
中国アリババが公開した「Wan2.2」動画生成モデルで、快適に動画を生成できるグラフィックボードを実際に検証します。
今回は、RadeonやIntel ARCを含む40枚のグラボで性能比較です。
360pから480pはもちろん、アップスケーリング無しでも高画質に見える720p解像度まで、3パターンの動画で検証します。
(公開:2025/8/10 | 更新:2025/8/28)
動画生成AI(Wan2.2)におすすめなグラボを検証
検証方法:動画の生成時間をテストする
動画生成AI(Wan2.2)に適したグラフィックボードをテストする方法はシンプルです。
定番の生成ソフト「ComfyUI」を使って、実際に動画を生成します。今回の動画生成AIベンチマークでは、以下2つの数値を「性能」として扱います。
- ログに表示される生成時間
(Prompt executed seconds) - ステップ数を生成時間で割った速度
(Iterations per Minutes)
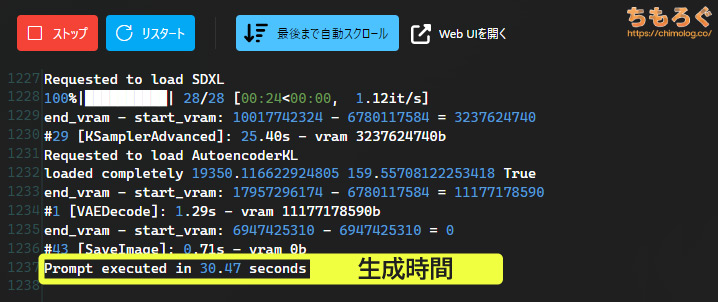
生成時間がもっとも直感的に理解しやすい指標です。
生成ボタンをクリックしてから、完成した動画が実際に表示されるまでの時間(Prompt executed seconds)を示します。
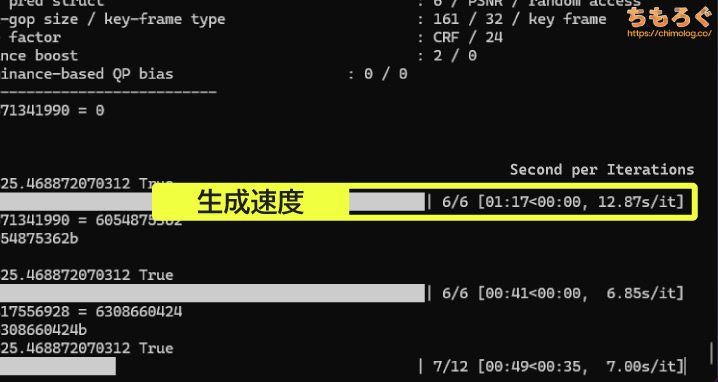
生成速度も参考程度に使いますが、ログ画面に表示される速度は実態以上の性能に勘違いさせる危険性が高いです。
本記事では代わりに、合計ステップ数を全体の生成時間で割ったオリジナル指標「Iterations per Minutes(1分あたりステップ数)」を採用します。
Iterations per Secondを略して「it/s」と呼ばれる、いわゆる生成速度ですが、誤解を招きやすい深刻な欠点があります。

Wan2.2モデルによるAI動画生成は少なくとも9~11段階もの工程がある、非常に複雑なワークフローです。
翻訳モデル(テキストエンコーダー)をロードして、指示内容(プロンプト)を読み取って機械語に変換したり。動きを生成するHighモデルと細部を生成するLowモデル、合計2つの生成モデルを動かして動画を生成したり。
広範囲なワークフローゆえに、生成時間がかなり長くなる傾向です。
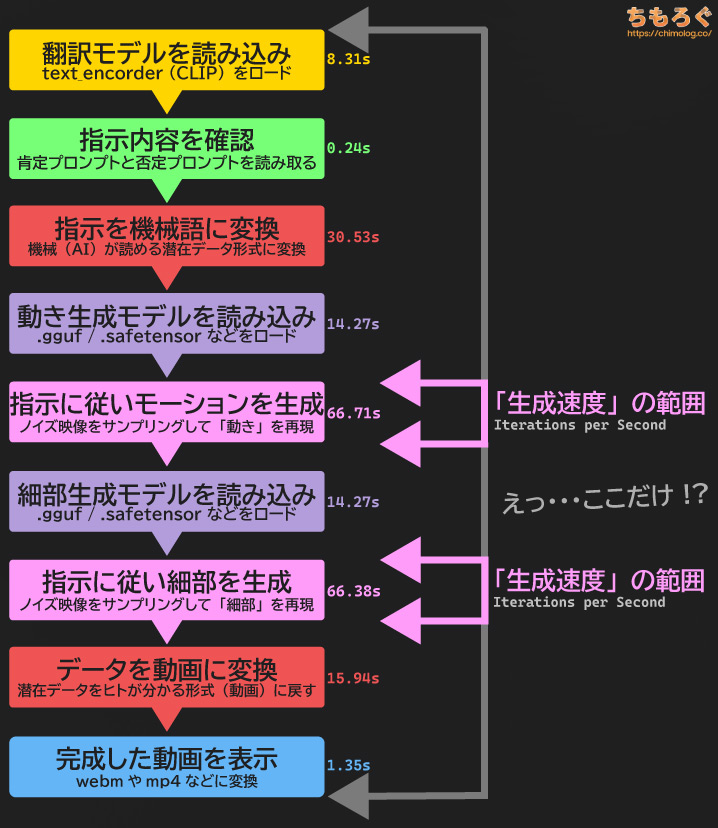
一方、「生成速度(it/s)」が測定している範囲は「生成モデルがデータを生成する2工程」だけです。
VRAM容量が少ないグラボで目詰まりを起こしやすい、VAEエンコードとVAEデコード時間が含まれていません。
VAE処理でどれだけ時間がかかっても、生成速度(it/s)に一切反映されないため、速度をそのまま指標として使ってしまうと誤解を招きやすいです。
生成速度が速くても、最後の処理がなかなか終わらなくて一向に動画が完成しない・・・なんてグラボを買いたくないですよね?
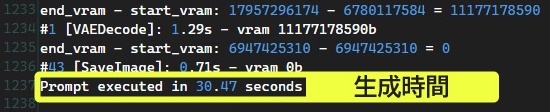
結論、「生成時間(秒)」を参考にしてください。
なお、本ブログに掲載する生成速度「Iterations per Minutes(1分あたりステップ数)」は、合計ステップ数を生成時間で割ったオリジナル指標です。
VRAM容量の少ないグラボが引っかかりやすい、あの忌々しいVAEエンコード & VAEデコードも含めた生成速度なので、実態に近い数値を出せます。
テスト環境:使用したグラボとPCスペックを紹介

| テスト環境 「ちもろぐ専用ベンチ機(2025)」 | |||
|---|---|---|---|
| スペック | NVIDIA GeForce | AMD Radeon | Intel ARC |
| CPU | Ryzen 7 9800X3D(レビュー) | ||
| マザーボード | ASUS TUF GAMING X670E-PLUS WIFI | ||
| メモリ | DDR5-5600 128GB(64GB 2枚組) → Crucial Pro DDR5-5600 | ||
| グラボ 全40枚 |
|
|
|
| SSD データ置き場 | WD Black SN850X 8TB → 8 TB版レビューはこちら | ||
| OS | Windows 11 Pro (24H2) | ||
| 生成ソフト | ComfyUI v0.3.50 pytorch 2.7.1 + cu128 | ComfyUI v0.3.51 pytorch 2.6.0 + rocm6.4.2 | ComfyUI v0.3.51 pytorch 2.9.0 + xpu |
| ドライバ | Game Ready 580.88 WHQL | Adrenalin 25.6.3 WHQL | Intel Graphics 32.0.101.6989 |
| ライブラリ | NVIDIA CUDA | AMD ROCm PyTorch for ROCm 6.4.2 | Intel XPU Intel Extension for PyTorch |
今回の動画生成AI(Wan2.2)ベンチマークで使用するテスト機のPCスペックです。
CPUにRyzen 7 9800X3D(8コア16スレッド)、メモリにDDR5-5600(JEDEC準拠)を容量128 GBたっぷり搭載しました。
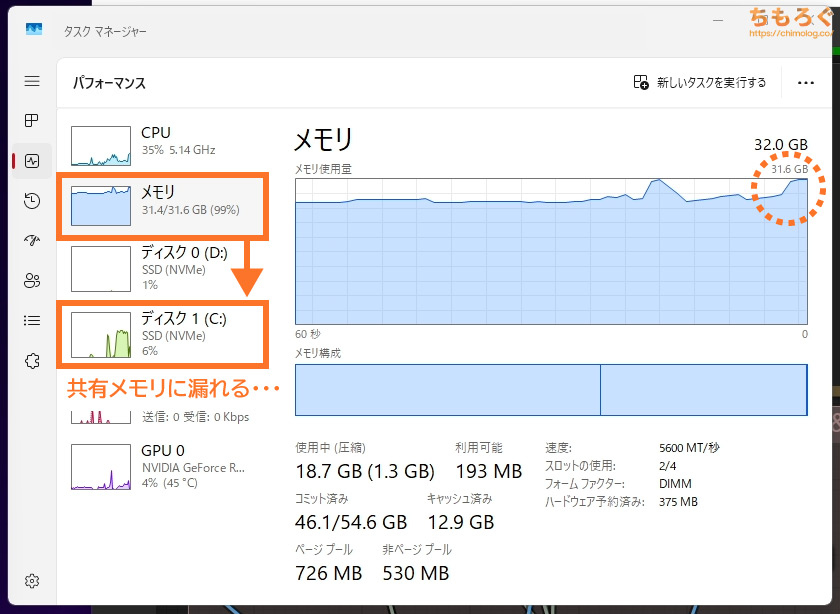
(共有メモリに漏れるとSSDの寿命を無駄に浪費するし生成速度も・・・)
画像生成(SDXL)と打って変わって、動画生成AI(Wan2.2)のメモリ使用量は常軌を逸しています。容量32 GB程度なら余裕で食いつぶし、システムSSDに漏れます。
データがSSDに漏れてくると、生成速度が大幅に悪化するうえに、SSDの寿命(TBW:書き込み保証値)を無駄に消耗します。
最低でも64 GB以上を検討したいです。今回のベンチマークではデータの正確性を重視して、2枚組の容量128 GBを念のため搭載しました。

テストに使用したグラフィックボードは全部で40枚(GeForce:31枚 + Radeon:7枚 + Intel ARC:2枚)です。
約50枚ほどグラボを検証用に所有していますが、時間の都合で古い世代を見送っています。
【グラボ別】動画生成AI(Wan2.2)の生成速度

全3種類+αのベンチマークで生成時間(秒)と生成速度(it/m)を比較します。
テストごとに使用したモデルやプロンプト、細かい設定やシード値はそれぞれのテストごとに記載します。テストごとに、ComfyUIで使えるテンプレート(workflow)も配布します。
ComfyUIでWan2.2を動かすとき、おもに2種類のワークフローが主流です。
- Native版(いわゆる公式ワークフロー)
- Kijai版(省メモリ & 高速ワークフロー)
Native版はComfyUI公式が提供するワークフローです。メインメモリを湯水のように消費しまくる重量級ワークフローですが、トップクラスの生成品質を誇ります。
大量のステップ数でゴリ押しするシステムで、豊富なモーションサイズとダイナミックな映像を出力します。
一方で、Kijai版は拡張プラグイン「WanVideoWrapper」と「KJNodes」を組み合わせた、省VRAMかつ省メモリな軽量級ワークフローです。
VAE分割エンコード & デコードに対応し、少ないVRAM容量でもなんとか押し通せます。高速化LoRA(Lightx2v)も使っているから、少ないステップ数で動画が完成します。
しかし、高速化のため大量に計算を端折っている影響があり、動きが少なく色の変色も課題です。
今回のベンチマークでは「Kijai版」を採用します。
日本国内でもっとも利用者が多い、あの著名なワークフロー「EasyWan22」の基幹システムが、まさにKijai版だからです。
利用者がもっとも多いと予想されるEasyWan22を想定して、あえてKijai版をベンチマークに使います。
その代わり、ベンチマークと同じ設定を入れても生成結果の再現性が一切ありません。再現性を無視してください。
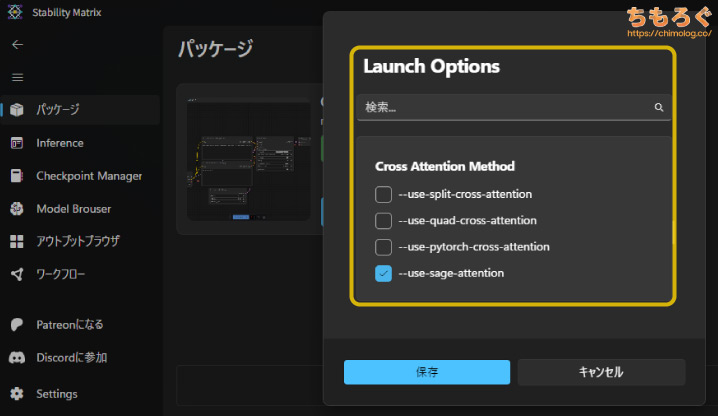
| ComfyUI 起動オプション 「Stability Matrix」の引数 | |
|---|---|
| GeForce RTX 30~50シリーズ | --fast --use-sage-attention |
| GeForce RTX 20シリーズ | --fast --use-sage-attention |
Stability Matrixから設定できる「Launch Options」を、グラフィックボードの仕様に合わせて調整します。
GeForceシリーズは高速化オプション「--fast」と「--use-sage-attention」を入れて、Kijai版ワークフローを動作可能な状態にします。
| GeForce GTX 16xxシリーズ GTX 10xxシリーズ | --fast --lowvram |
|---|
GTX 10xxシリーズ以前は、メインメモリの利用比率を増やす「--lowvram」オプションを追加します。
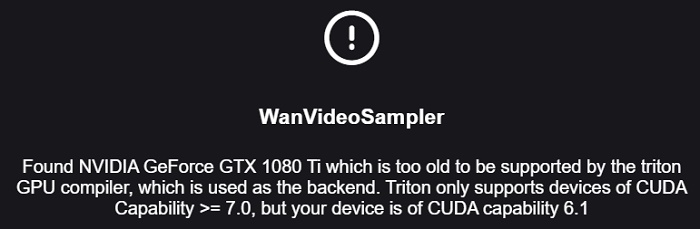
世代が古すぎてSage Attention(Triton)が正常に動作しなかったので、Sage関連の高速化オプションを抜いて、Kijan版ワークフローを「SDPA」モードで動作させます。
| AMD Radeon RX 9000シリーズ RX 7000シリーズ | --use-sage-attention --bf16-vae --disable-xformers |
|---|
AMD Radeonシリーズは、処理速度を向上させる「--use-sage-attention」と、一部のVAE処理を安定化させる「--bf16-vae」も併用します。
| Intel ARC A / Bシリーズ | --normalvram --bf16-unet |
|---|
Intel ARCの場合、なぜかVRAM比率に関係するオプションがまったく効果を示さなかったので、諦めて「--normalvram」をそのまま使います。
「--bf16-unet」は、生成品質をほんの少しだけ捨てて、代わりに動作の安定性を向上させるオプションです。

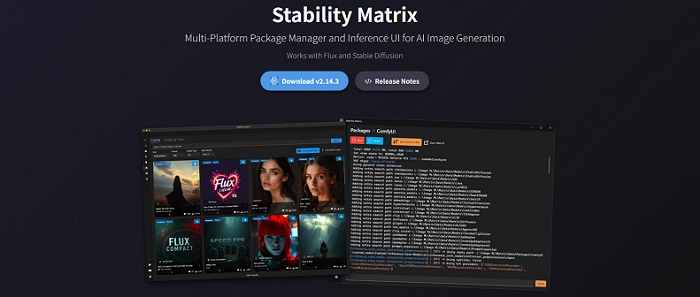
| テストに使用した生成AIソフト | |
|---|---|
| GeForce用 | ComfyUI(Stability Matrix) (https://lykos.ai/) |
| Radeon用 | |
| Intel Arc用 | ComfyUI(Intel XPU) (https://github.com/ai-joe-git/ComfyUI-Intel-Arc-Clean-Install-Windows-venv-XPU-) |
パッケージ管理システムを「Stability Matrix」に、AI生成を実行するソフトを「ComfyUI」に一本化します。
豊富な人材と資金に恵まれ、長年にわたってサービスが続く可能性がもっとも高いです。
動画生成モデル「Wan2.2」や、画像生成モデル「Qwen Image」や「Qwen Image Edit」など、最新技術へのネイティブ対応も他に類を見ない最速級。
PyTorchやSage Attention(Triton)など各種ライブラリから、FP4演算モード(Nunchaku)まで、最新の高速化技術の対応も非常に早くて助かります。
テンプレートファイル(ワークフロー)をComfyUIに放り込むだけで設定値をキレイに再現できる仕様があり、正確なベンチマークに使いやすい利点もあります。
416×416:Wan2.2 360p ベンチマーク
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | 坐在椅子上的美少女的3D模型被放置在地面上。 | ||
| Negative | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | ||
| 各種設定 | |||
| 長さ | 81 | ステップ数 | 8(2+2+4) |
| Width | 416 | Batch count | 1 |
| Height | 416 | Batch size | 1 |
| CFG Scale | 3.5 / 1.0 / 1.0 | ||
| Seed | 2870305593 | ||
| 各種モデル (URLはワークフローにまとめ) | |||
| 生成モデル(HIGH) | Wan2.2-I2V-A14B-HighNoise-Q6_K.gguf | ||
| 生成モデル(LOW) | Wan2.2-I2V-A14B-LowNoise-Q6_K.gguf | ||
| 翻訳モデル(CLIP) | umt5_xxl_fp8_e4m3fn_scaled.safetensors | ||
| 高速化LoRA(HIGH) | Wan2.2-Lightning_I2V-A14B-4steps-lora_HIGH_fp16.safetensors | ||
| 高速化LoRA(LOW) | lightx2v_14B_T2V_cfg_step_distill_lora_adaptive_rank_quantile_0.15_bf16.safetensors | ||
| VAE | Wan2_1_VAE_bf16.safetensors | ||
- ComfyUI用
ワークフローをダウンロード(.zip)
イラスト(Image)から動画(Video)に変換する、I2V(Image to Video)ベンチマークです。
360p相当の粗い解像度(416 x 416)で、長さ5秒(81フレーム)の動画をWan2.2で問題なく生成できるか。基本的な動作チェックが目的のベンチマークです。
それほど実用性のない解像度だから、技術デモに相当します。「あんな古い世代のグラボでも一応動いてしまう」を検証できます。

