなに悪く無いがします。TSMC5nmの完全版グラボといった印象でここから先の微細化によるコスト増を考えるとここらでいったん手打ちかもしれません。
RX9070XTに期待せざるを得ませんね〜
5080は4080と比較すると一見凄くコスパが改善されている様に見えるんですが、4080の事実上の値引きモデルである4080Sの存在を考えるとなんとも微妙…
>>革ジャンがせっかく値下げしてくれたのに、空気を読めない弱い日本円のせいで台無しになりそう・・・。
その通りだと思います50~シリーズの一番の利点は性能が微増ながらも抑えられた価格だと思いますが円安の影響で利点が曖昧になっているのが評価に難しいところです・・・
詳細な解説お疲れ様です。グラフィックボードの技術的仕様をここまで詳細に解説してくれる記事は大変貴重です。個人的にはDLSS4における4K時のフレームレートの改善には期待してます。
・・・ただ身も蓋もない話をすると価格帯が高くなりすぎてすべてのグラフィックボードが予算オーバーしているのが本音です。
10万円台のRTX3080(実際には12~15万が相場の期間が長かったですが)を見てきた身からするとRTX5070がかろうじて手が届くかなぁというレベル
現行機からミドル帯という概念が消えてハイエンド(5070)超ハイエンド(5070ti)超超(RTX5080)アルティメットハイエンド(RTX5090)とかいう冗談みたいな状況です。
これでRTX5070ti(15万)搭載のコスパ重視ゲーミングPC!とかの謳い文句で売り出されるわけですから今からゲーミングPC買う人は大変だなぁと思います。
RTX5070は人気になるというかそれしか選択肢がないんですよ。一般人にはPS5proの12万円ですら高い買い物ですからね。
価格15万円帯のグラボを載せたPCがこれからのゲーミングPCのスタンダード、所謂良コスパのBTOPCになると考えると周辺機器も考えたらゼロから揃えるならそれこそ予算40万からを考えなきゃならんのか。場所の確保にモニター・音響・マウスにキーボードetcetc…独り身以外は購入以前に家族に説明する方が大変そうだ。正しく年間計画だねぇ。
家庭があるならパソコンとリビングのテレビは切り分けないと面倒くさいことになるから60番台を搭載したエントリーモデルにしとけ。仕事でも使うって前提だとイラストレーターとかCADを使うとかがない限り24インチFHDが使い勝手がいいしな。
仕事でパソコンを使わんならプレステで9割役割をカバーできる
パソコンで4Kゲーミングなんてパソコンとメインのテレビを接続できる(=リビングを好き放題できる)独身貴族の遊びよ
5080がVRAM24GBならまだ購入の検討もあったのに
70tiと同じ16GBって売る気あるのか?って思ってしまう
なんかだいぶ前に5080は32Gbps出るGDDR7を24GB搭載するみたいなリークあったけど
それが5080tiとかSuperで来年出たりするんかな
GDDR6化以外に大して仕様上の変化がなかったのに数値が爆上がりした1660→1660Sの進化を経験してるのでGDDR7には期待してる
そろそろグラボ買いたいけど流石に4000を買うのは悪手かな?
グラボを単品で買うって意味だと4000は軒並み生産終了してるからピークよりちょっと高め
5000は5000で70以上なら6月、60に至っては年末あたりまで待たないとご祝儀剥げないんじゃって気はするからお値打ち価格で手に入れるってんなら結構待たんといけないが
そもそもBTO用の組み立て在庫すら捌けてて選択肢がほぼないし未だに残ってるのは売れなかったもののみだと思うんだよね
DLSSに対応しなさそうなゲームやってる身からすると50シリーズはめちゃくちゃ渋いなぁ
個人が勝手にVRAM増設するだけで性能向上した奴もあったはずなので露骨に絞りまくった40よりは事前予想より性能向上する事にはなると思う
90以外はただのリミット解禁&リネームモデル感は否めないけど安くなるならいいんじゃない?
NVLink SLIは使う場面が分からない
素直にもう一個PC買った方がAI生成組にもいい事なのでは?
スペック似たり寄ったりなのを一万円刻みで出されるよりはこんな人はこれを買ってねとハッキリ言われる方がいい気がしてきた
10万切りはロー(実質ミドル)の5060系に期待するしかないな。
どう考えても値段帯おかしいけれど。
救いは5060Tiか?