(※クリックすると画像拡大)
予想に反して、幅広いグラフィックボードでWan2.2の動作確認が取れました。
グラフが横に長過ぎて見切れていますが、もはや骨董品のGTX 1050 Tiですら、約70分を費やして360p動画(5秒)を生成可能です。
生成AIと相性が悪いRadeonシリーズも思ったより動いていて、特にAMD ROCm(Windows版)の最適化が進んでいるRX 7900 XTXが健闘します。
といっても格下のRTX 5060 Tiに肉薄する程度で、約12万円の価格を考えればまったく褒められた性能じゃないです。
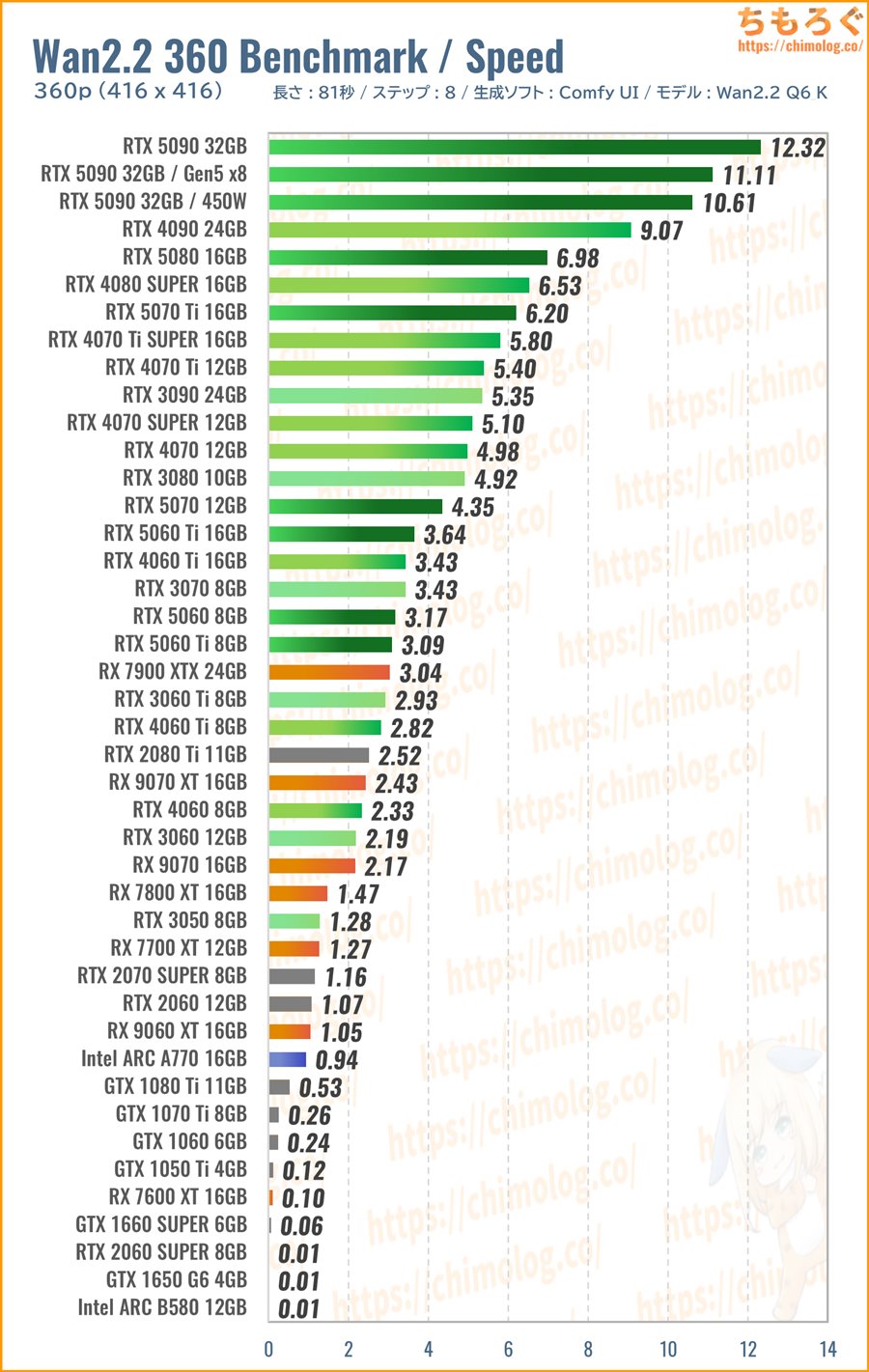
(※クリックすると画像拡大)
生成速度(1分あたりステップ数)を比較します。
動画生成AIを快適に動かすなら、やはりGeForce RTX 40 / 50シリーズが無難です。GDDR7メモリとPCIe 5.0インターフェイスを備えるRTX 50シリーズが特におすすめ。
高速化されたKijai版ワークフローは、使い終わったモデルをいったんメインメモリに戻す(= オフロード)処理を繰り返すため、PCIeスロットの帯域が重要です。
- RTX 50(PCIe 5.0 x16):最大32 GT/s
- RTX 40(PCIe 4.0 x16):最大16 GT/s
毎秒16000 MB/sも速度が変わってきます。サイズが大きいモデルになるほど、オフロード時の移動時間も伸び、PCIeスロットの帯域が地味に効いてくる傾向です。
800×448:Wan2.2 480p ベンチマーク
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | Two women sit facing each other, gazing intently into each other's eyes with quiet affection. They lean forward and share a warm embrace, then gently pull apart after a brief pause. Smiling playfully, they then raise their hands, their fingers carefully curving to form a perfect heart shape. | ||
| Negative | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | ||
| 各種設定 | |||
| 長さ | 81 | ステップ数 | 8(2+2+4) |
| Width | 800 | Batch count | 1 |
| Height | 448 | Batch size | 1 |
| CFG Scale | 3.2 / 1.0 / 1.0 | ||
| Seed | 20250138 | ||
| 各種モデル (URLはワークフローにまとめ) | |||
| 生成モデル | 「Wan2.2 360p Benchmark」と同じ | ||
- ComfyUI用
ワークフローをダウンロード(.zip)
Wan2.2モデルで主流な480p相当の解像度(800 x 448)で、長さ5秒(81フレーム)の動画を生成します。
480p相当のネイティブ解像度があれば、単純なアップスケーリングでそこそこの画質に変換可能です。寝ている間にたっぷり時間をかけるなら、「SeedVR2」である程度の超解像度も可能でしょう。
Wan2.2を楽しむうえで、最低限ほしい解像度が480pです。
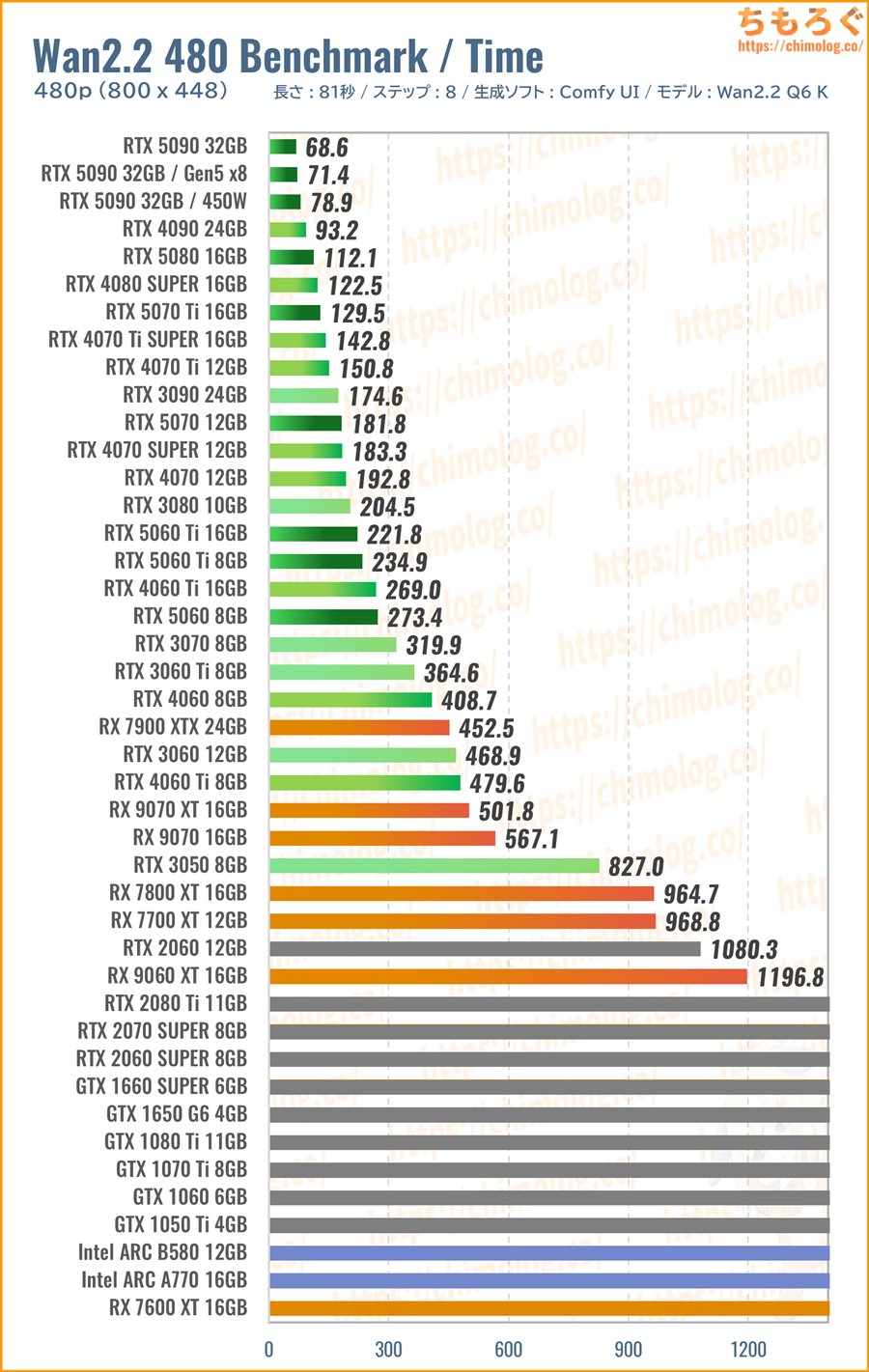
(※クリックすると画像拡大)
VRAMの使用量が明らかに増えてきて、VRAM容量の少ないグラボが苦戦し始めます。
旧世代のGeForceやRadeonシリーズも根本的に処理性能が不足し、5秒の生成に約10分以上を要する惨状です。
360p解像度なら動いていたIntel ARCシリーズは、ほんの少しでも共有メモリに漏れると指数関数的に生成時間が伸び続けて測定不可でした。
480p解像度をまともに生成できるグラボは、VRAM容量8 GBならPCIe 5.0世代(RTX 50)に限られ、基本的にVRAM容量12 GB以上かつRTX 40 / 50が最低ラインです。
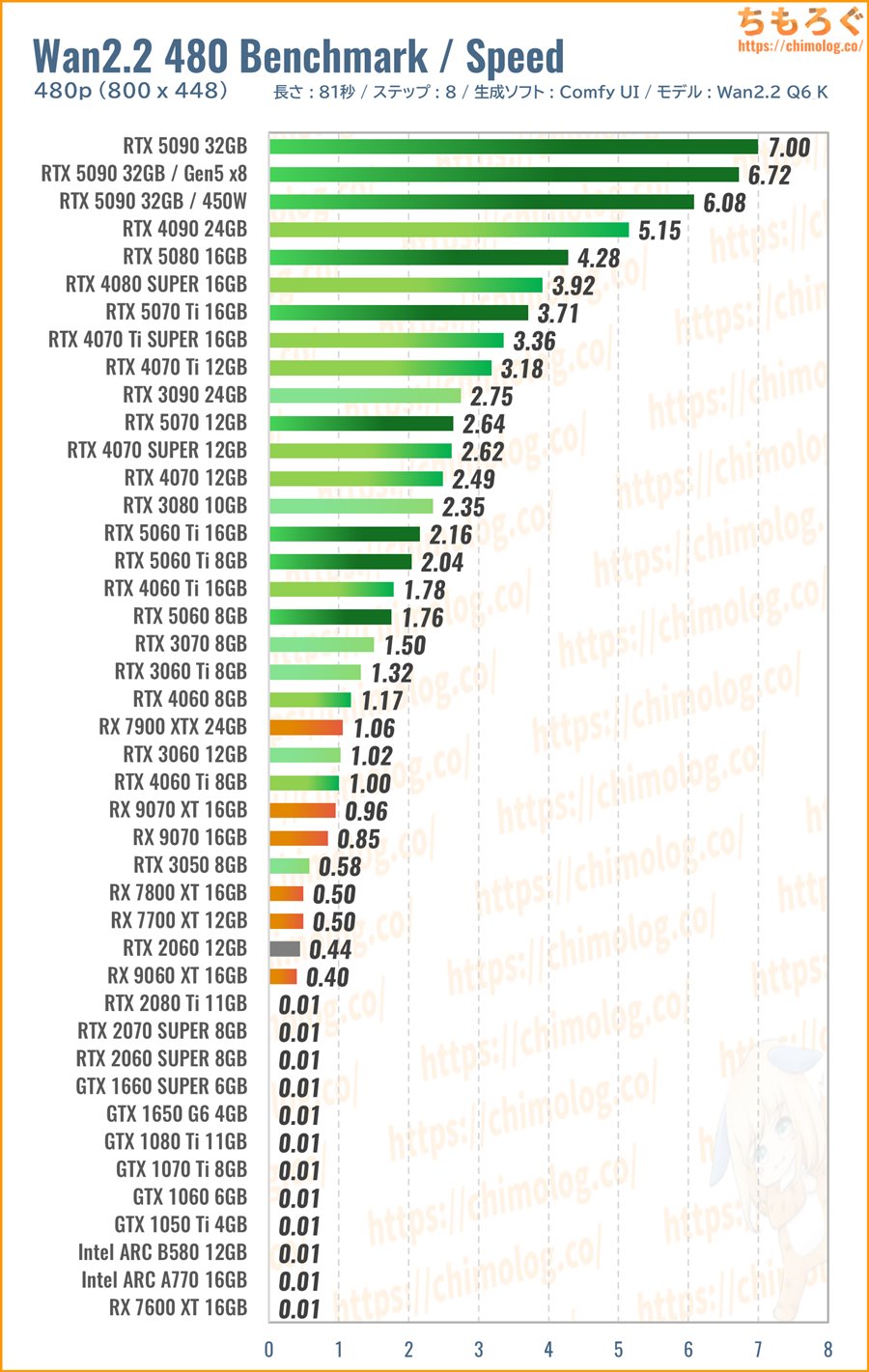
(※クリックすると画像拡大)
生成速度(1分あたりステップ数)を比較します。
やはり、RTX 5090が強烈に速いです。1分あたり7ステップを処理します。そこそこ使える480p解像度の5秒動画を、わずか1分ちょっとで生成するスピード感です。
RTX 4090とRTX 5080もなかなか悪くない手応えです。RTX 4090なら1分半ほど、RTX 5080はほぼ2分で480p解像度を5秒出力できます。
RTX 5090の速さを知らなければ、まだまだ十分に使える生成性能でしょう。
1280×704:Wan2.2 720p ベンチマーク
| プロンプト(呪文)設定 | |||
|---|---|---|---|
| Positive | It is a night when the cherry blossoms are falling. Her long hair is blowing wildly in the strong wind. | ||
| Negative | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | ||
| 各種設定 | |||
| 長さ | 81 | ステップ数 | 8(2+2+4) |
| Width | 1280 | Batch count | 1 |
| Height | 704 | Batch size | 1 |
| CFG Scale | 3.5 / 1.0 / 1.0 | ||
| Seed | 20210970 | ||
| 各種モデル (URLはワークフローにまとめ) | |||
| 生成モデル | 「Wan2.2 360p Benchmark」と同じ | ||
- ComfyUI用
ワークフローをダウンロード(.zip)
フルHD解像度へのアップスケーリングでも十分な品質を維持できる、720p相当の解像度(1280 x 704)で、長さ5秒(81フレーム)の動画を生成します。
解像度を大きくするほど二乗に負荷が増え続えるため、おそらく並大抵のグラフィックボードが720pベンチで競争から脱落するはずです。
しかし、この超重量級ベンチマークこそWan2.2公式が推奨する解像度です。公式プロンプトガイドラインや、Lightx2vの公式サンプル動画まで、ほぼすべて720p解像度で出力されています。
Wan2.2の真価を発揮できる解像度がおそらく720pでしょう。
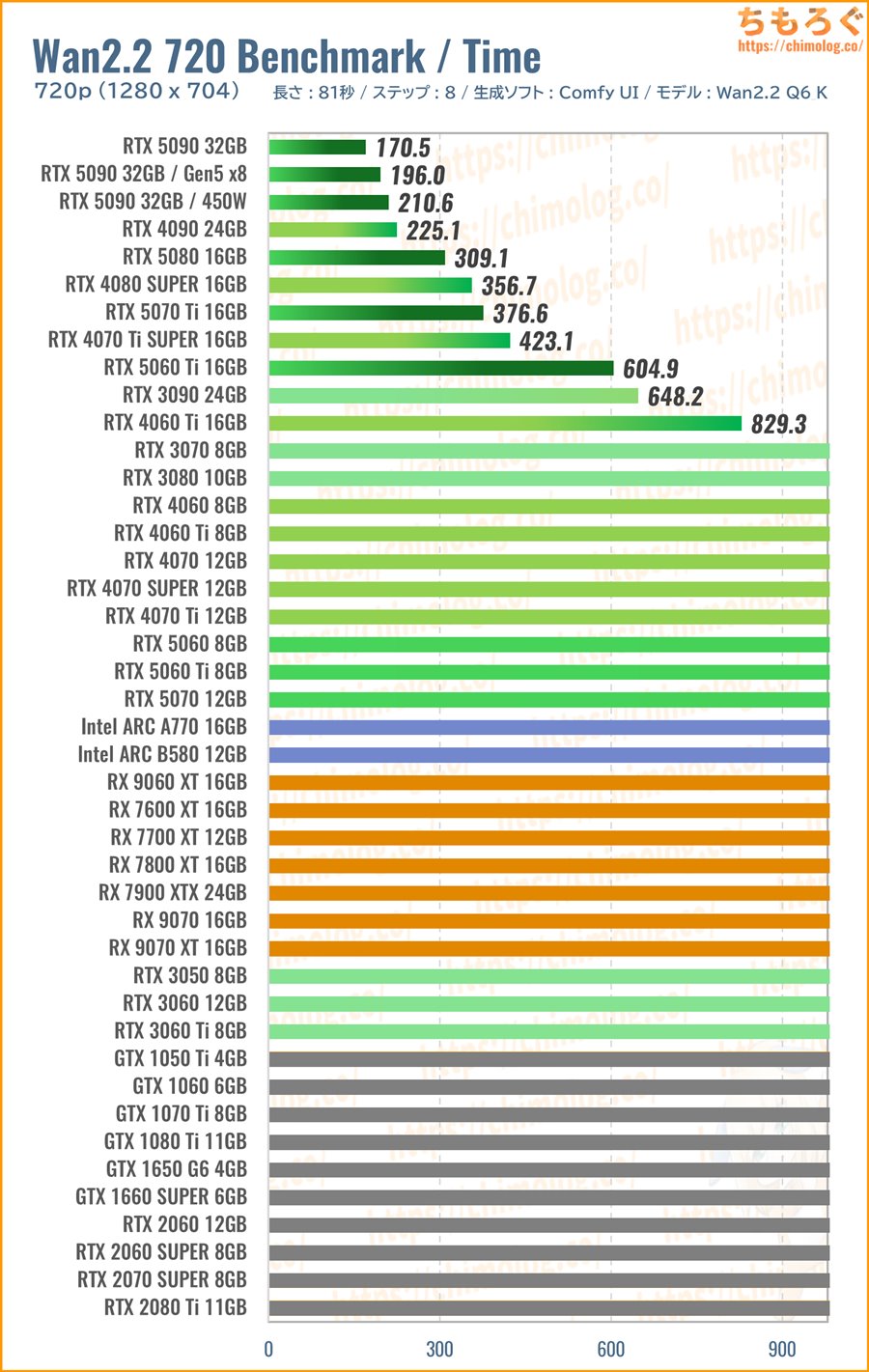
(※クリックすると画像拡大)
生成時のVRAM使用量が一気に跳ね上がり、強力なVRAM管理システムを備える「Kijai」版ワークフローですら、VRAM容量12 GB以下のグラボを救済できません。
VRAM容量が足りていなかった・・・、ただそれだけの理由で大多数のグラボが「Wan2.2 720p」ベンチマークから追い出されました。

(VRAM 12GBはそもそもテストが通らない)
軽量化オプション「Blocks To Swap」を最大値(40)に設定して、分割VAEエンコード+デコードを有効化しても、VRAM容量12 GB以下のグラボは生成中にOoM(Out of Memory Error)で撃沈です。
しいて言えば、PCIe 5.0 x16世代のグラボはスワップ発生時のGPU使用率が約4~5倍(PCIe 4.0比)に改善されているくらいで、やはり後半ステップの生成で止まります。
よって720p解像度を安定して5秒生成できたグラボは、VRAM容量16 GB以上、かつGeForceシリーズに限られます。
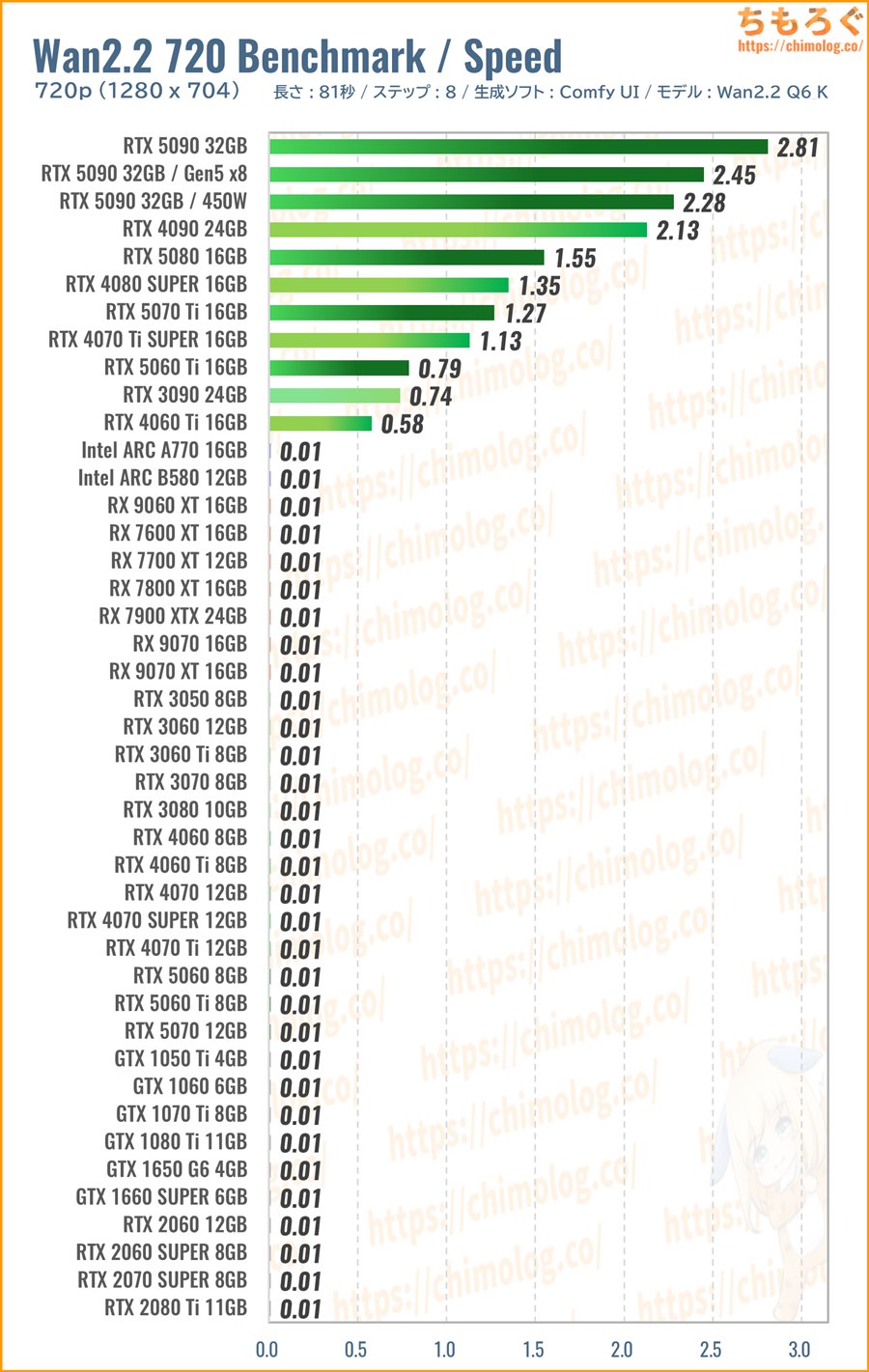
(※クリックすると画像拡大)
生成速度(1分あたりステップ数)を比較します。
検証した全40枚のグラフィックボードで、たった11枚だけ無事に生還します。RadeonとIntel ARCはVRAM容量に関係なく、生成中に処理が止まってしまいます。
Wan2.2を720p解像度で出力するには、最低でもRTX 5060 Ti(16 GB版)が必要です。なにげにRTX 3090に匹敵する速度を出せていますし、新品価格を考慮すれば悪くない選択肢です。
処理速度を要求するなら、予算に応じてRTX 5080やRTX 5070 Tiから。できればRTX 4090以上をおすすめします。
特にRTX 5090は最高です。5秒間の720p解像度を3分切るスピードで生成でき、ギリギリ待っていられる時間に感じます。
サブGPUにRTX 5070あたりを搭載して、動画生成をのんびり待っている間に、もう1台のComfyUIを起動して静止画を生成するマルチタスクもできます。


ネイティブ720p解像度の魅力は超解像 + フレーム補間に対する一定の耐性です。
「SeedVR2」で1.5倍に超解像してから、「RIFE VFI(rife49)」を使って4倍フレーム補間をすると、それなりに見られるレベルのフルHD(60 fps)動画に仕上げられます。
- 360p → 1080p(約3倍):ノイズが目立つ
- 480p → 1080p(約2倍):ノイズがまだ目立つ
- 720p → 1080p(約1.5倍):許容できる画質
360p ~ 480pからフルHDまでアップスケーリングすると非常に粗が目立って実用性に難ありですが、ネイティブ時点で720p以上あれば十分です。
筆者の使い方だと、5秒の動画を12本つなげて1分動画にしてから、SeedVR2 + RIFE VFIワークフローに放り込んで寝てる間に処理させてます。
RTX 5090とメモリ128 GBで、約1000フレームの動画を90分かけてフルHD(60 fps)化できます。Hires.Fix相当の高画質なイラストがヌルヌルと動いて感動が凄いです。
番外編:パラメータ別の比較ベンチマーク
メインメモリ容量ごとに生成時間を比較

Wan2.2の前世代モデル「Wan2.1」が登場したころ、動画生成AIには大量のメインメモリが必要だと話題になっていました。
本当にメインメモリ容量が大量に必要なのか、「RTX 5090」を使ってメモリ容量ごとに生成時間を比較します。
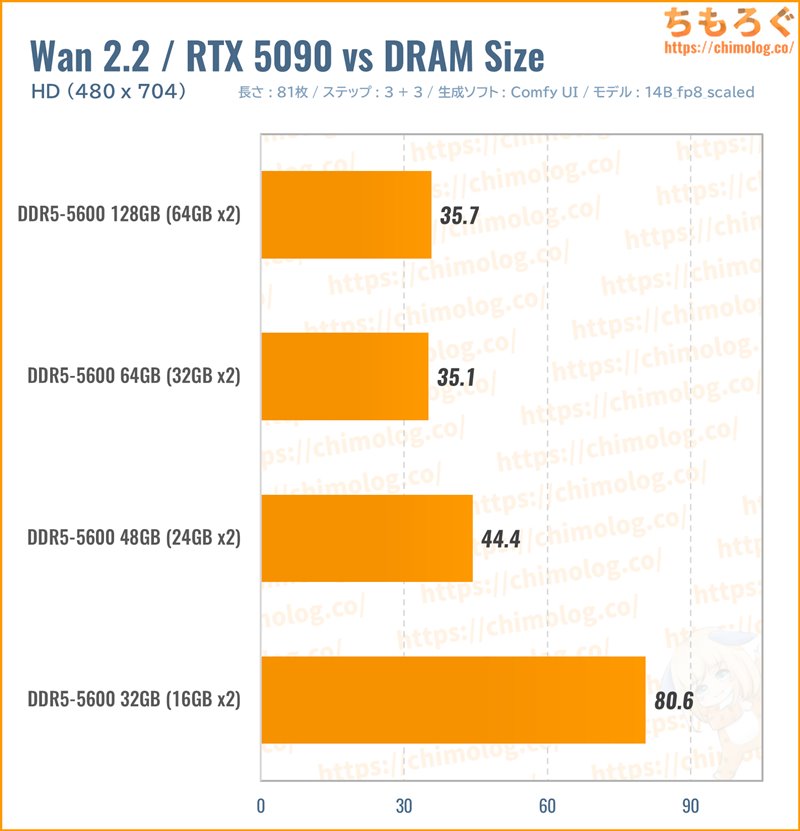
※特にメモリ使用量が多い「Native」版で検証
4パターンで比較した結果、たしかにメインメモリ容量が多いほど生成時間が短縮されています。
- メモリ容量128 GB:約2.3倍
- メモリ容量64 GB:約2.3倍
- メモリ容量48 GB:約1.8倍
- メモリ容量32 GB:-
容量32 GBに対する性能の向上幅を計算すると、容量64 GB以上がおすすめです。メモリ容量を増やしただけで、生成時間が半減します。
メモリ容量を増やすと劇的に生成時間を減らせる理由は「スワップ現象」です。
VRAMに入り切らないデータは、PCIeバスを経由してメインメモリに移動し、メインメモリでも足りなければ共有メモリ(システムSSD)に移動します。
それぞれの移動速度は以下のとおりです。
| エリア | 具体例 | 帯域幅 (移動速度) |
|---|---|---|
| PCIeバス | PCIe 5.0 x16 | 64.0 GB/s |
| PCIe 4.0 x16 | 32.0 GB/s | |
| PCIe 4.0 x8 | 16.0 GB/s | |
| メインメモリ | DDR5-5600 | 69.2 GB/s |
| DDR4-3200 | 33.6 GB/s | |
| 共有メモリ | NVMe SSD(Gen5) | 14.8 GB/s |
| NVMe SSD(Gen4) | 7.4 GB/s | |
| SATA SSD | 0.5 GB/s |
一見するとぶっ飛んだ速度に見えます。
| GPU | VRAM | 帯域幅 |
|---|---|---|
| RTX 5090 | GDDR7 | 1792 GB/s |
| RTX 4090 | GDDR6X | 1008 GB/s |
| RTX 5070 | GDDR7 | 672 GB/s |
| RTX 4070 | GDDR6X | 504 GB/s |
| RTX 3060 12GB | GDDR6 | 360 GB/s |
一方で、VRAM帯域幅は文字どおり桁違いの帯域幅です。
PCIeバスやメインメモリの約5~30倍以上も速く、ましてや共有メモリ(NVMe SSD)と比較してまうと約50~250倍も速いです。
VRAMと比較してメモリの帯域幅が遅すぎるから、メインメモリに漏れると生成時間が一気に低速化します。
メインメモリにすら入り切らず、共有メモリ(NVMe SSD)に漏れた場合は、SSDの寿命(TBW:書き込み保証値)を無駄に浪費するペナルティまで付いてきます。