リークじゃVRAM16GBらしいし。
そんなあなたに、RX9070XT
まあ値段まだ未発表だけど…
5090のTOPS比較表、fp4で条件が揃っていないというのが気になるところですね
早く実際の計測が見たいものです
fp8のforgeは確かに早いが品質が微妙…このせいでA1111から脱することができない
4年前に買ったBTOパソコンから乗り換えで初めての自作PCを作ろうとしています。9800X3Dに合わせるならどのグラボが現状ではおすすめだと思いますか?5090は予算オーバーなので他の3つで教えて頂きたいです。発売してすぐには買えないのでベンチマークとか色々見て買う予定です。ゲームはFPSから高画質ゲームまで色々やります。
現在のスペック
Ryzen 5 5600X,RTX3070
1年後に5080Super、5070TiSuperが出て来そうではある
3060の12GBを使ってる人への乗り換え先が中々出ない
ミドル?に12GB以上がまた来るときはあるのか
日本円はカスだし
自民サポーターはそれ以上のカスのガイだからね
アタマ弱くてこんなトコまで荒らしにくる。病気だよ
いまだに輸出企業が儲ければ状況が良くなると思ってる奴いんのかよ…
為替ってのは交換する相手がいて初めて成り立つんだよ
外国にモノが売れるってことは、その利益を持ち帰るためには、輸入品や外資系をその分国内に入れることとイコールなのよ
輸入品や外資系が増えれば国内の中小企業が割を食う、その結果、金のめぐりが悪くなり不景気になる。
つまり、貿易の規模がデカくなればなるほど不景気になるってこと。
これが失われた30年の正体。ドイツや韓国も同じ状況だろうね
グラボの値段における為替レートの話をしたら政治が〜経済が〜って発狂して荒らしに来る政治カスさんキショ過ぎて泣いちゃった
文脈も読まなきゃ空気も読めない
既存のRTX40ユーザーで、性能的に満足なら、DLSS4頼みで、演算性能の上げ幅は微妙そうなRTX50に乗り換える必要性はあまりなさそうな?ちゃんとしたレビューが出ないとなんとも言えないが。
5090は、生成用でとか、コスト度外視のハイエンド志向の方には刺さりそうだけど。
5070でVRAM 12GBは、少し気になる。ゲーム用途でも必要VRAMは増加傾向だし、数年耐えられるのだろうか?このクラスでも昔では考えられないお値段なだけに。
これなら、AMDがハイエンドやめてミドル勝負に賭けてしまうのもわからなくのもないような?
赤軍団のRDNA4 ベースの9070XTの詳細次第で面白い戦いになるかもしれない。
ハイエンドグラボが5~7万、ミドル2万くらいの時代に戻らないかなぁ・・・。
地獄かな
「記事主は左!反省しろ!」
「自民サポは病気だ!」
だね、よくそれだけでカッカできるなあと感心するよほんと
よっぽど暇なんかなあと
この世は地獄さね….
地獄を見れば 心がかわく
知ってた
NVIDIAはニューラルレンダリングを開発者に活用してもらうことで積極的なメモリ消費の削減を目指していると感じましたが
VRAM容量のアップグレードはあるんでしょうかね
下手に増やせば新機能推進の妨げになりかねませんし
結果必要メモリの増大が止まらなくなりそうな気がします
帯域幅80 Gbpsに達する「Display Port 2.1」の章の画像
解像度ごとに必要な帯域幅(Gbps)内の図において
7680×2160-120Hzの帯域幅が22.6/67.9なのに対して
7680×4320-120Hzの帯域幅が21.3/63.9なのは何故でしょうか?
同じように
7680×2160-240Hzの帯域幅が45.2/135.7なのに対して
7680×4320-240Hzの帯域幅が42.6/127.8と記載されています。
通常同じリフレッシュレートであれば、高解像度な方が帯域幅が多くなると認識しています。
素人質問で申し訳ありませんがご教授いただければ幸いです。
10年前なら80はゲーマー向けでしょうが、今の日本値段ではTITANですよ(泣
円安の問題だからしゃーないな
革ジャンもNVIDIAも何も悪くないどころかダイサイズ大きくなったのに安くしたのは称賛するところ
tisみたいな後出しが嫌だからとでそこまで待つと、後少しで6000シリーズ出そうになって買えなくなるんだよな
結局欲しい時に買うしか無い
値段はグラボだけ終わってる
やかもちさん
攻撃的なコメントに屈せず頑張って下さい
あなたの記事が非常に有益でユーザーフレンドリーだからです
私はあなたを支持します
質問なのですが軽くAIイラスト作成やる場合はどれがいいでしょうか?