「動画の解像度」ごとの生成時間を比較
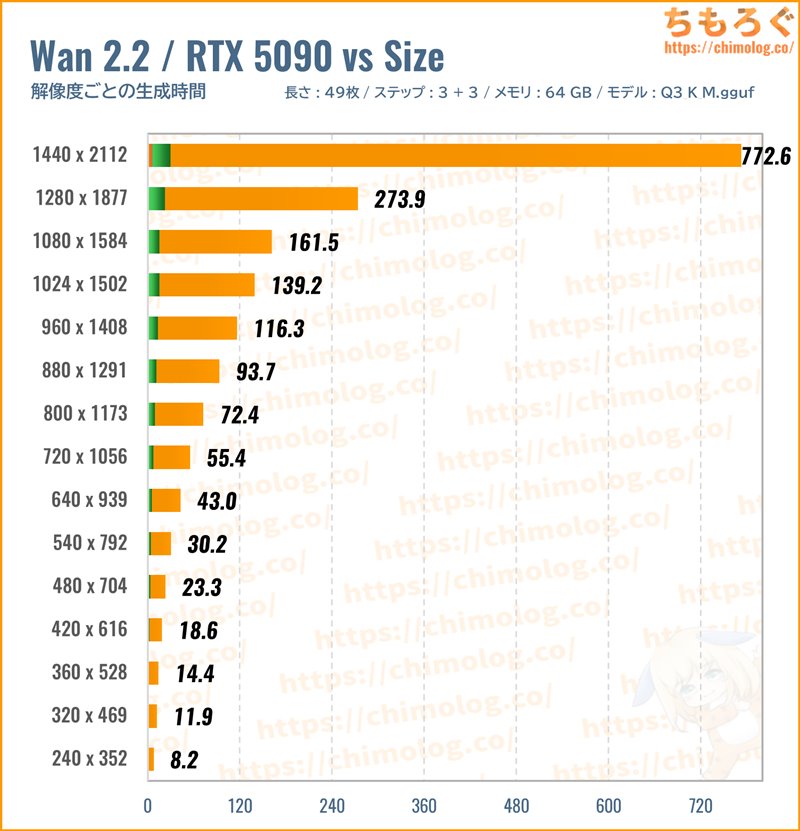
(※クリックでグラフ拡大)
EasyWan22で使われている「Q3_K_M」モデルを使って、生成する動画サイズ(解像度)ごとの生成時間を比較します。
解像度が大きいほど、生成時間がほとんど線形に増えていきます。VRAM容量とメインメモリ容量が足りている限り、生成時間はほぼ線形です。
しかし、フルHD以上(1280 x 1877など)から非線形に生成時間が大幅に増加します。
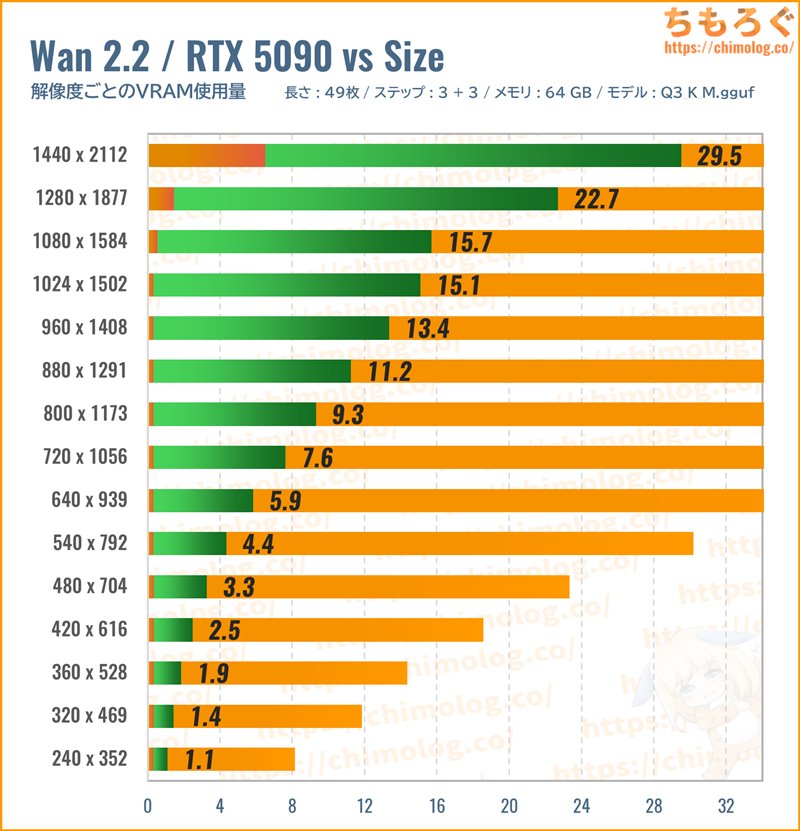
フルHD以上になるとVRAM使用量が大幅に増え、メインメモリ容量が足りず、仕方なく共有メモリ(SSD)を使っているからです(※濃いオレンジ色が共有メモリ使用量)。
メインメモリと比較して共有メモリ(SSD)は途方もなく遅い領域で、大幅なペナルティ(速度低下)を受けます。
ペナルティを受けると大量の待ち時間が発生し、グラボが効率よく仕事できません。結果的にGPU使用率(消費電力)も25~33%程度まで下がっていました。
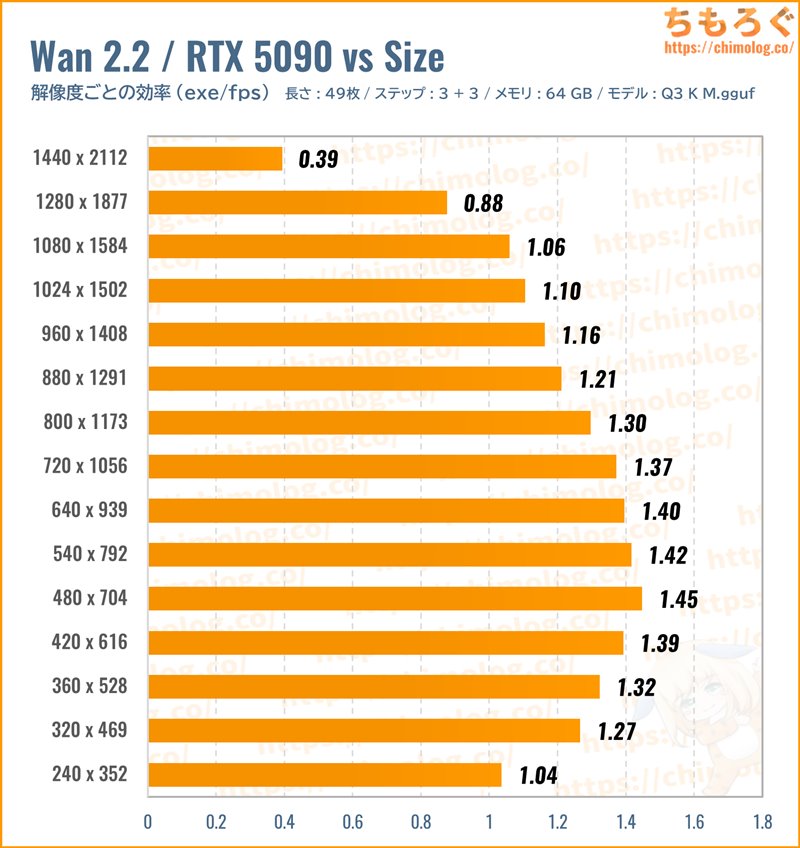
1フレームレートあたりの処理時間(効率)をチェックします。
元画像サイズ(480 x 704)と同じ解像度がもっとも効率よく生成できます。小さすぎると逆に効率は悪化するし、大きすぎると共有メモリのせいで大幅に悪化します。
「動画の長さ」ごとの生成時間を比較
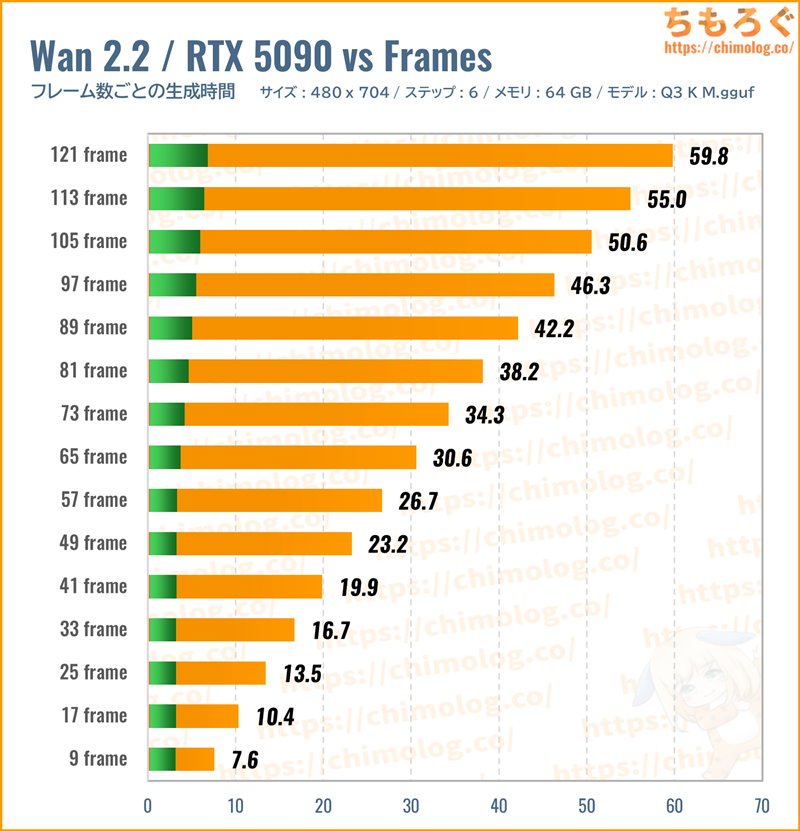
(※クリックでグラフ拡大)
先ほどの検証に引き続き、「Q3_K_M」モデルを使って生成する動画の長さ(フレーム数)ごとの生成時間を比較します。
フレーム数も解像度と同じく、VRAMとメインメモリが足りている限り、生成時間が線形に伸びます。
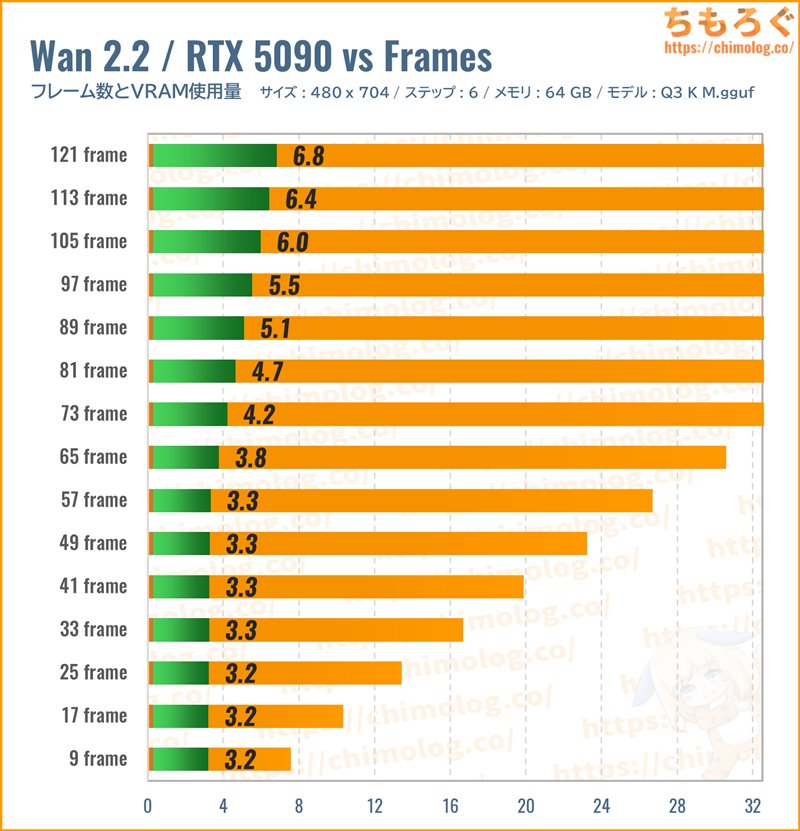
VRAM使用量はかなり興味深いです。
9~57フレーム(0.5~3.5秒)まで、VRAM使用量は約3.3 GB前後からまったく変化せず、73フレーム(4.5秒)から線形にVRAM使用量が増加します。
ただし、Wan2.2の推奨設定は「3~5秒(49~81フレーム)」です。49フレーム未満、81フレーム超過時のVRAM使用量を気にする必要はほとんどないでしょう。
HD相当(480 x 704)なら49フレーム時で約3.3 GB、81フレーム時で約4.7 GB、約1.65倍に増加するとだけ覚えておけば十分です。

1フレームレートあたりの処理時間(効率)をチェックします。
Wan2.2公式が推奨する「3~5秒(49~81フレーム)」がもっとも効率が高いです。
「CFGスケール」ごとの生成時間を比較
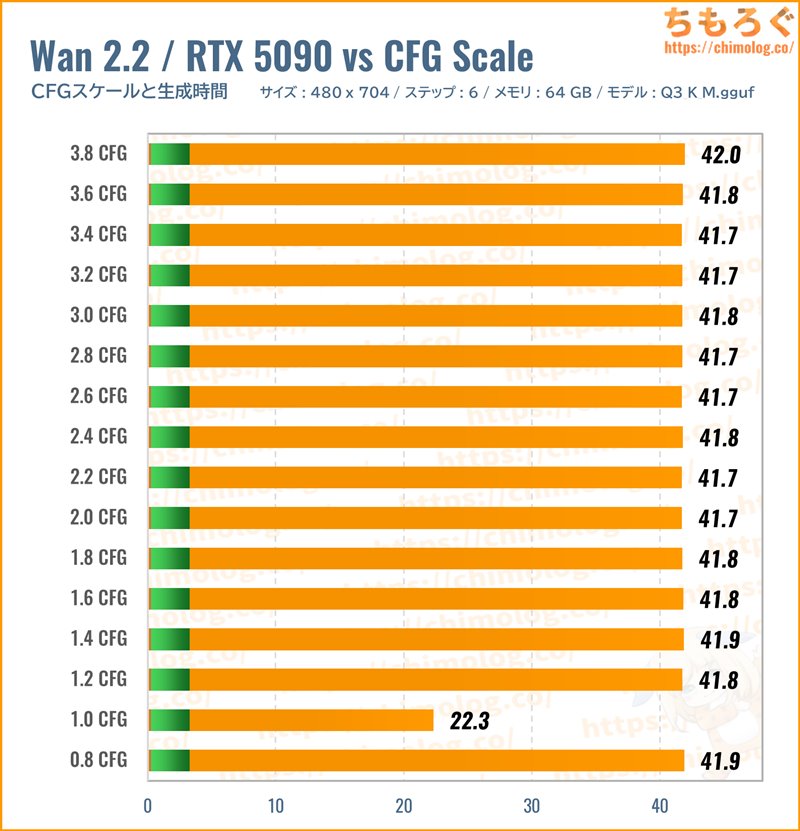
(※クリックでグラフ拡大)
先ほどの検証に引き続き、「Q3_K_M」モデルを使ってCFGスケール(指示強度)ごとの生成時間を比較します。
Wan2.2のCFGスケールに対する挙動はとても不思議です。初期設定「CFG:1.0」だけ高速に動作でき、少しでも1.0をズレると一律2倍に鈍化します。
CFG:1.1や0.9ですら2倍に伸びます。なぜかCFG:1.0に限って動作が速いです。
CFGスケールごとのVRAM使用量に変化なし。CFGスケールを変えても、VRAM使用量は増えも減りもしないです。
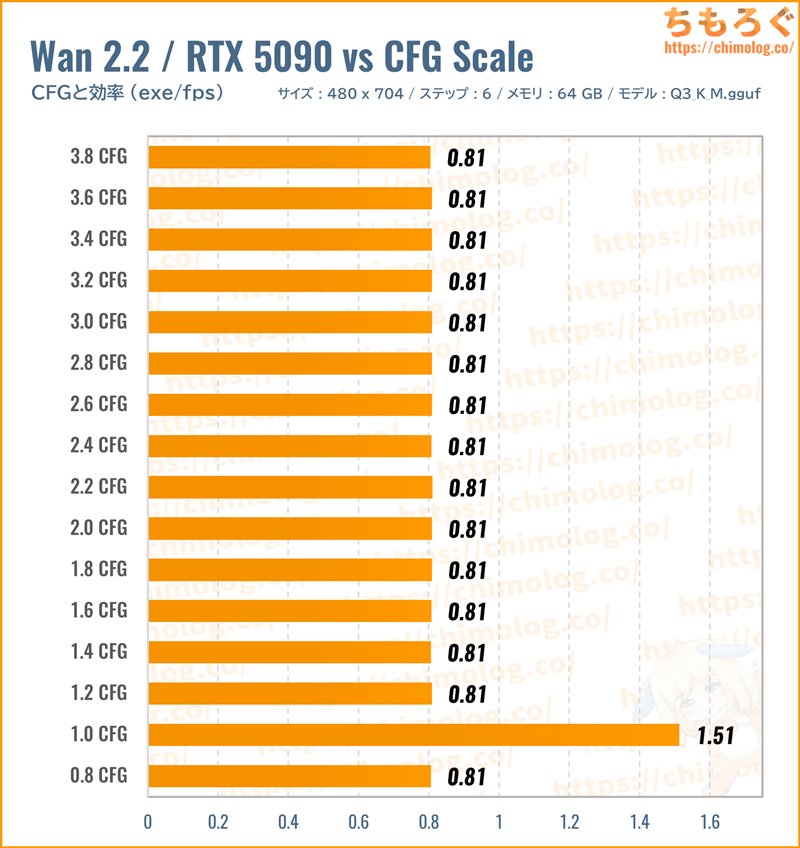
1フレームレートあたりの処理時間(効率)をチェックします。
初期設定「CFG:1.0」が最高効率で、1.0以外だと半減します。速度を重視するならCFG:1.0以外を使わないほうが良いです。
しかし、CFG:2.0~3.5の方が激しく荒ぶる動きを再現しやすく、格段にモーション量が好みです。
High側モデルだけCFG:3.0前後に設定して、Low側モデルをCFG:1.0のまま生成すれば、合計1.5倍の生成時間でモーション量の多い映像を出力できます。
【おまけ】VRAMとメインメモリの関係性
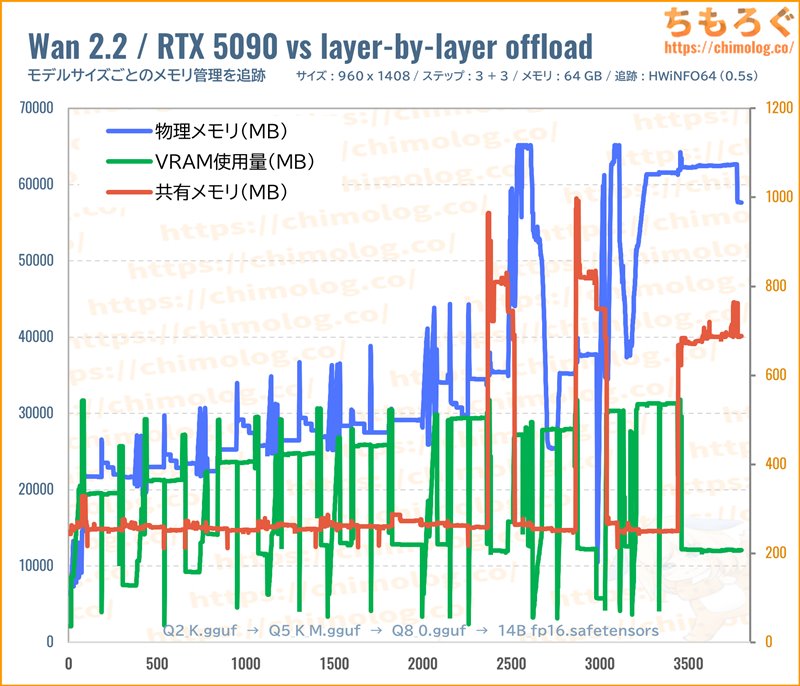
(※詳細な拡大グラフはこちらから)
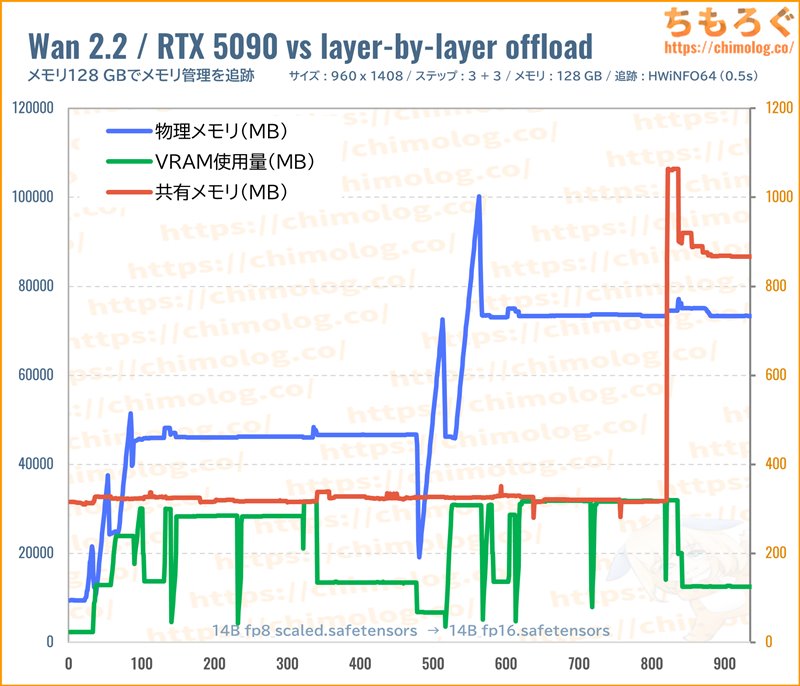
Wan2.2とComfyUIによる、華麗なメモリ管理システムをグラフで確認します。
グラフの左から右に向かうにつれて、モデルサイズが大きいです。最軽量の「Q2_K」からテストを開始して、最後に「14B_fp16」を読み込んでいます。
モデルサイズが巨大になればなるほど、VRAM使用量がじわじわと増加し、メインメモリ使用量も増加する傾向が明らかです。
「Q6_K」版までなら共有メモリをまったく使わず、VRAMとメインメモリだけでほぼやり繰りできています。
しかし「Q8_0」版から最終VAEデコードで目詰まりを起こして、ついに共有メモリ(SSD)を一時的に使い始めます。
「14B_fp8_sacled」と「14B_fp16」も当然ながら目詰まりを起こし、共有メモリ(SSD)を一時的に使っています。
「14B_fp16」に至っては、最終VAEデコードが終わるまでずっと共有メモリに頼りっきりです。VRAMもメインメモリも枯渇したとき、共有メモリがまさに最後の砦です。
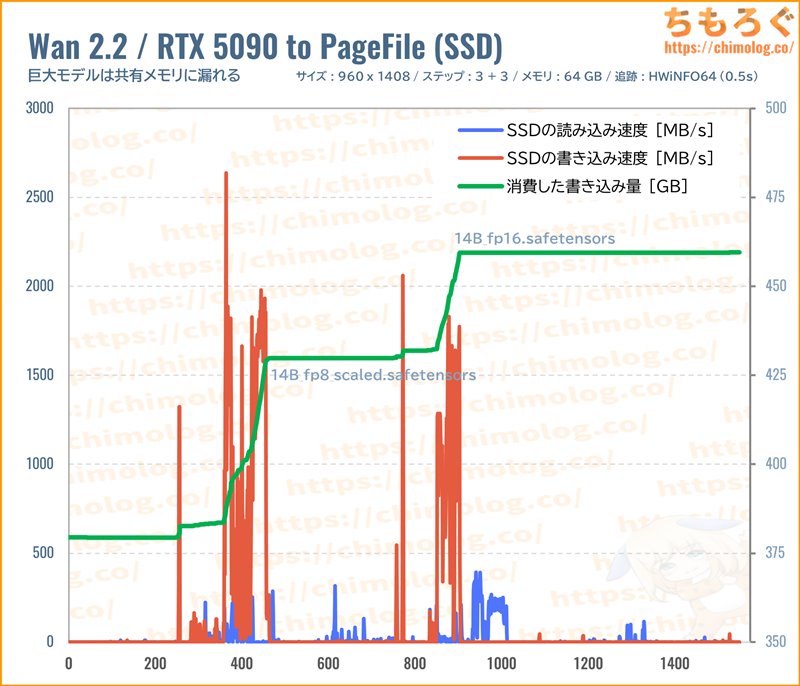
共有メモリを使い続けるデメリットは2点あります。
- 大幅なペナルティ(速度低下)
- SSD書き込み保証値(TBW)の消費
メインメモリに入り切らないデータを、一時的に共有メモリ(SSD)に移すわけで、当然ながらSSDの保証値(TBW)を消費します。
14B級モデルの場合、動画の生成1回あたり約30~50 GBほど消費していました。生成100回なら約3000~4000 GB程度を消費できる計算です。
最近のNVMe SSDなら、容量1 TBモデルで300~600 TBW(= 300,000~600,000 GB相当)です。
1日あたり100生成で約3000~4000 GBを消費するペースであれば、ざっくり150日(5ヶ月)で保証値を使い切れる試算になってしまいます。
では、メモリ容量を64 GBから128 GBに増設して、巨大モデル(14B_fp8_sacled)を再度テストします。
64 GBなら生成1回あたり約30~50 GBも共有メモリ(SSD)を使っていたのに、128 GBに増設すると、まったく共有メモリを使わずに済みます。
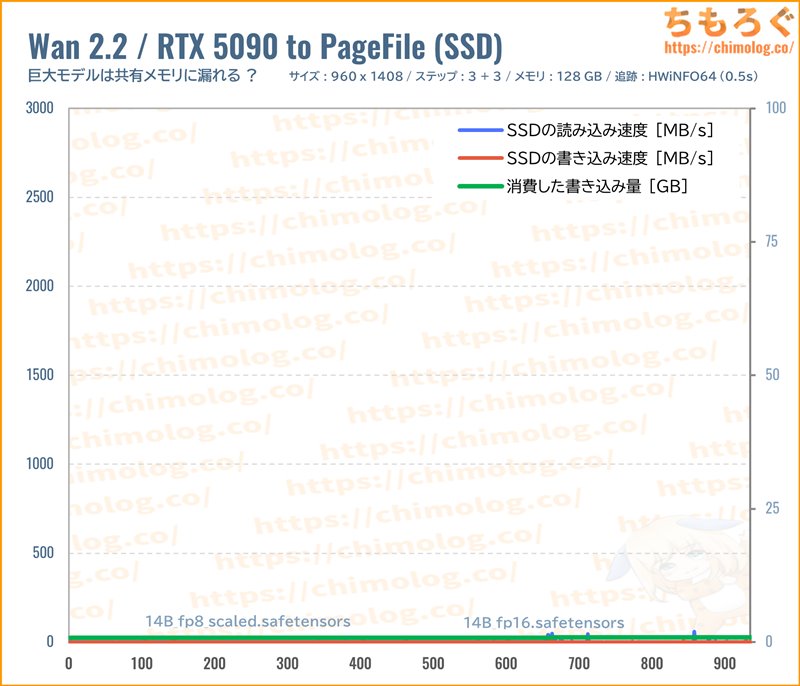
もちろん、SSDの書き込みも一切検出されないです。
SSDは書き込み寿命がありますが、メインメモリ(DRAM)に寿命の概念はほとんど存在しないため、やはりメモリの増設がおすすめです。
まとめ:動画生成AIにおすすめなグラボ【3選】

今回のWan2.2ベンチマーク調査で、「動画生成AIにおすすめなグラボ」がほぼ判明しました。
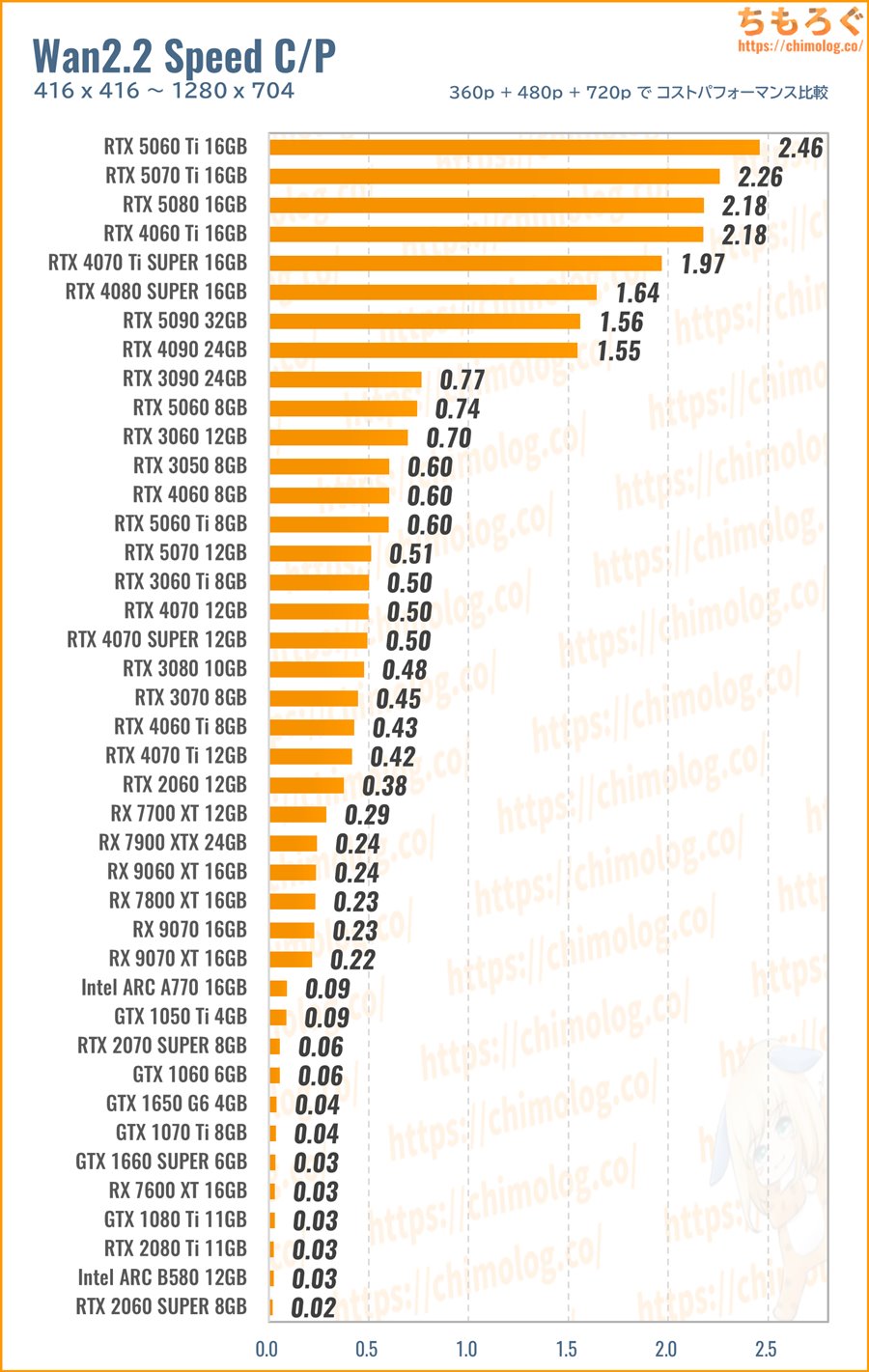
(※クリックすると画像拡大)
生成速度(3つのベンチマーク平均値)に対する、新品価格で求めたコストパフォーマンス比較です。
- 416×416:Wan2.2 360p ベンチマーク
- 800×448:Wan2.2 480p ベンチマーク
- 1280×704:Wan2.2 720p ベンチマーク
以上のベンチマークで取得した「生成速度(it/m)」を、まとめて幾何平均(Geomaen)に変換して、レビュー時点で入手可能な新品価格で割ってコスパを求めます。
- 生成速度の幾何平均 / 新品価格 = コスパ
支払った金額あたりの生成速度が高いグラボほど、コストパフォーマンスが良好です。
VRAM容量が考慮されていないのでは? ・・・もちろん、VRAM容量もすでに織り込み済み。半数以上のグラボが落ちた720pベンチマークも幾何平均の中に含めて、きちんとVRAM容量で足切りしています。
RTX 5060 Ti 16GB:動画生成AI向け入門グラボ


動画生成AIをとりあえず導入してみたい方に、おすすめなグラフィックボードが「RTX 5060 Ti 16GB」です。
約7.5万円台の価格ながら、GDDR7メモリ(448 GB/s)を容量16 GBも搭載しているおかげで、480p解像度や720p解像度の生成が意外と速いです。
720p解像度なら、かつてフラグシップだったRTX 3090に匹敵する生成速度です。
上位グラボと比較して生成速度こそ劣っていても、360~720pまで一通り安定して動作します。新品価格で割ったコストパフォーマンスは最上位クラス。
予算10万円未満で買えるグラボの中で、もっとも動画生成AIに適性があるグラフィックボードと評価してます。

RTX 5070 Ti 16GB:速度と容量のバランスならこれ


RTX 4080 SUPERに迫る生成性能と、高速なGDDR7メモリ(896 GB/s)を容量16 GBも備えるグラボが「RTX 5070 Ti」です。
在庫がかなり安定してきて、今なら約12~13万円台で落ち着いています。それでも価格だけを見るとけっこういい値段してますが、性能とコスパは負けてないです。
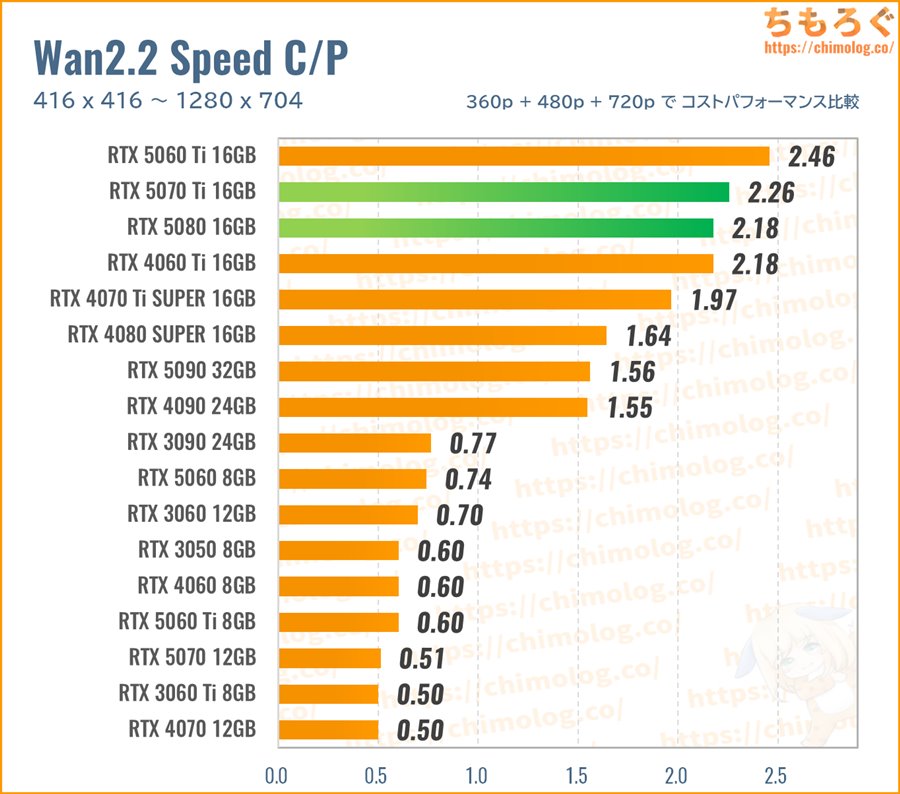
RTX 5060 Tiに対して約1.6~1.7倍の生成速度があり、一方で価格差は約1.7~1.8倍だから意外とコスパも悪くない印象。
VRAM容量もRTX 5060 Tiと同じく16 GBを備え、VRAM帯域幅は約2倍近い896 GB/sまで跳ね上がり、なんとRTX 4080 SUPERに迫る生成速度を出せています。
なお、RTX 5080とほぼ同じコストパフォーマンスですが、どちらを選ぶかは予算次第。少しでもパフォーマンス重視ならRTX 5080を、コスパ重視ならRTX 5070 Tiです。
RTX 5090 32GB:動きのある高解像度な動画生成に