このブログ内を「グラボ AI」で検索すれば記事が出てくるよ
ありがとうございます
グラボのまとめでバカウヨが発狂してて草
んーーースキップ推奨世代って感じ
管理人さんは温情で5080と4080無印を比べてるけど4080Super版と比べたら買う価値が感じられるか本当に、、、本当に微妙なところですね…
まだ4090でいいな
AI生成もしないししたいゲームも当分ないし
通貨高はいくらでも是正できるが
通貨安は対応に限りがあるんだよな
通貨安なんて良いこと何もないわ
80以上でやっと買う価値出てくるくらいなら現状まだ買わなくて良いね
来年まで様子見かな
ここのキチガイコメント欄なんて開いてたらやかもちの頭が壊れるだろ…
閉鎖したほうが良いよ
ここのコメント欄で分かった事は右も左も害って事だね。
どっちも湧いてるから地獄絵図になってる。
このサイトはPCパーツを扱ってるんだから円安は悪
それでいいじゃないか
日本でグラボを製造してるならともかく
「実は向こう10年間のうち今が一番円高だった」可能性も充分過ぎるくらい有るから欲しいときに買っとくのがええよ…
過去の円が高かったことは何の保証にも補償にもならんよ、今後高くなる要素が無いんだから
弱い日本円はジョークなのかアホを露呈したのか
現在下記電源を用いているのですが、RTX5090を5090付属の8pinx4口⇒12V16pin変換ケーブルを用いる場合、二股Yケーブルの8pinコネクタを両口使用することはできないのでしょうか?(Y字ケーブルを2本使って、4口接続)
CPUに電源側の2口使ってしまっており、グラボに使用できる電源側の口が3つしかないため、二股Yケーブル3本しか利用できない状態です。
電源側のケーブルスペックを見ると8pinケーブルは最大100Aまで流せるみたいです。ただ、「二股8pin両方は使うな」とよく聞くのですがあまり理論がわからず、ご存知でしたら、ご教授いただけないでしょうか?
TOUGHPOWER GRAND RGB PLATINUM 1200W
同様の電源の1050W版を使っていて同じような問題(GPUx2のため)に当たりましたが、素直にペリフェラル4Pinのケーブルを2本用意してその2本、またはSATAケーブル2本からPCIe8Pin一つに変換して…というような構成にする手もあります。
(接点が増えるとかなり不安ですけど)
素直に12VHPWRに対応している電源に買い替えでいいような気がします。
本家のアクセサリで8Pin2本から12VHPWRに変換するものも販売されていますが、300W以上が必要とされる場合は危ない気がします。
3070tiからの換装を考えてますが
価格に泣かされそうですねぇ・・
5090の先行レビューを見る限り電源が心配になるレベルの消費電力とケーブルの発熱、そこまでやって3割増しに届かない性能向上幅か
やかもちさんも隠す気の薄い裏垢で最速レビューとかはしなさそうなことを書いてたし期待より不安が
未だに2019年に買ったGTX1660(6Gモデル)のワイは5000番代に買い替えた方がお得なのか?
AIもやりたいから5070Ti買いたいけど、最近の情報だと5000番台は微妙だとか言われてるから6000まで待とうか迷うわぁ。
てか、最近のゲームは1660には厳しいけどねw
ちな、CPU9700X・マザボX870 Steel Legend WiFiに最近変えた。
その組み合わせだとGPUが足を引っ張りすぎるからさすがに買い替えちゃった方が
AIをすでにやり込んでるんなら5070Tiでもいいだろうけどお試しでやってみたいレベルなら5060Tiや5060も16GB版や12GB版の登場は噂されてるからその辺でお試し、って感じでもいいだろうし
お前みたいな奴はもう一生待っとけよw
5070と5070tiの差がえげつない
5070tiは欲しいけど750ドルが15万になるのはキツい
4070 Ti superがバランス良かったから5070 Ti super待ってるけど
いくらになるかなぁ…20万?
もう皆さん一生待てばいいんじゃない?
50シリーズが数年持たないって人いるけどマジで言ってんのかネタなのかどっちなんだろ。そんな最強ゲームばっかり出るわけじゃないっしょ。
25年11月くらいに、16300コアで24GBの5080tiが1249ドルで来て、5080が899に価格改定、ぐらいがありがたい(顧客側の願望)んですが。
今世代は性能あたり価格が下がってなさすぎ。トランジスタ数も据え置き…
これからしばらくは新GPUやモンハンのベンチでお忙しいかと思いますが、そのうち Civilization VIIに向くCPUの傾向を調べていただけましたら助かります。
ターン制RTSな都合で一般的なフレームレートベースのレビューがほとんど参考にならないもので、「ゲーム後半の重くなる時期にターン送りにかかる時間」を見ていただけると嬉しいです。
同じセーブデータをロードしてターン終了から次のターン操作可能までの時間を計る形で十分かと思います。
公式の4K推奨環境がやけにコア数の多いCPUを挙げているので、(i7-14700とR9 5950X)
ひょっとしてマルチスレッド重視の作りになっているのか?の疑問があります。
そこまで細かく指示するなら自分でやったらという
しかもゲーム後半ってそんな条件を平気で被せてくるのがよく分からない
慈善事業じゃないんだぞ
6080はVRAM24GBなるといいなぁー
RTX4080使っているからこの世代はスルーかな
40SUPERシリーズとの比較がないのは差があまりないためなのだろうか…
なにより素晴らしい記事にありがとう!