「RTX 5090」は筆者がもっとも気に入っている動画生成AIグラボです。
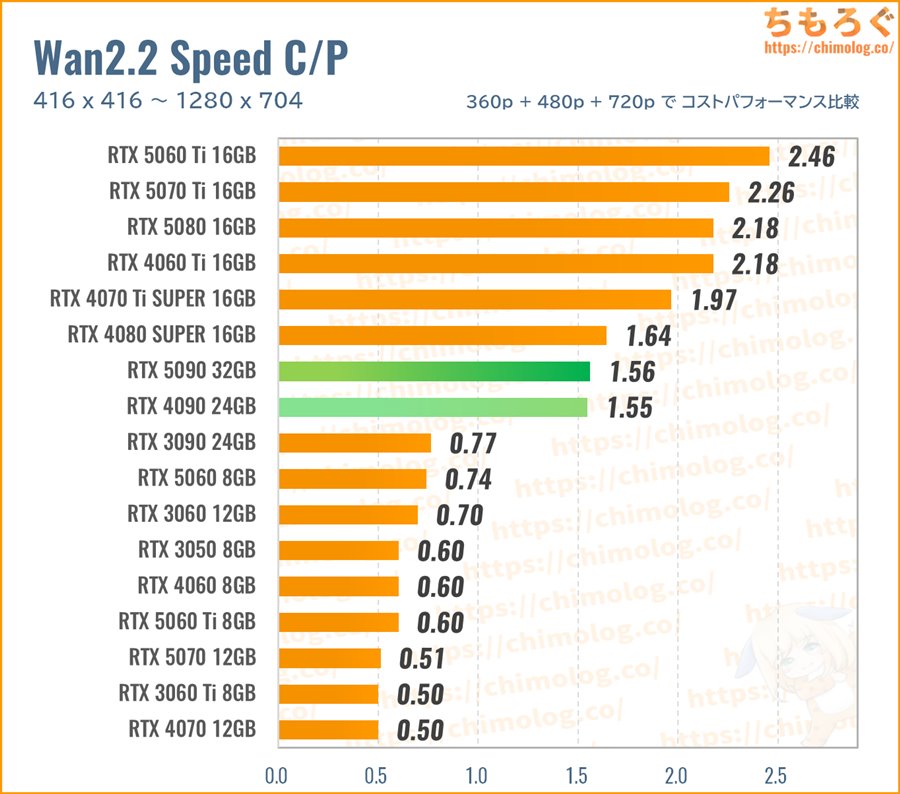
しかし、生成速度あたりのコストパフォーマンスはそれほど高くなく、RTX 4090と誤差程度にとどまります。
割高と言われると確かに割高感を否めないですが、絶対的なパフォーマンスがとにかく速いですし、VRAM容量がなんと32 GBも搭載されています。
VRAM容量が32 GBもあれば、もっと高精度な大容量モデルを収納可能です。たとえば、「14B_fp8_scaled」や「Q8_0.gguf」など、単品で14~15 GBもある巨大モデルをロードできます。
大きいモデルほど高画質、かつモーション量も多いです。同じプロンプトや設定なのに、モデルが大きくなっただけで生成品質が上がります。
単純なコストパフォーマンスだけでRTX 5090を見ると、本当の価値を見誤るリスクが高いです。

RTX 5090はただ速いだけでなく、巨大なVRAMで大きなモデルを扱えるし、そもそも生成が高速だから「高速化LoRA」をあえて使わない選択肢すら出てきます。
高速化LoRAは必要ステップ数を激減させつつ高い品質を維持するとアピールしますが、実際はLoRAを使わずにステップ数でゴリ押しした方が躍動感ある映像が出やすいです。
海外の生成AIコミュニティでも、躍動感あるWan2.2サンプル動画が流れると・・・
などなど、奇をてらうテクニックや複雑なワークフローなんて一切使わず、単に巨大モデルと大量ステップでゴリ押しした例が多いです。
(ちゃんと「抜刀」できたけど・・・切っ先が西洋刀)
つまり、RTX 4090やRTX 5090などフラグシップモデル最大の魅力は、圧倒的なスペックで可能になる「ゴリ押し」に真価があります。
筆者の場合、本記事で配布した3段階ワークフロー(High + High + Low)を合計20~28ステップでネイティブ720pを出力させて、「SeedVR2」でフルHD相当に超解像します。
SeedVR2(7B_fp16)モデルも、アップスケーラーとしては非常識なVRAM使用量と負荷を誇り、RTX 5090じゃないと正直待ってられないです。

以上「【Wan2.2】動画生成AIにおすすめなグラボをゆるく検証【GPU別の生成速度】」でした。
AIイラスト生成におすすめなグラボ

ローカル生成AIユーザーに今も支持されている「SDXL」モデルにおすすめなグラボ解説です。将来的なポテンシャルが高い「Qwen Image」もついでに検証済み。
生成AIタスクにおすすめなBTOパソコン

これからAIイラスト用にパソコンを用意するなら、基本的にBTOパソコンを推奨します。手っ取り早く完成済みかつプロが組み立てたパソコンを入手できます。
メーカー側で互換性を確認している、いわゆる最新パーツで構成されているから、旧世代のパソコン(メモリがDDR3世代)を延命するより安心です。
- 2025/08/10:Wan2.2のGPUベンチマーク結果をアップ
- 2025/08/12:パラメータ別のベンチマーク結果を追加
- 2025/08/28:全ベンチマークを刷新 / コスパ比較を追加(UPDATE !!)












 おすすめゲーミングPC:7選
おすすめゲーミングPC:7選 ゲーミングモニターおすすめ:7選
ゲーミングモニターおすすめ:7選 【PS5】おすすめゲーミングモニター
【PS5】おすすめゲーミングモニター NEXTGEAR 7800X3Dの実機レビュー
NEXTGEAR 7800X3Dの実機レビュー LEVEL∞の実機レビュー
LEVEL∞の実機レビュー GALLERIAの実機レビュー
GALLERIAの実機レビュー 【予算10万円】自作PCプラン解説
【予算10万円】自作PCプラン解説 おすすめグラボ:7選
おすすめグラボ:7選 おすすめのSSD:10選
おすすめのSSD:10選 おすすめの電源ユニット10選
おすすめの電源ユニット10選