わかりやすいし詳しい!
4070Superと5070だと4070Superの方が良いのかしら?
記事どうりだと5070が4070Tiぐらいと書いてあるが、4070から6%向上で4070Tiぐらいになるの?
Nvidia公式からニューラルシェーダーなどの技術はRTX50専用の技術ではないと発表ありましたよ、ちもちゃん
5000シリーズを海外の某人気youtuberが「Disaster」と言っているぐらい酷い出来だったので、乗り換え先としてradeonを考えているため、気が向いたらレビューしてくれると嬉しいです
去年のうちに4070ti SUPER載ったPCに買い替えるんだった…
25万で売ってたのになぁ…
今読み返すと5070は4070tiちょっと超えるだけて予想てのは希望的観測すぎたな、実際には4070superとどっこいどころかゲームによっては負けるし9070xtどころか5万円安い9070無印並ていう…
radeonのfsrも褒められたもんじゃないけどNVIDIAのミドル以下のVRAMドケチが致命的過ぎる
5090のROPSが176なのに192になっています
VRAM少なすぎ
GDDR6X から GDDR7 になって、記憶密度が1.5倍?
RTX4090がGDDR6X 24GBで、RTX5090がGDDR7 32GBか・・・32GB?
36GBじゃないのは、RTX6090までの間にRTX5090 Tiが挟まれるのかな・・・?
VRAM GDDR7 36GBが出たら買いたいな。
でもAI生成がおっそいんだよなぁ・・・。
MFGでレイテンシが爆増ってのを見たから実際どの程度なのか知りたいな
まあ購入しようにも物がないし高いんだけど
一応先にRTX5080は手に入れた(通常定価通販購入)、来月後半に残りのパーツ買って新規にメインPC組めるわ。 流石にRTX5090は高くて買えないしあんな化け物は手に余る
4000番代との同型機とじゃなく”近い実売価格帯機”と比較して欲しかった。
と言ってももう売ってないから無理か…
通貨価値を上げたければ経済成長しなければならず、その為には円安はチャンスでしかないんだよね。日本は未だに輸出立国(海外生産も含む)で、さらに観光立国も目指してる訳だから。円安ガ〜内需ガ〜とわめく849は鎖国でもしたいのかな?内需でどーやって外貨稼ぐんだろうね(笑)普段人口減少で騒いでるくせに飛んだダブスタだね。
大体この30年ほどどちらかというと円高傾向の物価安のぬるま湯に浸れ込んでいたから経済成長の必要性に迫られなかったのが異常なわけ。(物価が安ければ賃上げの必要性もなく、円高で企業収益が少なければその原資も生まれない)
目先の物価に囚われて円安を敵視悪役扱いしてる限り何も変わらないよ。さすがにダダをこねて円安敵視してりゃ勝手に通貨価値が上がるとはいくら849でも思ってないよね?
それからこれはライトに対してだけど、サムスン下げTMSC上げ傾向のブログ主は言うほどレフトかな?
ところでフレーム生成って、液晶テレビでは10年以上前からある技術なんだけど(いわゆる倍速表示)、グラボよりむしろモニターにつけたほうがいいような?なぜPCモニターにはこの機能がないのかな?
5070tiのアイドル時の消費電力がやたら高いのはどうにかならないのかねぇ
やかもちさんはもうRTX5090を買われましたか?RTX5090はCUDA12.5以上が強制でpytorchやTensorFlowが未対応。RTX5090の内部バージョン番号sm_120が認識できずにRuntimeError: CUDA error: invalid device function (sm_120 not supported)等のエラーが多数。sm_120はBlackwellアーキテクチャ専用で、旧世代とは命令セットも実装も異なるため、下位互換性がないため。stable diffusionでも一部のFP16/INT8カーネルが動作しない・未最適化のため、推論時にNaNが発生。
RTX5090を購入する層はAI・機械学習目的なのに、こんな安定して使えないGPUを売るなんてひどいと思いませんか?
自分はRTX4090からの買い替えを検討しましたが、RTX4090が安定運用できる最上位GPUということで買い替えを諦めました。
[…] RTX 5090 / 5080 / 5070 Ti – RTX 50 シリーズの性能と仕様を解説 | ちもろぐ […]
5000シリーズでFP4とFP8とFP16で、画像生成速度とVRAM使用量と画質を比較していただけると嬉しいです。