 「ドスパラ」でおすすめなゲーミングPC
「ドスパラ」でおすすめなゲーミングPC

 やかもちのTwitterアカ
やかもちのTwitterアカ


あまり詳しくないけどやっぱりそのままcudaで動かせるnvidiaと互換機能を使って動かすAMDでは超えられない壁があるのかな?windows版ROCmでもまるで勝負になってない。
中身がまだROCM 6.5.0rcだから、最適化不足かも?
ROCm 7.x版がリリースされたら性能が上がるかも。RDNA4は静止画なら約3倍(+200%)を出せているらしいです。動画はVAE処理がダメダメすぎるから、あまり伸びない可能性はありますが・・・。
Intel Arcはやらなかったんです?
最近だとIPEX無しでも動かせたりしますが
条件が違いすぎるので参考までに。
ARC B570で試してみました。
ARCシリーズはGGUFで動画生成できない(ComfyUI-GGUFのカスタムノードが対応していない)ので「Wan2_2-I2V-A14B-HIGH(LOW)_fp8_e4m3fn_scaled_KJ.safetensors(各15GB)」で。
VRAMオーバーフローですぐクラッシュしてしまうのでオプションに「–novram」をつけています。309.66秒でした。ちなみにメインメモリは88GBくらい使っています。
購入の参考になる素晴らしい検証ありがとうございます
5090に電力制限(70~80%くらい)かけた場合どのくらいの性能になるかわかりますでしょうか?
買おうかすごい迷っているんですが600Wで動かすのが怖くて踏ん切りが付かなくて
【TGP:575W(100%)】
33.1~35.7秒
【TGP:430W(75%)】
36.1~37.2秒
電力を25%カットしても、わずか4%の鈍化でした。
Wan2.2の構造的にメインメモリとやり取りする頻度が高いため、おそらくPCIe 5.0 x16帯域(32 GT/s)が想像以上に効いている様子です。
それと約18000 CUDAコアの暴力ですね。
検証ありがとうございます。
5090買うことに決めました!
RTX5090を買ってしまったので、もう何も悩まなくて済むぜぇ!あとはComfyUI覚えるだけだな!(最難関)
ComfyUIは慣れると最高です。
筆者はRTX 50早期対応のためにA1111 web UIからComfyUIに乗り換えてからドハマリしてしまい、もう二度とWeb UI系列に戻れそうにないです。
昔 弾けもしないのに買って遊んだアナログシンセサイザー思い出しますw 今はまだ公式のWFとか個人が公開してくれてるWFから弄ってるところですが、あの「画像をポイッとな!」でWF再現してくれる機能考えた人天才だと思う。
この検証、動画生成に興味ある人にはめちゃめちゃ需要あると思いますよ!
私は5070tiユーザーですが、他グラボとの比較が各種AIコミュニティの伝聞しかなかったので、非常に参考になりました!
万一、DGX Sparkもご購入予定がありましたら比較検討に加えていただけると幸いです!
結局NVIDIAの独擅場ですね
しかしIntelもAIに関しては結構優秀という噂も聞きますので
B580とその後に噂されているVRAM48GBバージョンも気になってしまいます。
VRAM大幅増量版の「Arc B60」を出すらしいですね。
B60は当然持ってないので、手持ちのB580で検証してみます。
横から失礼します
せっかくArc B580を買っていらっしゃるのですから、B580の総合レビュー記事も見てみたいです
文中の「共有メモリ」は、「仮想メモリ」の誤りかと思われます。
共有メモリは、例えば複数の同じプログラムを動かす時に同じメモリ領域を使い回すとか、プログラム間でデータをやり取りする等に使う物ですね。
タスクマネージャだと「共有ワーキングセット」で表示されます。
リソースモニタで、ハード フォールト/秒ってのが有りますが、ソレがSSDやHDD上のスワップorページファイル関連の数値になります。
タスクマネージャだと、ページ フォールト(差分の同デルタ)です。
タスクマネージャのパフォーマンスタブのメモリだと、「コミット済み」の分子側が急激に増える状態がRAM不足になってページアウトしている状態です。
※アプリ起動後のアイドル時にゆっくり増える事も有りますが、
RAM不足時に備えて、予めページファイルに書き出しておく機能(※※)が原因で、実際はRAM不足ではない場合も有ります。
※※予めページファイルに書き出しておけば、不足してから実際に書き出してRAMを確保するよりも快適になる事が多い。
大幅なペナルティが発生したとき、急増していたパラメータ名称をそのまま使っています。
タスクマネージャーなら「共有GPUメモリ」、HWINFO64なら「GPU D3D Memory Dynamic [MB]」ですね。ここが少しでも増えると、めちゃくちゃ速度が鈍化するから、とりあえずここを共有メモリと呼んでいます。
仮想メモリは「Virtual Memory Committed [MB]」で確認できるのですが、ぼくにとって理解が難しいパラメータだったので無視してます。
ぼくが見てるのは、
1. 共有メモリの増加
2. 生成時間の鈍化
以上2点だけです。
>共有GPUメモリ
GPUを略されていたのですね。
共有メモリと共有GPUメモリは、アイホンとアイフォーン位別物なので当方が勘違いしてしまいました。
申し訳ございません。
タスクマネージャのGPUだと、専用GPUメモリがVRAMの事で、共有GPUメモリがRAMの事になります。
また、Windows10/11の共有GPUメモリは最大でRAM搭載量の半分という制限が有ります。
その為、搭載RAM量がそもそも動くか動かないかの境界線になりえます。
また、共有GPUメモリをどう使うかはドライバー次第で、GeForceならNVIDIAコントロールパネルのCUDA – システムメモリーフォールバックポリシーで変更可能です。
デフォルトは多分共有GPUメモリを使うフォールバックを優先する設定のはず。
フォールバックして共有GPUメモリを使うという事はVRAMが不足しており、ドライバーがVRAM不足を検知してVRAMからRAMへ内容を転送し、必要な部分をRAMからVRAMへ転送する必要が有ります。
このコストが結構高めなので性能は結構落ちます。
特に計算に必要なメモリが連続しておらず分散してると転送が頻発するので滅茶苦茶遅くなります。
※故にフォールバックをオフにしてメモリ不足で止まっても良いから、性能優先させる設定が有る訳ですし、
CUDAプログラムやモデル、ドライバーの最適化等で上手くVRAMとRAM間の転送回数を減らせれば劇的に高速化します。
そして、共有GPUメモリは、使えば使うほどプログラムやOSが自身の実行やキャッシュ等として使えるRAMが減ります。
つまり、VRAM大量使用時に起きる現象としては、
VRAMが不足(タスクマネージャのGPUの専用GPUメモリの使用量が増え満タンに)
→ドライバーがVRAMから共有GPUメモリ(RAM)へ退避(共有GPUメモリの使用量が増える)
→OSやプログラム実行用に使える物理RAM空間が減少(タスクマネージャのメモリの使用量が増える)
ここまでで済めばSSDへのページアウト等はほぼ起きず極めて極端な性能低下はしないで済むかもしれません。
しかし、そのまま状況が悪化すると、
→プログラム実行用のRAMが不足(タスクマネージャのメモリ使用量が満タン)
→ファイルキャッシュの破棄やSSD等へ強制退避が頻発(タスクマネージャのメモリのコミット済みの分子側が増えたり、SSDの読み書きが増加)
という流れになります。
極端にプログラム実行用のRAMが減ればそもそもGPUへ命令を送り込む、生成AIプログラムの実行がそもそもスムーズに出来なくなり、GPUに食わせる入力と出力が一時的に止まり、GPUが完全に遊ぶ現象が起きます。
生成AIのプログラム自身もモデルのキャッシュの為にプログラム実行用のRAMを消費していると思いますが、その領域がSSD等にページアウトされてしまうと致命的な性能低下になります。
タスクマネージャのGPUの項目で「共有GPUメモリ」と記載されているからでは?
3Dゲームには興味ないけどAIのためにグラボ買おうか考えてるので、今後もこういう記事を期待してます
画像生成の比較と違って使用するモデルがVRAM量で違っているのに注意ですね。
32Gと8Gでモデルの大きさを合わせるのは実用からかけ離れるので納得ですが、
VRAM量が違えば単純な性能比較表にはならない。
それでも4年前の3060にはるかに及ばないRadeonはインパクトありますね
モデルサイズの違いをけっこう突っ込まれたので、モデルサイズ別のベンチを追加してみました。
結局のところ、VAE処理含めてVRAM + DRAMに収納できるなら、モデルによる顕著な性能変化は確認できないです。EasyWan22を参考にして、あえて余裕のあるモデルサイズを選ぶ判断は、そこまで間違ってなかったかな?・・・と個人的に思ってます。
噂される5070ti superだとVRAM24GBになるので新たな決定版になりそうですね
現状ではGPUの処理性能よりメモリスワップによるボトルネックの方が重大なので
結局VRAMが大事だそうよ、5080ちゃん…
毎回80番台は不遇ですよね。あとから「80 Ti」や「80 SUPER」を出す余裕を残すために、最初から本気を出せない大人の事情でいつも不遇です。
4080と4080superはほとんど変わらなかったですけどね。
80と70tiの差が一番少ないことが4070tisからの80微妙感の元ですが、速度差はキッチリ開いてます。
ですから5070tisuper16GB据え置きとかやめてね革ジャン
3080や5070にてVRAM容量を超えた時にどう変化するのか、ギリギリ可能な範囲がどんなものか。
ここらへんが知りたく思います。
特に5070がゲーミングで実用的であり5060Tiの16GBが何故か執拗に勧められる所ですね。
初回プリロード(Highモデルの読み込み)に耐えられれば、あとはメモリ容量の大盛りでけっこうスムーズに動くと分かりました。
VRAM:12 GBなら
・Q4_K_M.gguf:480 x 704程度
・Q3_K_M.gguf:640 x 939程度
あたりが、VRAM容量から逆算できる目安となります(5秒 = 81 frameを想定)。
※メモリ容量は64 ~ 96 GBを推奨
Thank you for your test
この128GBメモリってX670Eでも動くんですね
crucialの互換性チェックでは 、殆どのX670Eマザーボードは互換性無し的な表示をされてるから驚きです
Asrockのx670e steel legendでも動く場合があるんでしょうか?
CPUが9000番台じゃないとダメとかあるんですかね?
メモリを交換して、一番最初の起動時のみ、約10~15分くらい待たされます。
2回目以降はスムーズに起動できますし、動作も非常に安定しています。ただ、他のコメントにあるとおりRyzen 9000シリーズ推奨です。7000シリーズよりCPU内蔵メモコンの出来が良いです。
少し前までX670E STEEL LEGEND使ってました。Ryzen7900でTEAMってブランド?の32GBx4が動いてましたが、5600Mhzを4000まで落とす必要がありました。ちょっと綱渡り感ですね。因みに32GBx2なら6000まで上げても平気でした。
まず貴重なベンチマーク結果ありがとうございました。
ただ、VRAM容量ごとにアウトプット品質が異なるモデルを使用して比較するのは、
画像生成で異なる解像度で生成した結果を比較するような違和感を感じます。
(実際使う場合を考慮した条件というのも理解できます。)
例えばBlockToSwapを使えば低VRAMでも高容量モデルを動かせるので、
共通のモデルを使用して、VRAM容量ごと最速になるBlockToSwapを設定することで、
アウトプット品質は同じで、VRAM容量による影響も含めた生成時間を比較できる
ベンチマーク結果が得られるのではないかと思います。
次回ベンチマークする機会がありましたら、ご検討いただけると幸いです。
一応、ベンチマークの検討にあたって、EasyWan22でBlockToSwapを使ってみたのですが。数値に関係なく、VRAM使用量と生成時間がまったく変化しなかったです。
今ならちゃんと動くのかな・・・
売れ筋のRTX 5070あたりを使って、BlockToSwap追試してみます。
【8/13 04:00】
追試しました。
メモリ容量64 GBなら、Q8_0.gguf以上でBlockToSwapに一定の優位性があります。共有メモリの使用量を見ながら、ギリギリ共有メモリに漏れない比率(0~40)を見つけ出す手間はありますが、確かに動きますね。
一方でメモリ容量128 GBなら、14B_fp8ですらBlockToSwapに目立った優位性はありません。ComfyUI公式ワークフローですんなりVAEも通ってしまい、拍子抜けです。ざっくり74 GBもメモリを消費していたから、VRAM 12GBならメモリ96 GB以上で大型モデルを動かせます。
ベンチマーク結果はグラフ整理中です。記事の内容が肥大化してしまったので、たぶん別記事にあらためてアップします。
小生の戯言にお付き合いいただき、早々の追試の実施ありがとございました。
ベンチマーク結果を楽しみに待たせていただきます。
自分のPCでベンチマークの再現しようとしまして用意されていたjsonファイルを開いてみました。
開いたテンプレートに対するVAE,lora,modelがダウンロードされずエラーが排出されて、足りない部分を手動でダウンロードをしなければならない状態なんですがこれってどういう状況なんですかね?
ComfyUI-Managerが導入されていれば足りないモデルなどはComfyUI-Managerが持ってきてくれるはずですが・・・
> 足りないモデルなどはComfyUI-Managerが持ってきてくれるはずですが・・・
そのような仕様があるとは、知らなかったです。
Managerは足りないカスタムノードやモデルを教えてくれるだけで、自動ダウンロード機能はもともと無かった気がします。
ベンチマークで使っている各種モデルのURLをまとめました。
【量子化モデル】
・https://huggingface.co/QuantStack/Wan2.2-I2V-A14B-GGUF/tree/main
・https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main
※I2V = 画像から動画 / T2V = テキストから動画
【テキストエンコーダー】
・https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
※fp8版を使ってます
【VAE】
・https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
※Wan2.2は2.1用VAEでOK
【高速化LoRA】
・https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Wan22-Lightning
※I2V = 画像から動画 / T2V = テキストから動画
>Managerは足りないカスタムノードやモデルを教えてくれるだけで・・・
jsonファイルを開いたときに足りないモデルなどがあれば、Managerがこのモデルなんかが足りないけどダウンロードする?的な画面を出してそのままダウンロードできます。
その画面が出なかったのはおそらくModel Manager上に対象のモデルが存在していなかったことが原因だと思います。
jsonファイル上のVAEとコメントに添付されたVAEが異なったので以下のURLから同名のVAEを持ってきました。
https://huggingface.co/Kijai/WanVideo_comfy/tree/main
ダウンロードできるファイルが多いので対象のVAEが埋もれています。
ページ下部のLoad more filesをクリックして展開してください。
“Wan2_1_VAE_bf16.safetensors”をページ内検索するのが早いです。
各種モデルのURLをまとめていただきありがとうございます。
自分はカジュアル層なのでbilibiliなどでまとめてパッケージで持ってくる方法が主流なんですよね。
直接必要なモデルを探してくるのは得意ではないので助かりました。
記事と同じ動画が作成できたのでおそらくあっていると思われますが、上記のVAEがベンチマークで使用したVAEであっていますかね?
この記事を見てメインメモリを32GBにしたのを後悔…動画生成じゃなくても32GBだとキツイですかね?
普通の静止画(SDXLモデル)はメモリ32 GBで大丈夫です。動画(Wan2.2)は少なくとも64 GB以上欲しいですね。
求めていた検証です!当方感激しております( ;∀;)
メインメモリ64GBもあれば良いと思っていたのですが、生成時間とSSDの寿命を鑑みるに128GBは積んだ方が賢明なんですね
そこでお尋ねしたいのですが、動画生成AI用にRTX5090かRTX4090を買うかで迷っております
正確にはRTX5090か、RTX4090もしくはVRAM24GB以上になるらしいRTX5080S or 5070TiS で悩んでいる状態です。
なぜ最高性能の5090にしないか?なのですが、やはりかなりの頻度で報告される溶解問題(燃焼問題?)が心配で購入に踏み切れません。
ケーブルの熱問題であれば電源ユニット、ASRockのPhantom GamingやTAICHI TC-1300Tで一応は対策できると考えて購入に踏み切ろうとしていた矢先
下記URLのような、VRM周りから火の手が挙がったとの悪い知らせが届いてしまい、立ち往生しております。
https://g-pc.info/archives/42113/
ただ、省電力と安定動作のためにアンダーボルト設定で動作させていた・・・・というユーザー側の運用方法も気になるところではあります。
つきましてはRTX5090を2台以上所持しているやかもち様にRTX5090の所感をお聞きしたいのです。
RTX4090に戻れないほど快適なのかなと…。
店頭で中古ではありますが30万円を切っていて動作期間が半年もないMSI製RTX4090を目撃してしまい、こちらにしようかとかなり、とても迷っております。
長文失礼いたしました。
「かなりの頻度で報告される」のは欲しいけど買えない人たちの妬みで増幅されてる面もあるとは思う。ただ今回はケーブルじゃなくグラボ基板上の電源回路からって言うのがちょっと怖いかも。私のもZOTACだもんよ。あとグラボの設計ってメーカによって大きく違うものなのかな?
ZOTAC製5090、実は当方でも当該製品の購入を検討しておりました。
その最中、例の事故が飛び込んできまして……仮に購入していたら、
ZOTACに問い合わせてVRM周りとサーマルパッドを確認してもらうように現物送付しちゃいますね…(;一_一)
設計はメーカー事にだいぶ違うのではないかと私は思います。
ロン毛……ではなく、Gamers Nexus の動画を拝見しているとだいぶ違いが見受けられるからです。
そして私はだいたいGIGABYTEのGPUを買っています。
理由は保証期間が長いことと、気の所為なのかもしれませんがGIGABYTE製のGPUはなぜかコイル鳴きが一度もなかったからです。(人によってはどうでも良いことかも)
それぐらいメーカーによって差があるのではないかと。
【5090の溶融リスクについて】
溶融の原因は、おそらく設計マージンの少なさだと推測されています。
改良版の12V-2×6コネクタですと、定格660 Wを前提に設計されていますが、RTX 5090の定格は575 Wです。マージンが約13%しかないため、経年劣化の考慮が甘いとの指摘が多いです。
というわけで、溶融リスクを抑えるならTGP制限(Power Limit)が手っ取り早いです。
・Windowsタスクスケジューラを用いたGPUの電力制限
バッチファイルにnvidia-smiコマンドを入れて、タスクスケジューラでPC起動時に自動適用できます。「set UPPER_LIMIT_W=450」なら、450Wに制限されます。
動画生成の場合
・PL 100%:速度100%
・PL 80%:速度97%(-3%)
・PL 75%:速度96%(-4%)
制限をかけても、速度劣化はわずかです。RTX 4090(450W)より速いです。
ぼくはソフト経由の制限に若干の不信感があるので、このように接続して、物理的に450W制限をかけています(5090搭載メイン機の実機写真です)。
【5090の動画生成における使用感】
とにかく生成が速いです。RTX 4090比で約1.5~1.6倍ほどの速度が出るため、体感できるレベルで待ち時間が短く感じます。
しかし、待ち時間の捉え方は運用次第ですね。
ぼくは画面の前で次から次へと手作業で動画のつづきを生成して繋げていく地味なワークフローを採用している都合上、生成時間の速さが重要です。
VRAMに余裕があるから、Wan2.2 → SDXL → Wan2.2 →・・・を行き来するマルチタスクも1台でこなせて便利です。
逆に、自動化できるワークフローなら、RTX 4090でも特に不便しないと思います。
今までSDXLで作ってきた静止画たちを、まとめて動画化する使い方であれば、「EasyWan22」の自動化プラグインに任せる方法もあります。
自動化だから寝ている間に終わってしまい、5090の速度に価値を見いだせないと思います。
・手動、手作業タイプ → RTX 5090
・自動化が多いかも → RTX 4090
こんな感じですね。
お返事ありがとうございます。
溶融リスクの回避方法、目からウロコでした。
アンダーボルト設定は頭にあったのですがメーカー保証対象外となる可能性もあるため
どーしたら良いかと思っていたところ、添付頂いた写真を拝見し、その手があったのかと膝を打ちました。
コレは良い考えですね。
5090の動画生成における使用感についてなのですが、
4090とも比較していただいたおかげでとても参考になりました。
5090であれば「Wan2.2 → SDXL → Wan2.2 →・・・を行き来するマルチタスクも1台でこなせて便利です。」とのことで、私が理想としている工程で羨ましいです。
おっしゃられていた通りRTX 50シリーズとWan2.2のMoE方式の相性の良さが光っていますねー。
将来的には自動化したワークフローで済ませたいと考えてはいるのですが、
今は試行錯誤の最中であるため、5090のような圧倒的な処理能力が必要なのです。
そこで一つ思ったのですが、AMDのRadeon AI PRO R9700はどうなのでしょう。
マルチGPUに対応しているため、速度を犠牲にして品質を重視……、
VRAMを盛れるこちらの選択肢もありなのかなと思えてきました。
おまけの項目で提示されていた「モデルサイズと生成品質の違い」が決定的です。
個人的にはおまけどころか、こちらのサンプル動画のおかげでVRAMの重要度を理解できたからです。感謝しかありません。
特に5090ですと綺麗に整った前髪がQ3_K_M版でガビガビになってしまうところが悲し過ぎました(ToT)
なので、VRAM32GBのRadeon AI PRO R9700ならば5090を購入できる金額でおよそ2台買えなくもなさそうなのでコストパフォーマンスが良いと思うところ。
しかしCUDAの壁、そしてメモリ帯域幅:640 GB/sという性能が立ち塞がっていますね。
さらに純粋なVRAM64GBのGPUと比べて、マルチGPUの2スロットはどこまで処理速度が低下するのかわからないところ。
ROCm 7 が早くリリースされてほしいです。
コスト的に今は4090を購入して、Radeon AI PRO R9700のベンチマークとROCm 7のリリースを待つことに落ち着きそうです。
そこまで待ってRadeonが開花しないのなら、ASUS ROG Astral RTX5090BTF仕様ですね。
大変参考になる検証をありがとうございます。
1点、CFG scale と生成時間についてですが、これは CFG scale の仕様によるものだと思います。
– Conditioning: Positive Prompt で生成される画像
– Unconditioning: Negative Prompt で生成される画像
実際の生成画像 = Unconditioning + (Conditioning − Unconditioning) × CFG scale
CFG scale が 1 の場合は、Unconditioning が打ち消されて無くなるので、生成時間は単純に半分になります。この場合、 Negative Prompt は効かなくなります。
https://note.com/ai_image_journey/n/n752bf830b745
LCMとかの頃に低cfg設定が流行って、理論上はcfg=1.0ならnegative promptが差引ゼロだからと省略が組み込まれた結果短縮されるんでしたっけ、組み込まれてない系列もあってそっちは短縮なしとか(多分純正SDwebui)。
更に他のcfg(automaticCFGとか)を利用してcfg=1.0の高速でも擬似ネガティブプロンプトと綺麗な絵をってカスタムノードも登場してるとはComfyUIも奥が深い…
https://github.com/Extraltodeus/Uncond-Zero-for-ComfyUI
5090は欲しいけど(経年劣化で)溶けるリスクが怖い・・・5080、5070のSuperが出てきたら値段次第で・・・でもやっぱ5090なんだろうね、何やるにしてもVRAMはやっぱり20GB以上欲しいよなぁ
有益記事すぎる ありがたい
生成AI向けRTX5090搭載btoでもしおすすめがありましたら教えて頂きたいです
セール中でスペックの割に価格が安め。
カスタマイズでメモリ128 GBに変更可。
費用が+49000円かかりますが、これはクロックと安定性を重視して「すでに入ってる2本をまるごと交換」するからで、自分で交換するより5000~6000円ほど安いです。
※2本に2本を足す4枚組は互換性の観点で難易度がやや上がるので推奨しません。
ゲーム性能を重視しない場合、Intel Core Ultraモデルもあり。
こちらは標準搭載のマザーボードがけっこう豪華で、M.2スロットが空き2本です。AI生成はLoRAやモデルを保存してるだけでTB単位まで膨れ上がるから、拡張性はあった方があとあと便利です。
こちらもメモリ128 GBに変更可。
・32GB x4:+39600円
・64GB x2:+61600円
2枚組128GBがちょっと高めで、自分でやる場合より5000~6000円盛られています。予算全体から見て微々たる差と見るかどうか・・・?ですね。
お忙しいところご回答ありがとうございます。参考にさせて頂きました!
お礼遅れ申し訳ありません。
こんにちは!お忙しいところ失礼します。TCL 27R73Q モニターをレビューするご予定はありますでしょうか?とても良いミニLEDのようですが、まだほとんどレビューがないようです。
追伸:文法の間違いがあればすみません。日本語が話せないため、自動翻訳を使っています。
TCL 27R73Qは日本国内でニーズが少ないです。
+10000円で買える「27R83U(4K)」を選ばれる方が多く、27R73Qは注目されてません。申し訳ありませんが、現時点でレビューをする予定はないです。
価格があと1.5万円くらい安くなればチャンスがあります。
大変参考になる検証ありがとうございます!
比較検証希望があります。
生成AIはグラボでほとんどの処理を行いますが、CPUの世代や性能をどこまで下げたらボトルネックが発生するかも知りたいです。
例えば私は今core i5 -8400にRTX3060 12GBを組み合わせていますが、RTX 5090又はRTX5070tiに換装した場合性能の低下がどれほどになるか気になります。
勝手なお願い失礼しました。
相変わらず5080は散々ですね・・・
私の5080ちゃんに救いはないんですか・・・
ゆるくって言う割にあんまりゆるくないな…
動画生成のベンチマークはあまり見ないので非常に有益で助かります
確かにグラボに8ピン3本までが安全面ではいい感じはする。
この大きさのモノに500W以上とか危険を感じるな。
PCWatchの記事に48V供給くらいで造っときゃ良かったんじゃないかと話がある。
最近ネットでTVの映像の出し方のをチラ見してなんだかマイクロLEDとか言うのが出てきました。
なんでもマイクロ小さいLEDでRGB直接出してOLEDみたいにするらしいのですが、今更なんですけどOLEDってLEDに有機物挟んで色だしてるのではと疑問に思ったのですが、量子ドットも使わずどうやって色出せるのでしょうか?てかむしろわざわざRGB分けずマイクロBのみで量子ドットでなぜやらないんだろ?
話は少し変わりますが液晶パネルの違いのまとめって所に初めに書いたマイクロLEDやOLED、タンデムOLED、レンズについてとか追加されるでしょうか?毎回ディスプレイの紹介とかにdisplayHDRとかも含め書いてくれてるのですがまとめてあると嬉しいです
ありがとうございます。
ランニングコストもご教示いただけると
初心者は参考になります。
ほぼパソコンの電気代が占めてます。
【シミュレーション例】
・土日にじっくり生成(16時間)
・RTX 5090(575W)
・CPU+マザボ+メモリ+SSD(80W)
・電源ユニットの変換率(90%)
= 月間1813円くらい(東京電力)
= 月間1275円くらい(関西電力)
= 月間1194円くらい(九州電力)
こんなところでしょうか。
有名なサブスクAI「Veo3」ですと、無制限の生成プランが月額36400円らしいので、大量に生成する人ほどローカル版がコスパ良し。・・・というか、サブスクAIは検閲されててNSFWが無理らしいので、結局ローカル版しかマトモな選択肢が無いのが実情かな。
初めてのAI用PCとして「VELUGA-D A70S G6」を考えているのですが、AMDはやめておいたほうがいいのでしょうか?
Radeon AI PRO R9700はLLM向けです。画像や動画はかなりクセが強いと言うか、適切に扱うには相当のスキルが要求されますし、仮に適切に扱えたとして価格に見合う性能を出せるか不透明です。
現在RAMが64GBなのですが安いoptane 16gbを2枚増設して共有メモリ先に設定すれば漏れても安心かなと考えたのですが可能でしょうか?
まるで身代わり防壁みたいな使い方ですね。
Optane Memoryの使い方として間違ってないのですが、そもそも共有メモリ(SSD)が遅すぎる問題があって、時間を待てるならアリだと思います。
検証お疲れ様です!
AI初心者向けの設定周りの解説記事も出して欲しいです
nsfwな動画作ろうとしても5秒は短すぎるなあ
5秒の動画を綺麗に繋げて連続で生成できりゃいいのに
ぼくの場合は
・5秒作る
・最終1~2フレームを始点にまた5秒作る
・15秒くらいで画風が崩れてくるので、終点フレーム指定でいったん元に戻す5秒
・また最終1~2フレーム始点で5秒作る
・15秒で崩れるのでもとに戻す5秒
これの繰り返しで1~2分まで拡張してます。たまに質の高い中間フレームが生成されたら、そこを始点にまた5秒作らせたり、繋いで繋いで動画全体から「単調さ」を間引いて、飽きが来ないように作ってます。
5秒動画の合体はフリー編集ソフト「Aviutl」でやってます。NVEnc AV1出力なら、爆速で超高品質です。
【github】ComfyUI-SeedVR2_VideoUpscaler
【github】UI-Frame-Interpolation
【ワークフロー】Post_SeedVR2_RIFE49.zip(筆者作成)
Aviutlで完成した動画を、「SeedVR2(7b_fp16)」で1.25~1.50倍に超解像、「RIFE VFI(rife49)」で3~4倍フレーム補間で完成です。
疑問に思ったのですが、グラボ2枚構成でやったら5090以上よりもいい結果を出せたりしますか?
例えば5060と4090の2枚とかで!
一応、「ComfyUI MultiGPU」ノードで実験しました。
・5090+4090は設定を詰めれば5090単品より速くできる、かも。
・5090+5070はかなり色々と試したけど、5090単品と互角が限界でした。
結局、サブGPUのVRAMにデータを取りに行く経路がPCIeインターフェイスだから、VRAMがいくら速くても効果が出づらいようです。
あと、普通のマザーボードはグラボを2枚挿し込んだときにPCIe x8 / x8に分割されてしまい、使える帯域幅が半減します。
RTX 4090以上のグラボなら単品が効率いいと感じます。
VRAMが少ないグラボでQ8やfp8_scaledなど大きなモデルをなんとか動かすためのシステムですね。MultiGPUノードの作者も、そういった使い方を想定してるようで、すでに余裕のあるハイエンドをさらに高速化するのは趣旨じゃないそうです。
検証更新お疲れ様です。
画像生成だと比較的まともだったArcが動画生成だとRadeon未満の速度になるのが不思議ですね。
要因がPCIeであれば、予想されているB770がVRAM16GB・PCIe 5.0 x16らしいのである程度まともに動くかもしれません。
非常に大変だと思いますが、モデルをQ6からQ2にして検証したらどうなるんでしょうかね?
> モデルをQ6からQ2にして検証したらどうなるんでしょうかね?
初期公開版がまさにVRAMに合わせてモデルを変更する方式でしたが、あまり評判が良くなかったので、ほどほどに品質が高い「Q6」で固定しました。
それにQ2~Q3クラスは実験的な品質ですし。
私はA750でQ3・Q4あたりを使い、実用的な時間で480pクラスでも生成できています。
(今回のベンチマークとは条件が違う部分もあるため、比較はしづらいですが)
性能的に上なはずのA770・B580ならQ6といえど、ここまで問題外という結果にはならなそうなのですが。
VRAM比率のオプションが効かなかったとのことですが、私の環境では–novramも–lowvramもちゃんと機能しており(あり・なしで挙動が明らかに変わっています)、その辺の違いが出ちゃってるのでしょうか。
うお!?前のも参考になったけど、今回もすごい記事の充足度変わってる
–novram付ければVRAM12GB以下のグラボでも720p解像度で生成できませんか?
条件は違いますが、上のコメントでこのオプションを付けてB570で動かしている方がいますし
自分が試した範囲ですが、現状ではggufのカスタムノードは「–novram」オプションを受け付けてないように見えます。ComfyUI本体のローダーなら「–novram」も効くみたいですが、こちらはggufのロードはできません。もどかしいところです。
novramオプションは名前の通りvramにモデルデータを溜めない筈、演算キャッシュとして利用ならvram量は少なくていいけど使うデータもモデルも全部dramから持ってくるし戻す=dram速度に律速されるのでAPU的な速度に留まりそう。
ちなみにミニPCでやっててComfyUIが360pでも1it/sより良いことなんてまずない程度ですからね?、5秒81フレームだと時間単位掛かる速度まで落ちます。
実際に生成してみるとわかりますが、novramでのオーバーヘッドは(現状の)動画生成の推論時間に比べると割と小さいのでさすがにAPUほどは遅くならないです。とはいえ10~20%(たとえば300秒掛かっていたのが345秒)くらいには落ちてしまいますので、この落ち込みを「使えない」とするかは人によって分かれそうです。
(動画貼り付けダメだったら消してください)
猫のYMO「腕を胸の前に上げて痙攣の運動!」
https://litter.catbox.moe/cl4oyr8wnlmx5hwx.mp4
最後の晩餐がラーメン
https://litter.catbox.moe/5u5tvqy29lnemvf5.mp4
I2V 5秒動画 RTX5090 RAM128GBで150秒程度
動画生成にまだ手を出していないのですが、CPU9800X3Dでグラボ5070ti、メモリ64GB(32GB*2)であればNSFW含めてある程度対応可能なものでしょうか。。。?
十分なスペックです。
省メモリ特化なKijai版をベースに作ってある「EasyWan22」なら、メモリ64 GBでも基本的に問題ないです。
それこそ、このベンチマークを見れば判断できるでしょう。
最高ではないけど十分なスペックでは?
検証情報ありがとうございます。私はAIは画像生成くらいしかしていませんが最近電気代が気になって3080TIから5070に変えようか検討していました。ゲームはともかく生成AI性能に関しては2世代変わっても微妙な性能なんですね。
FP4対応の生成モデル(Nunchaku版)が出てこないと、RTX 50シリーズの真価はまだ発揮できないですね。
一応、Qwen Image(静止画)などでFP4版が出てて、たった25秒で8ステップ処理できるなんて報告が出てきてます。Wan2.2もFP4版リリースされないかな・・・。
検証大変お疲れ様です。
IntelArcは相性最悪でB580は脱落だったのですね。A770が辛うじて使えた程度でしたか。
もうAIを使うためのGPUは結局NVIDIAが独占しているようなものですね。まぁ、そもそもNVIDIAのGeForceを想定してソフトが作られていますし、当然ではありました。
結局は5090以外ではまともに扱えない代物……お金が飛びますね……
今後、下位モデルでもVRAMが増えるSUPERシリーズでどれだけ実用性が増えるのか、5070TiSUPERなら少しは使えるでしょうか。
他、AI用にカスタマイズされたB60やR9700やらは入手難で一般人が持てるものではありませんね。
単に動画生成が目的ならテンプレートのワークフローのモデルローダーをカスタムノード(たとえばComfyUI-GGUFやcity96氏のggufなど)のggufローダーに変更するだけで十分ARCでも生成はできますよ。どうしても「torch.compile」や「sageatten」を使いたいなら話は変わってきますが・・・。
検証ありがとうございます。前回8月初版の記事から大変参考にさせていただいております。
現在、intel第14世代Core、DDR4-3200 128GB、PCIe 4.0の環境でRTX 5090を使っています。こちらの記事を読んで「PCIe 5.0環境に移行しようかなあ、でもDDR4メモリを有効活用したいなあ」ということで今年発売されたGIGABYTE B760 GAMING X DDR4 GEN5という低価格マザボが気になったりしていました。
しかし記事中のDDR4-3200(33.6 GB/s)、PCIe 4.0(32.0 GB/s)、5.0(64.0 GB/s)それぞれの速度表記を見て、その移行では意味ないことに気が付きました。
DDR5 & PCIe 5.0に移行するのであればCPUから変えたいですし、移行したとしても動画生成は10%前後くらいしか速くならないようなので、もうしばらくは今の環境のまま使おうと思います。
> 移行しても10%程度
コスパを考えると、そのままの環境でまったく問題ないと思います。
これから新規にパソコンを買ったり、1から自作するなら、PCIe Gen5対応プラットフォームが良いだけです。
この質問をしたのは私なのですが、記事中の以下帯域幅の数値について、
・DDR5-5600 69.2 GB/s
・DDR4-3200 33.6 GB/s
それぞれデュアルチャネルとして以下の誤りではないでしょうか?
・DDR5-5600 = PC5-44800 89.6GB/s ※44800×2÷1000
・DDR4-3200 = PC4-25600 51.2GB/s ※25600×2÷1000
3090が10万円で購入できるとしても、今から買うのは微妙でしょうか。
(今出回っているような中古3090は大抵マイニング落ちだからヤバそうという話は置いておくとして)
もう3万円積んでも5070Tiのがいいですかね…?
それなら3070Ti SUPERが出るのを待って…と、いつまで経っても買えないパターンですが。
お二方ともご意見ありがとうございます!
低電圧化やバラしてグリス塗り直し&熱伝導シート貼り直しは何度か経験があるので、3090の掘り出し物があったら検討してみます。
5070Ti SUPERが安価に出てくれればそれが一番なのですが…。
やかもちさんのコメントを拝見して、私自身もバックプレートへのヒートシンク取り付けとMSI AfterburnerによるPower Limit制御で、なんとかVRAM/ホットスポット温度を100度前後に抑えていたことを思い出しました。
ケースファン追加だけでなく、ケースを開けて扇風機を当てたりしている人もいましたね。
メーカーと製品、個体によっても対策の要否は違うと思いますが、4090や5090以上に玄人向けの製品だと思いますので覚悟したうえで検討されたほうがよいと思います。
仮に10万円ですと、コスパが約2.3~2.4に跳ね上がり、なかなか悪くない選択肢です。
ですが先にコメントされている方も言うとおり、マイニング落ちで経年劣化が最大の懸念点です。バックプレートにヒートシンクを取り付けて、別途ケースファンでアクティブ冷却をするなど、きちんと温度管理しないとVRAM起因の故障が不安です。
しいて言うなら、今後来るとウワサされてるSUPER版までの「つなぎ」としては悪くないかもですね。SUPERを買った後に残った3090をまたフリマで売ってしまえばいいので。
3090は所有していましたがお薦めはしないです。
・マイニング利用率の高さ:ご自身でもご認識ですが、マイニングブームの時でしたので個人でもマイニング利用していた人はかなり多かったと思います。マイニングしていたからといって必ず性能が低下するわけではありませんが、品質に少なくない影響はあると思います。
・発熱の凄さ:チップの発熱は普通ですがGDDR6Xがあっという間に100度を超えてしまうため全体としての温度管理が大変でした。4090や5090はそんなことないのですが。
・性能の微妙さ:4090や5090と違い、3080Tiと数%の性能差しかなくVARM24GBにしか魅力がありません。
今でも中古ショップでは12~13万円が相場だと思われ、それより安くてもオクやフリマでの購入はリスクに見合わないと思います。
どうしてもVRAM 24GBが必要で、信頼できる人から素性の良いモノを譲ってもらえるのであればアリかもしれませんが。
5070Ti Superまでの繋ぎとしてであれば、稀にパーツショップで新品30万円ほどで入荷される4090をSNSで探したほうがよいのではないかと思ったりします。おそらく1年後も同程度の価格で売却できると思うので。
XPU環境でワークフローを入れてベンチしようとしたのですが、Sage attention云々でエラーになります。(ワークフローを見るとWanVideo Model Loaderのattention_modeがsageattnになってますね)
Arcでベンチした際は別のワークフローを使われていましたか?
もう試されたかもしれませんが、「WanVideo Model Loader」の「sageatten」を「SDPA」に変更した方がいいと思います。自分の試した環境だと更に変更が必要で「torch.compileノード」はパススルーに、「WanVideo Model Loader」の「base_precision」を「bf16」にしないと完走しないです。ちなみにARC B580なら学習モデルを「Q2_K.gguf」に変更すればギリVRAMに収まりそうです。私のB570では若干足りていない様子でした。「torch.compile」はGeForceの場合CUDAのランタイムC++コンパイラが動いてくれますが、XPU環境なら別でC++コンパイラの導入が必要のようです。なので私はパススルーにしています。
ベンチ用のワークフロー(2_Wan22_480p_Benchmark)で2つ質問させてください
1. テキストエンコーダーでumt5_xxl_fp8_e4m3fn_scaledだとエラーが出ます
カスタムノードがscaledに対応していないらしく(?)scaledのついていないTEを別途DLしたら動いたのですが、scaledで動かすにはどうすればいいでしょうか?
2. lightx2v_14B_T2V_cfg_step_distill_lora_adaptive_rank_quantile_0.15_bf16について
I2V用ではなくT2V用のLoRAだと思いますが、これをlowにだけ適用するのは何か特別な効果があるのでしょうか?(生成自体は問題なく行えてます)
1.
これは・・・配布してるワークフローのミスでした。
ベンチ用に生成した残骸からワークフローを開いたところ、すべて「scaledがついていない版」でした。
なので、scaledがついてない方で大丈夫です。配布ワークフローは後ほど修正します。
2.
T2V用を使っているのは筆者の完全な好みです。両方ともI2V用だと動きが好みに合わなかったので、kijaiさんが作ったT2V用を使っています。
高速化LoRAも多種多様で生成結果にかなり影響があります。いろいろと試してみて、もっと好みに合うLoRAがあれば、そちらを使ってもらって大丈夫です。
配布ワークフローを修正されるとのことなので、細かくて恐縮ですがついでにご指摘します。
「各モデルのURL一覧」について、
・Diffusion Model:ファイル名、リンク先がI2VではなくT2Vになっています。
・File save location:diffusion_models/ に配置するよう記載されていますが、「Model Load」の初期状態では diffusion_models/Wan22_I2V/ に配置されている想定になっています。
やかもちさん返信ありがとうございます。
確かに動画の高速化LoRAは癖を強さを感じますね。
両方I2V用のLoRAだと各4step/cfg 1.5位位まで上げると良い感じですが、
やかもちさんのWFでT2V用LoRA使った方が動画でキャラが痙攣してしまう発生率が低い気がしました。
(サンプラーを3つ使ってるから?何にせよ発想が凄い!)
VRAMが12GBの場合ですが、ComfyUI-MultiGPUを使用するとモデルをRAMにロードして、描画だけVRAMを使用するので速度がほぼ変わらずにVRAM使用量を削減できます。
前提が不明ですが、「単一」GPUで「VRAMに収まらない」動画生成をする場合にComfyUI-MultiGPUを活用すると有用ということでしょうか?
ComfyUI-MultiGPUの本質は並列処理ではなく(MultiGPUでもノードやタスクは直列で処理される)メモリ管理の強化(DRAMやセカンダリGPUのVRAM活用)なので用途としては正しそうですね。
Blocks To Swapと似ていると思いますが、MultiGPUのほうがより細かくオフロード対象を設定できるようです。ただBlocks To Swapの方がお手軽で、通常の用途であれば必要十分な気もしますね。
3060からAIに入り、物足りなくなり
4090欲しくても高くて買えず、3060、2枚差しになる人多いんでは
詳細な情報シェア、ありがとうございます。すごく勉強になりました!
本日、私の**【Windows 11 (RAM 64GB, RTX 4060 Ti 16GB)】**環境でテストを試みましたが、残念ながら、先生と同じ結果を得ることができませんでした。
先生のワークフローのパラメーターは**一切変更しておりません**。
また、ご指摘の通りモデルのロード時間短縮のため、最初に**「0_Wan22_Model_PreLoader.json」**を実行してから次のステップに進む手順も踏みました。
しかし、私の状況では:
1. まず **720P** の実行が不可能で、**OOM (メモリ不足)** のエラーが発生しました。
2. **480P** のテストにおいても、「0_Wan22_Model_PreLoader.json」を実行した後に「2_Wan22_480p_Benchmark.json」を実行しようとすると、**やはり OOM となってしまいます**。
3. 最終的に、「2_Wan22_480p_Benchmark.json」を直接実行し、**2時間32分**かけて完了させましたが、生成されたデータは、**先生が示された結果と大きくかけ離れたもの**となりました。
(From export csv : execution_time2025_9_28.csv
…
“200”,”WanVideo Sampler”,”2847.95s”,”23.47s”,”+2824.48s / +12035.47%”,”73.57 MB”
…
“27”,”WanVideo Sampler”,”1748.56s”,””,””,”44.86 MB”
…
“90”,”WanVideo Sampler”,”4514.82s”,””,””,”73.57 MB”
“28”,”VAE分割デコード(Decord)”,”14.90s”,””,””,”3.68 GB”
…
“Max”,””,”4514.82s”,””,””,”6.51 GB”
“Total”,””,”9151.13s”,”37.93s”,”+9113.20s / +24025.09%”,””
)
つきましては、私の操作に何か間違いがあったのか、あるいは他に原因があるのか、ご助言を頂けますでしょうか。
実験前には必ず**PCを再起動**し、ComfyUIに必要なもの以外は**極力他のソフトウェアを起動しない**よう、システムリソースの占有にも努めておりました。もしお気づきの点がございましたら、ご指摘いただけると幸いです。
また、ComfyUIのバックエンド実行記録とLOGも記録しておりますので、もし必要であれば、そちらもお送りできます。
重ねて、貴重な情報のご提供に感謝申し上げます。
私は台湾人なので、日本語が不慣れなため、翻訳ソフトを使って文章を作成しました。
もし不自然な表現がありましたら、大変申し訳ございませんが、ご容赦いただけますと幸いです。
検証ありがとうございます!
自分の7800XTでは無理だと思い知らされました!
なんど試してもSimpleMathlnr+、SimpleMathFloat+といったノードが見つかりませんと注意書きが出てしまいます。comfyUI_essentials(1.1.0)内には含まれているはずなんですが….
私も同じ問題を抱えていましたが、解決策は手動でcomfyui essentials githubにアクセスし、そこからノードをダウンロードして貼り付けることでした。
何らかの理由で、comfyui managerはこれらのノードをインストールしません。
ベンチマークを試そうと思ったら、画像を読み込ませているにも関わらず、画像が存在しないというエラーが出て使えなかったので質問します。Cドライブ以外にEasyWan22などのフォルダを置くと処理が遅くなったりするのでしょうか?
[…] 以下は、公開されているベンチマーク(出典:ちもろぐ, jisaku.com)を参考に、各グラボの性能の目安をまとめた比較表です。 […]
いつも楽しく読ませて頂いてます。
RTX PRO 6000 Black Well をレビューする予定は御座いますか?
画像生成と動画生成でどのくらい変わるのか知りたいのですが、参考になる文献が少ないので、やかもちさんのブログで見れたら嬉しいな・・・と思いまして。
480p または 360p のベンチマークを実行すると、再コンパイル制限エラーが発生します。何が起こっているのか理解できずに困っています。このエラーが発生し、タイマーは動き続けるものの、最初の WanVideo Sampler ノードを通過しません。構成は Ryzen 5600、RAM 32GB、RTX 3060 12G です。助けていただけないでしょうか?ありがとうございます!
(言語エラーがありましたらご容赦ください。翻訳を使用しています。)
1112 12:18:12.681000 24552 Lib\site-packages\torch\_dynamo\convert_frame.py:1016] [2/128] torch._dynamo hit config.recompile_limit (128)
W1112 12:18:12.681000 24552 Lib\site-packages\torch\_dynamo\convert_frame.py:1016] [2/128] function: ‘forward’ (L:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-WanVideoWrapper\gguf\gguf.py:115)
W1112 12:18:12.681000 24552 Lib\site-packages\torch\_dynamo\convert_frame.py:1016] [2/128] last reason: 2/127: tensor ‘self._parameters[‘bias’]’ size mismatch at index 0. expected 5120, actual 13824. Guard failed on a parameter, consider using torch._dynamo.config.force_parameter_static_shapes = False to allow dynamism on parameters.
スワップブロックを増やしたらなんとか動くようになりました。どうやら32GBのRAMでは360pが限界のようです。スワップブロックを最大にしても、共有メモリが1GBを超えてしまいます。64GBのRAMを買うべきでした。本当にありがとうございます。とても詳細なテストですね。
詳細な検証情報ありがとうございます。
掲載いただいているワークフローやベンチマーク結果のおかげで、環境構築の勉強になりました。
ターゲットタイムがあることで、環境が正しい方向で動いているかの指針にもなりました。
コチラの記事で当時メモリを128GBにして今どれだけ救われた事か。。
ありがとうございます